青少年编程
rviz
关联数组
macos
实时音视频
mount
默认内存对齐数
Mycat
android版本
git reset
族谱
传输层
飞机游戏
学生网页作业
启动过程
mysql 锁机制
拥塞控制
OOP
运动规划
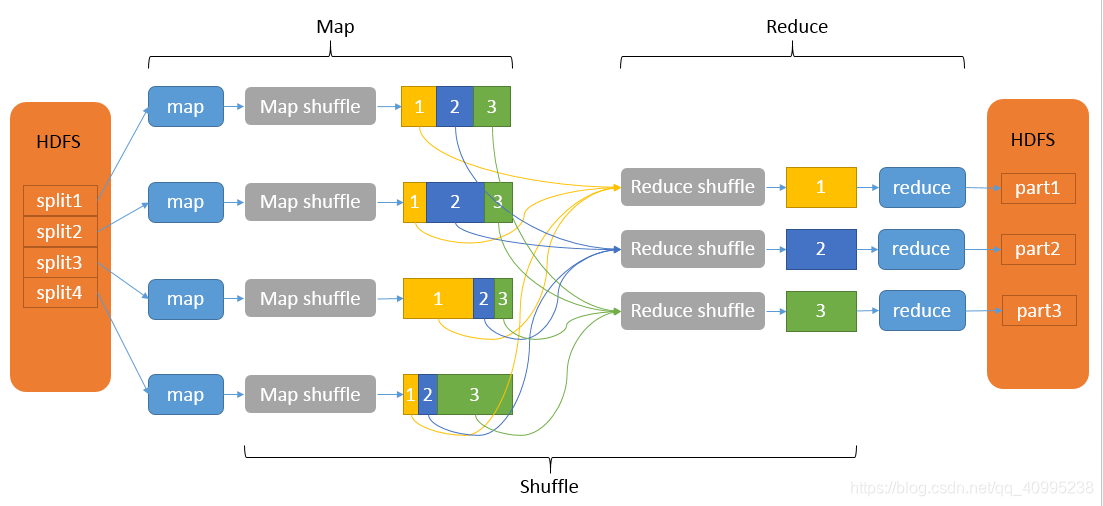
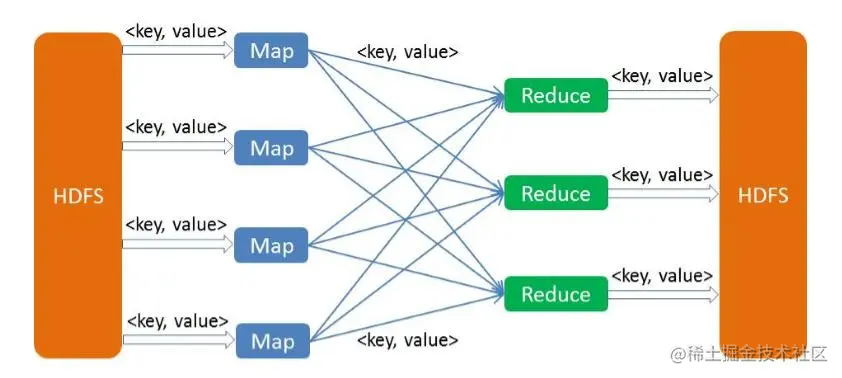
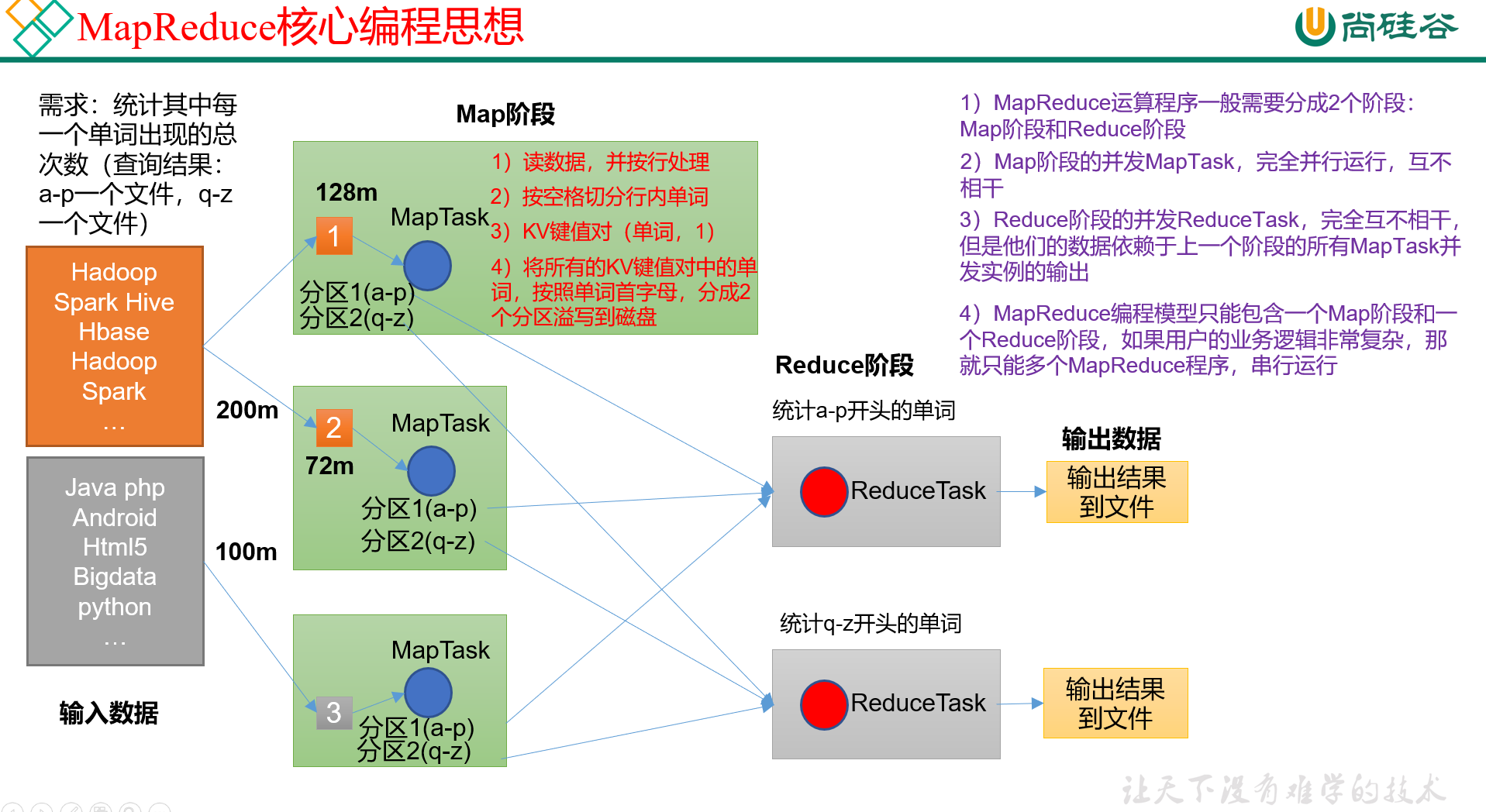
map
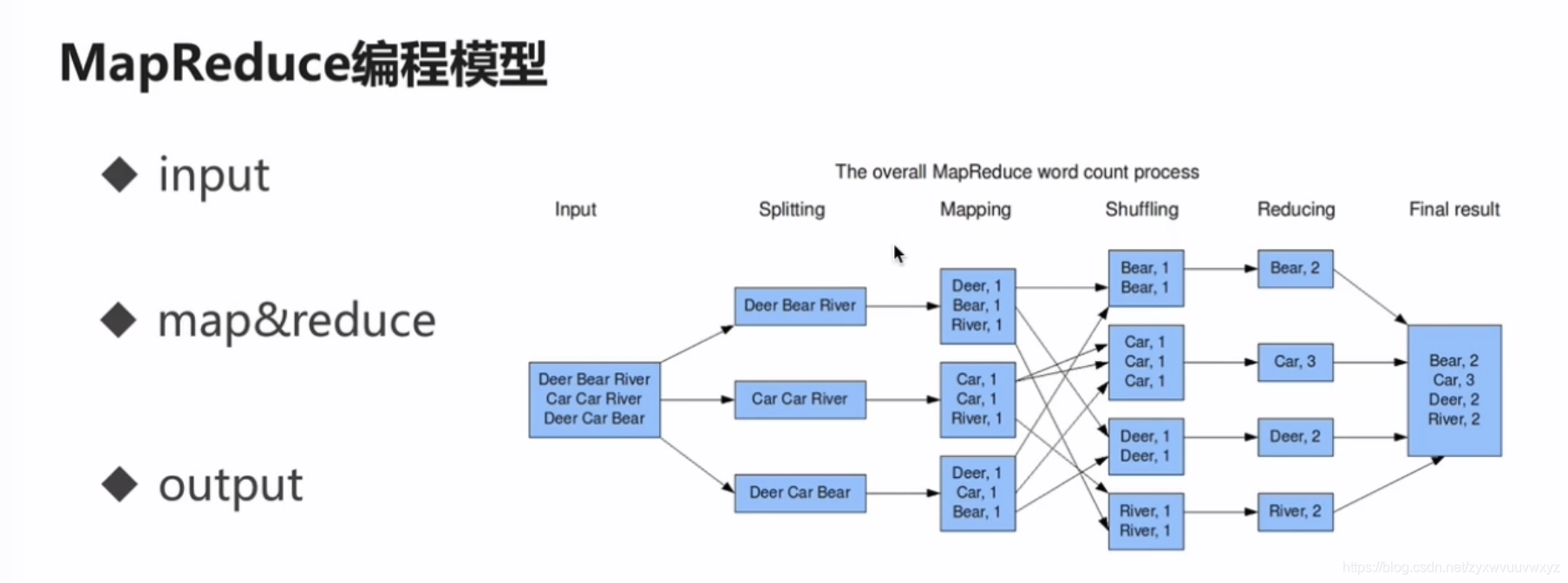
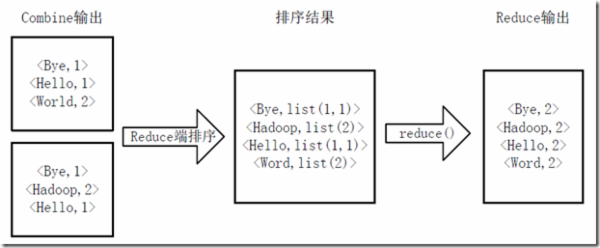
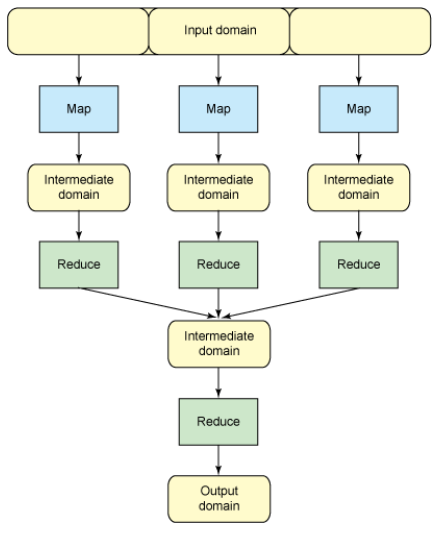
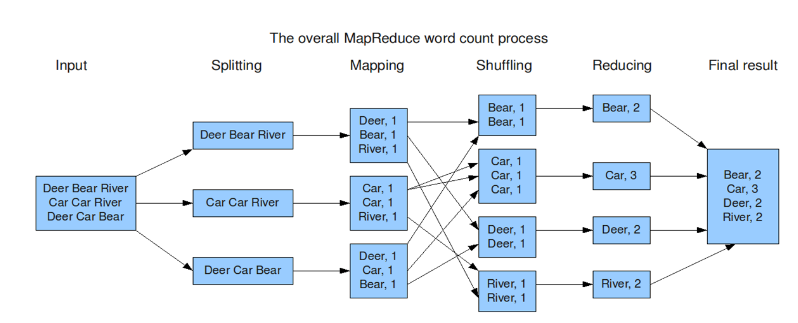
mapreduce
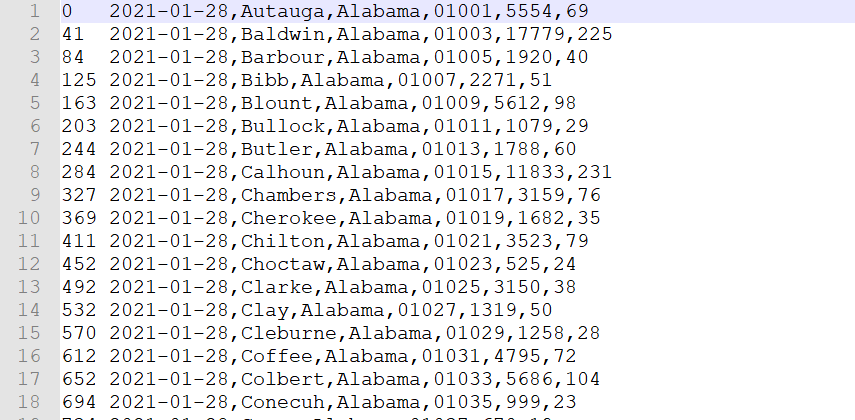
2024/4/11 15:46:21
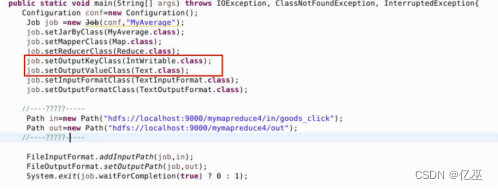
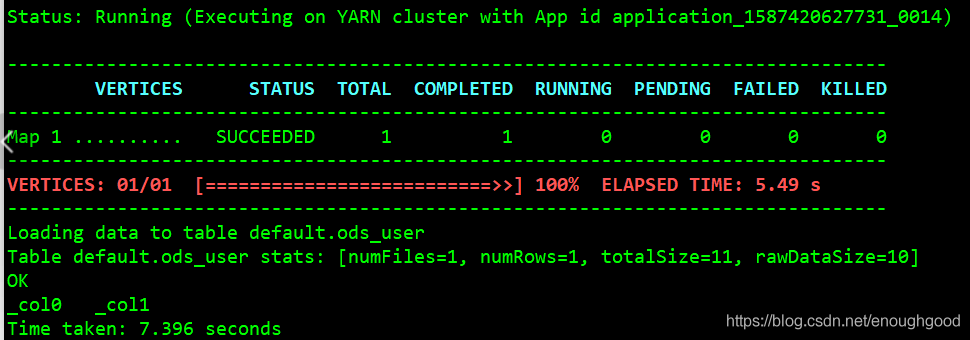
Hive是如何让MapReduce实现SQL操作的
之前我们说过了MapReduce的运算流程,整体架构方法,JobTracker与TaskTracker之间的通信协调关系等等,但是虽然我们知道了,自己只需要完成Map和Reduce 就可以完成整个MapReduce运算了,但是很多人还是习惯用sql进行数据分…

MapReduce如何让数据完成一次旅行
我们应该已经知道MapReduce不仅仅是一个分布式计算的框架,更加也是一种算法,常规的算法中,我们也可以使用这种模型去进行运算,也就是Mapper - Reducer 过程 ,但是,MapReduce还有很多看不见的过程࿰…

全方位揭秘!大数据从0到1的完美落地之MapReduce实战案例(1)
案例一: MR实战之小文件合并(自定义inputFormat)
项目准备
需求
无论hdfs还是MapReduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案 测试数据 分析
小文件的优化无…
极简的MapReduce实现
目录
1. MapReduce概述
2. 极简MapReduce内存版
3. 复杂MapReduce磁盘版
4. MapReduce思想的总结 1. MapReduce概述 以前写过一篇 MapReduce思想 ,这次再深入一点,简单实现一把单机内存的。MapReduce就是把它理解成高阶函数,需要传入map和…

使用MapReduce并行构建Lucene索引
[b][colorgreen][sizelarge]散仙前几篇博客上,已经写了单机程序使用使用hadoop的构建lucene索引,本篇呢,我们里看下如何使用MapReduce来构建索引,代码如下:
[/size][/color][/b]package com.mapreduceindex;import jav…

Hadoop基础——MapReduce
1. Hadoop序列化和反序列化及自定义bean对象实现序列化?
1) 序列化和反序列化的含义序列化是将内存中的对象转换为字节序列,以便持久化和网络传输。 反序列化就是将字节序列或者是持久化数据转换成内存中的对象。 Java的序列化是一个重量级序列化框架&a…

Chapter5 MapReduce
5.1概述
5.1.1分布式并行编程
MapReduce是一种分布式并行编程框架。 在计算机发展史上的"摩尔定律":CPU的性能每隔18个月就可以翻一番。然而,从2005年起,摩尔定律逐渐失效,因为CPU制作工艺存在上限、性能不可能无限提…
Hadoop MapReduce 调优参数
文章目录 MapReduce 调优参数详解MapReduce 调优参数一键复制 前言:
下列参数基于 hadoop v3.1.3 版本,共三台服务器,配置都为 4 核,4G 内存。
MapReduce 调优参数详解
这个参数定义了在 Reduce 阶段同时进行的拷贝操作的数量&…
MapReduce综合应用案例 — 电信数据清洗
文章目录 第1关:数据清洗 第1关:数据清洗
测试说明 平台会对你编写的代码进行测试:
评测之前先在命令行启动hadoop:start-all.sh;
点击测评后MySQL所需的数据库和表会自动创建好。
PhoneLog:封装对象 L…
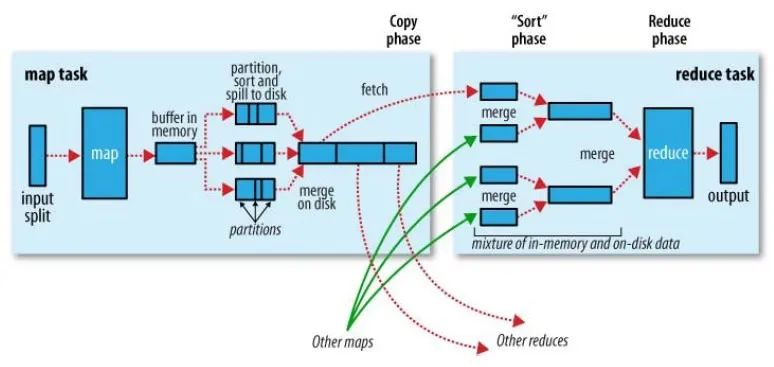
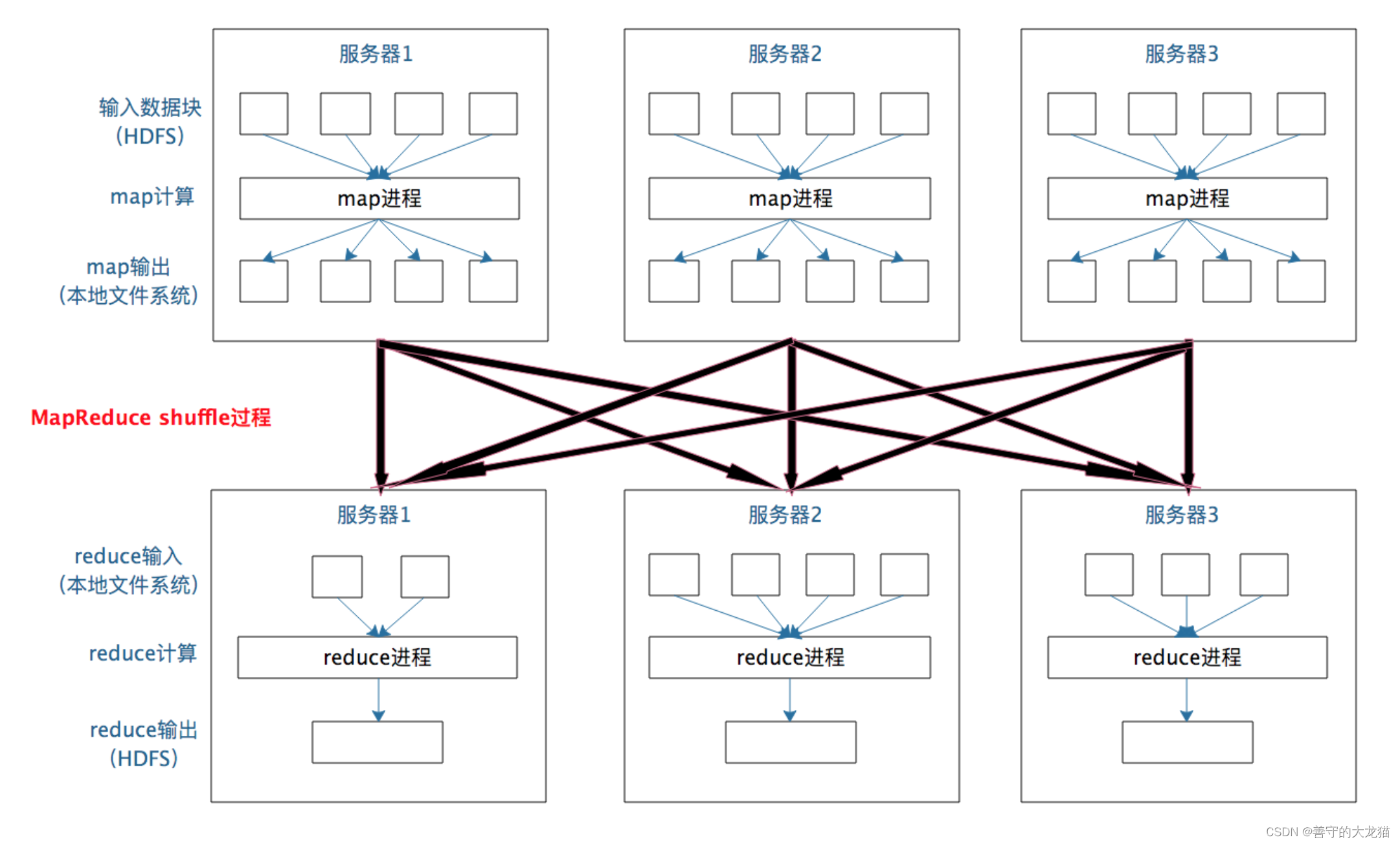
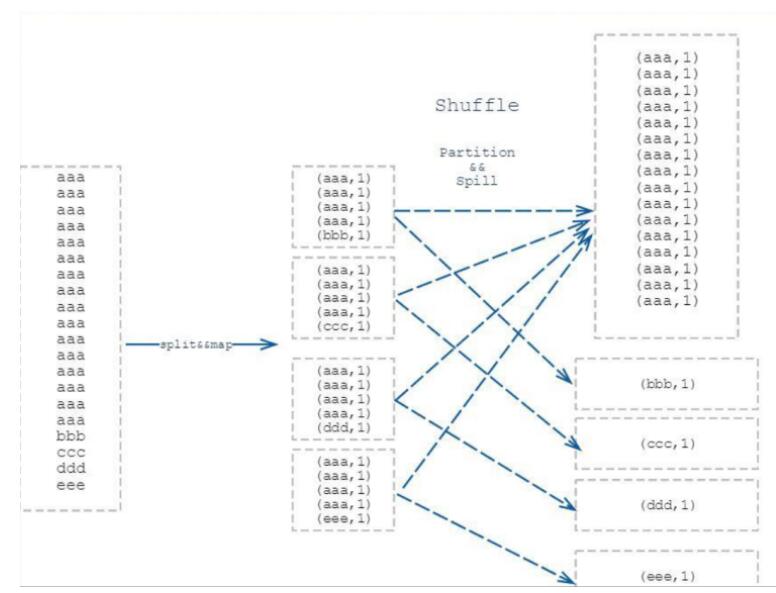
大数据面试题:请描述MapReduce中shuffle阶段的工作流程,如何优化shuffle阶段?
map阶段处理的数据如何传递给reduce阶段,是MapReduce框架中最关键的一个流程,这个流程就叫shuffle。
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,合并)。 shuffle是Mapreduce的核心&…
如何将Lucene索引写入Hadoop2.x?
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2090121[/url]
[/size][/color][/b]
[b][colorolive][sizelarge]散仙,在上篇文章,已经写了如何将Lucene索引写入Had…

大数据可能是一场骗局
编者按:本文作者冯大辉,丁香园CTO,雷锋网特约撰稿人,想要联系的读者可以在微波Fenng。 几乎每天都能看到有人在谈论大数据,让人好生厌烦。什么是大数据(Big Data) ? 简单一点可以理解为超出传统数据管理工具处理能力的…
2024.1.10 SparkSQL ,函数分类, Spark on HIVE,底层执行流程
目录
一 . 开窗函数
二 . SparkSQL函数定义 1. HIVE_SQL用户自定义函数 2.Spark原生UDF 3. pandasUDF 4. pandasUDAF
三. Spark on HIVE
四.SparkSQL的执行流程 一 . 开窗函数 分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx]) 分析函…
Hadoop环境的基准测试----自己电脑搭虚拟机的话就别测了,我电脑的主板差点烧了。
写文件测试
[userNewBieMaster sbin]$ hadoop jar /home/user/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 8MB
2021-07-03 15:28:52,823 INFO fs.TestDFSIO: TestDFSIO.1.8
2021-07-03 …
数据分析系列 之python中输入输出和函数编程
1 输入输出: 1.1 概述 输入函数input xinput([‘输入信息’]) 返回值为str 输出语句print(对象1,…对象n,seq’ ‘,end’\n’) 1.2 举例 如何输入获得两个字符串?(若输入abc def或者abc,def)
x,y input(Input:).split()
#换行符…

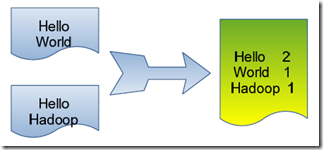
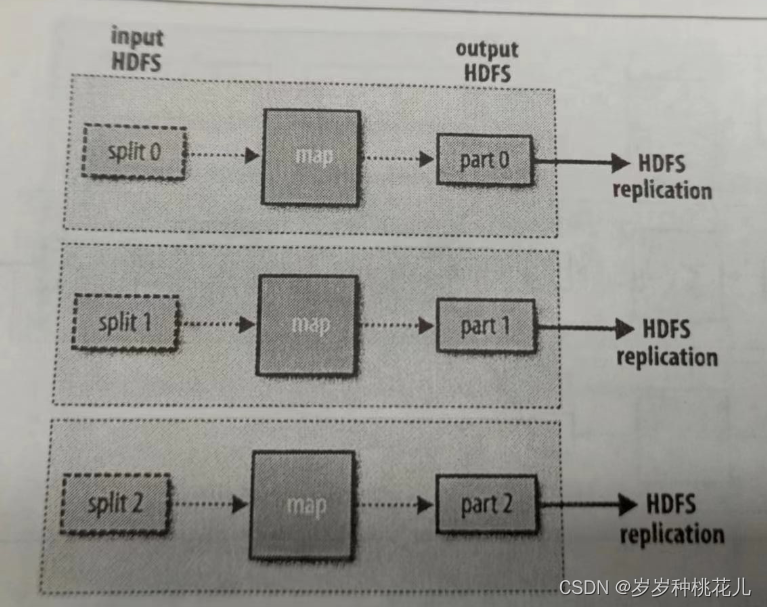
Hadoop之运行wordcount
MapReduce map,映射;reduce,化简。
MapReduce处理大数据集的过程如下图所示 每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map…

MapReduce阶段的排序
MapReduce阶段的排序
map阶段:全排序、二次排序、部分排序 二次排序实现:对map端输出的key进行排序,实现compareTo方法。在compareTo方法中排序条件有两个。 reduce阶段:分组排序

Hadoop_MapReduce_WritableComparable排序
目录
1.排序分类
2.自定义排序WritableComparable原理分析
3.WritableComparable排序案例实操(全排序)
1)需求 2)需求分析 3)代码实现
4.WritableComparable排序案例实操(二次排序)
1&…

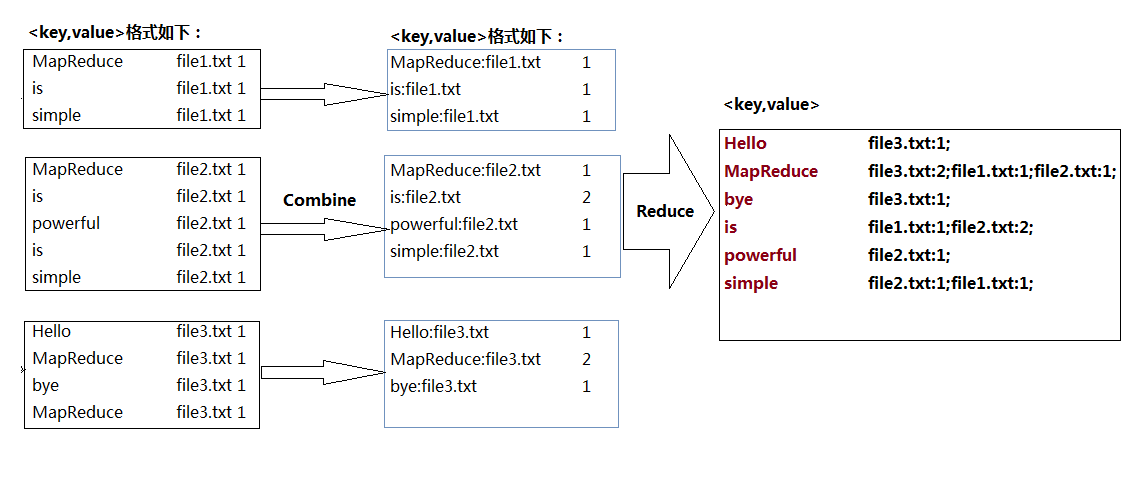
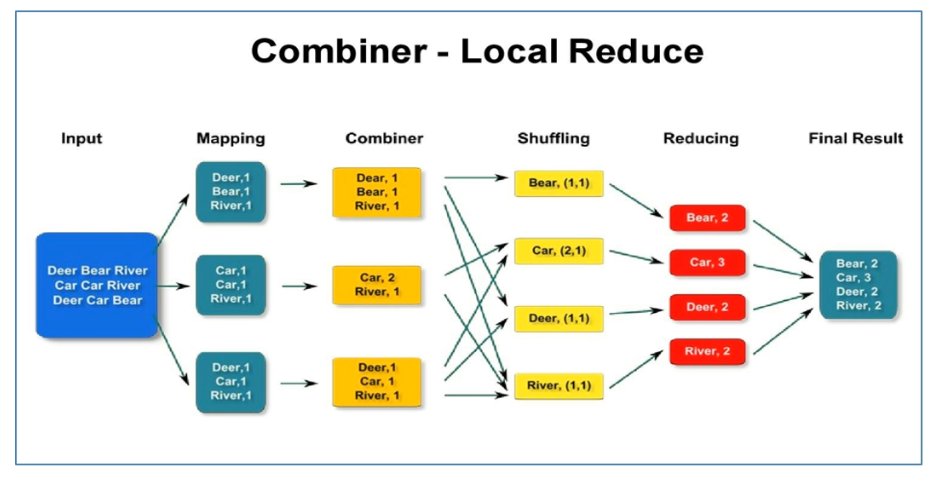
Hadoop_MapReduce_Combiner合并
目录
1.自定义Combiner实现步骤
2.Combiner合并案例实操
1)需求
2)需求分析
3)案例实操-方案一
4)案例实操-方案二 1.自定义Combiner实现步骤
(a)自定义一个Combiner继承Reducer,重写Re…

彷徨 | MapReduce各种执行(Linux执行,eclipse执行)与读取和存储(从HDFS读取以及从本地读取)
1 . 读取HDFS中的文件 , 利用Linux平台MapReduce框架执行 , 结果写入 HDFS中 .
map
package hadoop_day05.zhang.firstMR;import java.io.IOException;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Tex…

Google的十个核心技术
本篇将主要介绍Google的十个核心技术,而且可以分为四大类: 1.分布式基础设施:GFS,Chubby和Protocol Buffer。 2.分布式大规模数据处理:MapReduce和Sawzall。 3.分布式数据库技术:BigTable和数据库Sharding。…
实验六 MapReduce数据清洗-气象数据清洗
实验六 MapReduce数据清洗-气象数据清洗第1关:数据清洗任务描述编程要求测试说明代码实现命令行代码文件step1/com/Weather.javastep1/com/WeatherMap.javastep1/com/WeatherReduce.javastep1/com/Auto.javastep1/com/WeatherTest.java第1关:数据清洗
任…
【大数据分布并行处理】单元测试(五)
文章目录 第五单元单选题多选题判断题填空题 第五单元
单选题 下列说法正确的是? A. HDFS HA可用性不好 B. 第二名称节点是热备份 C. 第二名称节点无法解决单点故障问题 D. HDFS HA可以实现可扩展性、系统性能和隔离性 正确答案: C HDFS Federation设计…
hadoop学习:mapreduce入门案例四:partitioner 和 combiner
先简单介绍一下partitioner 和 combiner
Partitioner类
用于在Map端对key进行分区 默认使用的是HashPartitioner 获取key的哈希值使用key的哈希值对Reduce任务数求模决定每条记录应该送到哪个Reducer处理自定义Partitioner 继承抽象类Partitioner,重写getPartiti…

彷徨 | MapReduce实例一 | 判断线段的共同点个数
判断线段的共同点个数,及求一个点上经过该点的线段的个数,有俩条及俩条以上的线段经过该点,就有共同点
数据模型: 分别表示起点和终点
1,4
2,5
3,4
2,5
2,4
3,4
2,6
1,4
4,7
5,8
5,9
6,11
7,12
a,b
6,10
10,15
11,16
12,18
13,17
方法一:
package hadoop_day06.zhang.line;…
Hadoop之wordcount源码分析和MapReduce流程分析
分析wordcount的源代码,研究MapReduce的运行过程和数据流向。 wordcount源代码 import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Int…
大数据处理技术:MapReduce案例WordCount遇到的问题
在第一次接触大数据处理技术时,跟着老师的步骤写了一个MapReduce程序的统计单词案例,由于能力有限,一开始在hadoop集群上运行时就遇到了各种问题,所幸后面再老师和同学帮助下都一一解决了
MapReduce编程
MapReduce编写程序的步…
解决运行MapReduce作业时报错类找不到
背景
今天在学习HBase和MapReduce的结合时,作业打包运行会报错第三方类找不到,而我作业jar包里却有这个类
解决方法
需要修改hadoop-env.cmd文件,把所需第三方类的jar放到HADOOP_CLASSPATH环境变量里。
比如要添加hbase相关的jar包&#…
MapReduce优化
1MapReduce 跑的慢的原因
系统资源限制:内存、CPUI/O问题 小文件太多超大文件不能切片Map和Reduce参数设置不合理Map运行太长,Reduce等待太久溢写次数太多merge合并次数太多
2 MapReduce优化方法
MapReduce优化方法主要从六个方面考虑:数…
Hadoop 3.x(MapReduce)----【MapReduce 框架原理 三】
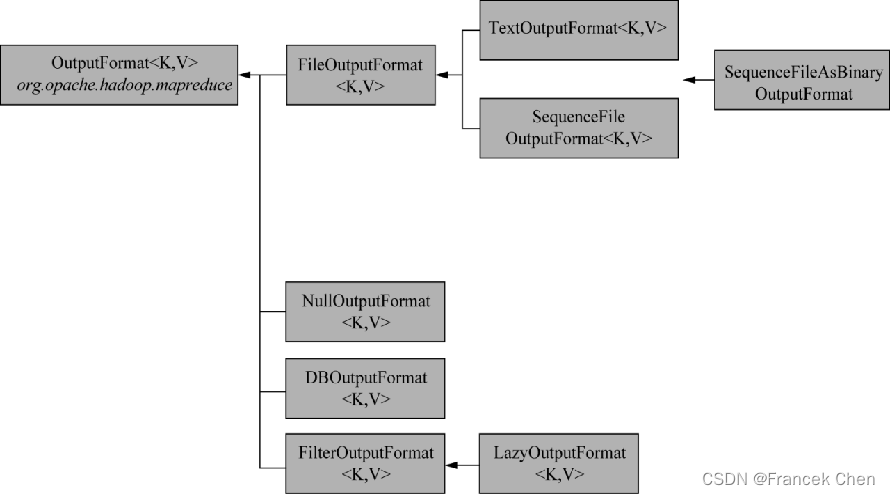
Hadoop 3.x(MapReduce)----【MapReduce 框架原理 三】1. OutputFormat接口实现类2. 自定义OutputFormat案例实操1. 需求2. 需求分析3. 案例实操4. 测试输出结果1. OutputFormat接口实现类
OutputFormat 是 MapReduce 输出的基类,所有实现 Ma…


如何给Apache Pig自定义UDF函数?
近日由于工作所需,需要使用到Pig来分析线上的搜索日志数据,散仙本打算使用hive来分析的,但由于种种原因,没有用成,而Pig(pig0.12-cdh)散仙一直没有接触过,所以只能临阵磨枪了&#x…
Win7上eclipse无插件提交Hadoop2.2分布式作业
[colorgreen][sizelarge]一直以来,都以为,想在Win上提交hadoop集群的作业,必须得在eclipse上安装hadoop-eclipse-plugin插件才可以提交,但最近与同事交流,发现其实,不一定必须安装hadoop的eclipse插件&…
记一次hadoop磁盘空间满的异常
[b][colorgreen][sizelarge]本事故,发生在测试的环境上,虽然不是线上的环境,但也是一次比较有价值的事故。起因:公司里有hadoop的集群,用来跑建索引,PHP使用人员,调用建索引的程序时,…

HDFS、MapReduce原理--学习笔记
1.Hadoop框架
1.1框架与Hadoop架构简介
(1)广义解释 从广义上来说,随着大数据开发技术的快速发展与逐步成熟,在行业里,Hadoop可以泛指为:Hadoop生态圈。 也就是说,Hadoop指的是大数据生态圈整…

Hadoop MapReduce -wordcount学习
(一)MapReduce简单介绍
MapReduce是一种分布式的计算模型,主要用于搜索领域,解决海量数据的计算问题它主要由两个阶段组成:Map和Reduce,用户只要实现map()和reduce()两个函数,就可以实现分布式…
数据库知识:备份、容灾、集群、负载均衡
一、什么是备份 【备份】是把数据拷贝一份,在其他介质保存。 当数据丢失了,有备份可以用于恢复。无论是手动/自动,有副本就相当于完成了备份。 至于能否恢复,恢复得是否完整,属于【容灾】的范畴。 备份分为两种&#x…
Hadoop,Hive和Spark大数据框架的联系和区别
Hadoop,Hive和Spark是大数据相关工作中最常用的三种框架。
1 Hadoop hadoop是一个分布式计算框架,是大数据处理的基石,大多其他框架都是以hadoop为基础。Hadoop主要包括两个方面,分别是分布式存储框架(HDFS࿰…

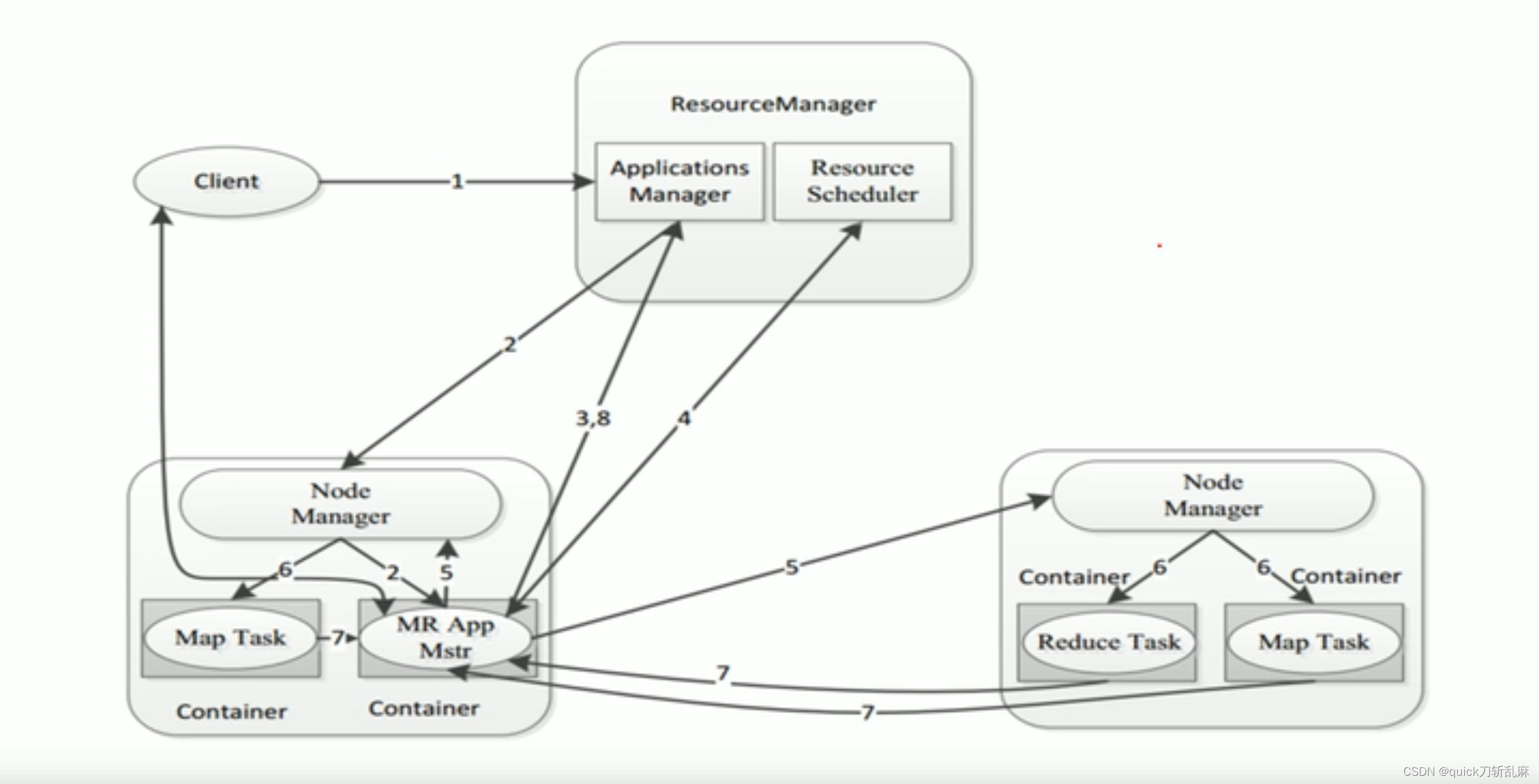
MapReduce:作业运行机制
目录
作业提交
作业初始化
任务分配
任务执行
关于进度监控
作业完成 MapReduce应用实际上是以YARN应用运行,若理解了YARN运行机制,MR不过是多了一些细节处理
MapReduce作业运行的整个过程中有5个独立的实体:
客户端:调用…
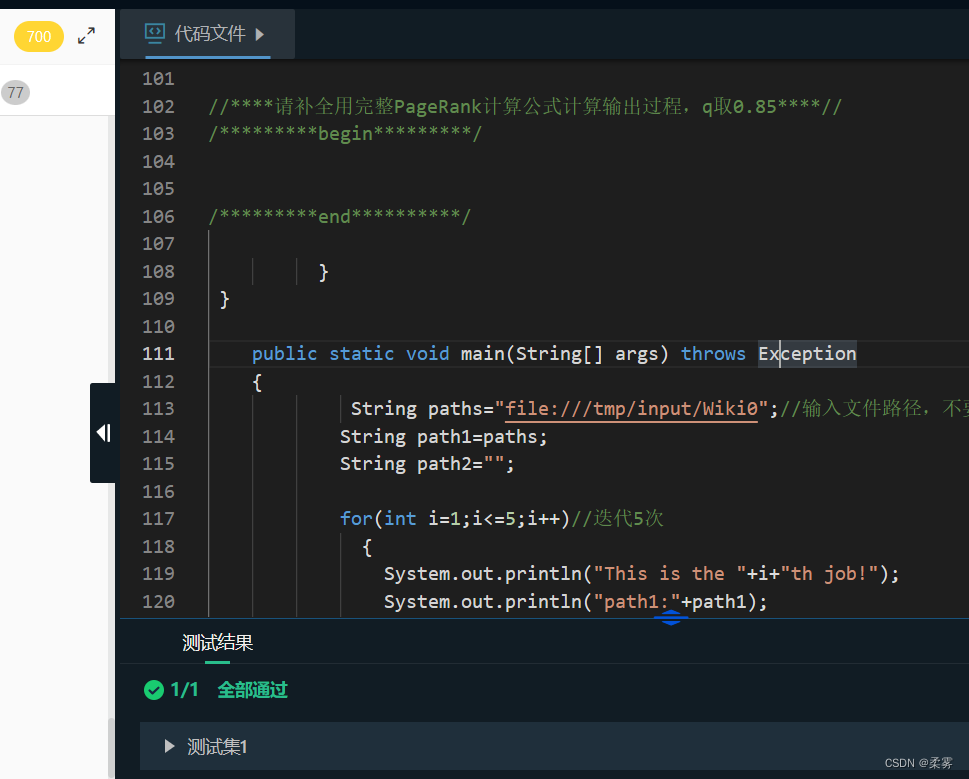
HDFS和MapReduce综合实训
文章目录 第1关:WordCount词频统计第2关:HDFS文件读写第3关:倒排索引第4关: 网页排序——PageRank算法 第1关:WordCount词频统计
测试说明 以下是测试样例:
测试输入样例数据集:文本文档test1…
Hadoop硬件合理配置及raid方面的调研
文章目录前言一、Hadoop硬件合理配置HDFSMapReduceHBase二、Hadoop架构配置建议1.管理节点NameNode2.数据节点DataNode3.JBOD vs. RAID4. SSD与Hadoop3.raid方面总结前言
最近公司在Hadoop服务器未来规划,所以调研了各个方面,有点杂乱,这里记…
Eclipse+JDBC远程操作Hive0.13
[b][colorolive][sizelarge]在前几篇的博客里,散仙已经写了如何在Liunx上安装Hive以及如何与Hadoop集成和将Hive的元数据存储到MySQL里,今天散仙就来看下,如何在Eclipse里通过JDBC的方式操作Hive.我们都知道Hive是一个类SQL的框架,…

MapReduce将HDFS文本数据导入HBase中
HBase本身提供了很多种数据导入的方式,通常有两种常用方式:
使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase另一种方式就是使用HBase原生Client API
本文就是示范如何通过MapReduce作业从一个文件读取数据并…
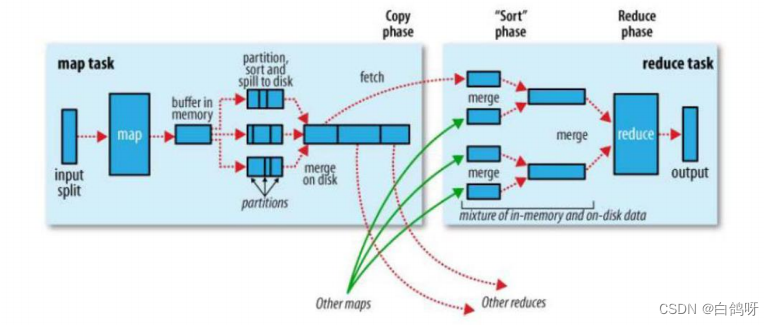
MapReduce【MapTask和ReduceTask的工作机制】
目录 MapTask工作机制
Read阶段
Map阶段
Collect阶段
Spill阶段
步骤1
步骤2
步骤3
Merge阶段
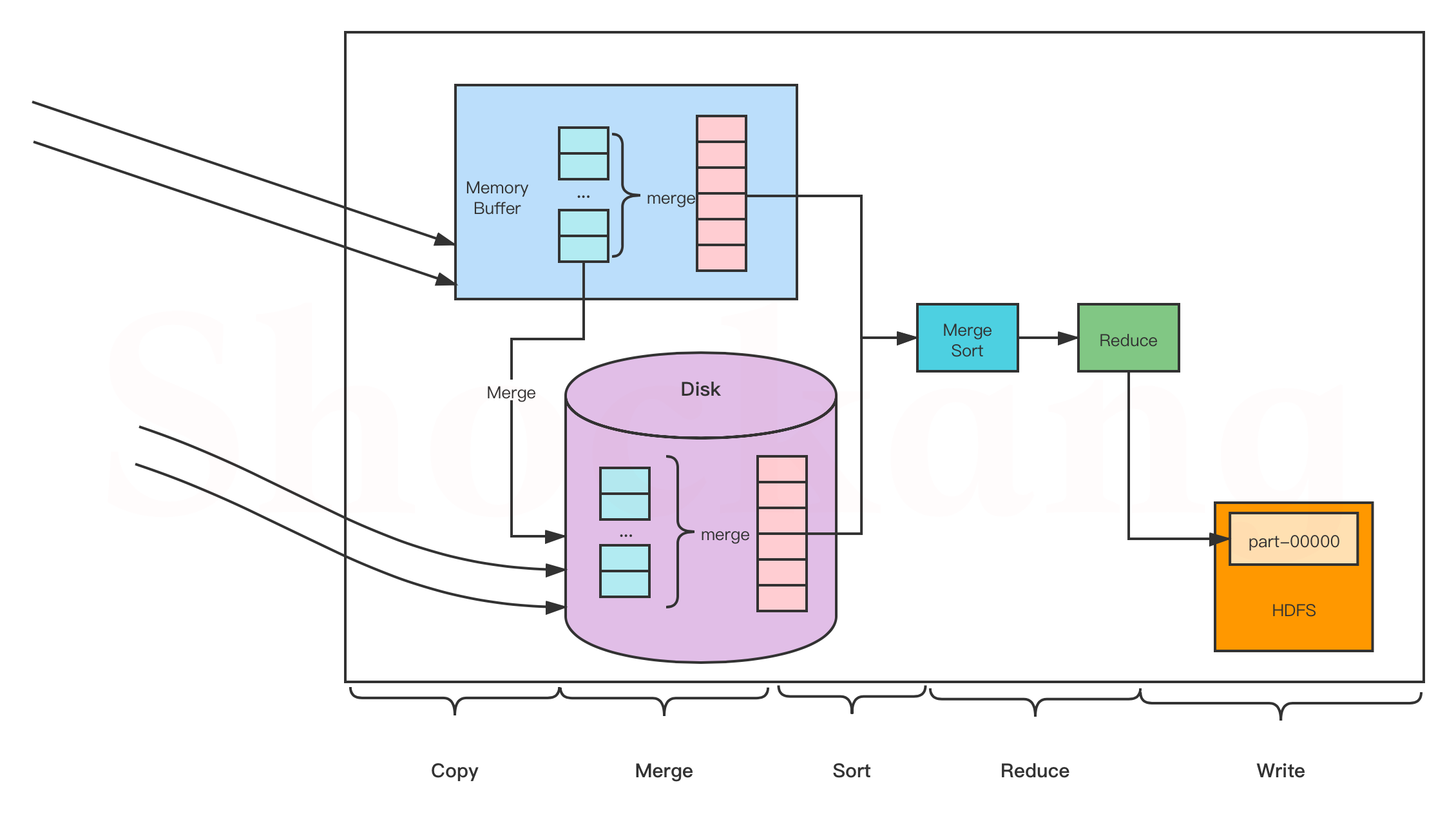
ReduceTask工作机制
Copy阶段
Merge阶段
Sort阶段
Reduce阶段
ReduceTask并行度(ReduceTask个数)
注意事项 MapTask工作机制
Read阶段
MapT…

Hadoop_MapReduce_WordCount案例
目录
1、需求
(1)输入数据
(2)期望输出数据
2、实现(本地测试)
(1)环境准备 1)创建maven工程,MapReduceDemo(maven官网下载maven,…

MapReduce 基础实战
文章目录 第1关:成绩统计第2关:文件内容合并去重 第1关:成绩统计
编程要求 使用MapReduce计算班级每个学生的最好成绩,输入文件路径为/user/test/input,请将计算后的结果输出到/user/test/output/目录下。
测试说明 …

大数据框架之Hadoop:MapReduce(二)Hadoop序列化
2.1序列化概述
1、什么是序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者…

HBase与MapReduce交互
目录
1.版本
2.官方案例
3.自定义案例1
4.自定义案例2 1.版本
HBase:1.3.1
Hadoop:3.1.3
2.官方案例
1.查看 HBase 的 MapReduce 任务的执行需要的jar包 2. 环境变量导入
永久生效的方式:
在 hadoop-env.sh 中配置…
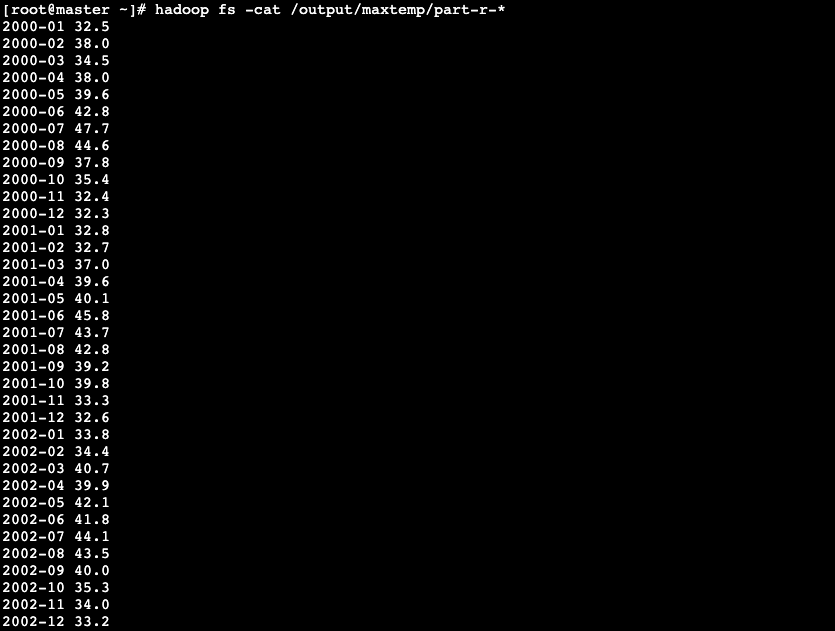
任务14:使用MapReduce提取全国每年最低/最高气温
任务描述
知识点:
使用MapReduce提取数据
重 点:
开发MapReduce程序统计每年每个月的最低气温统计每年每个月的最高气温
内 容:
使用IDEA创建一个MapReduce项目开发MapReduce程序使用MapReduce统计每年每个月的最低气温使用MapReduce…
Hadoop3.0大数据处理学习3(MapReduce原理分析、日志归集、序列化机制、Yarn资源调度器)
MapReduce原理分析
什么是MapReduce
前言:如果想知道一堆牌中有多少张红桃,直接的方式是一张张的检查,并数出有多少张红桃。 而MapReduce的方法是,给所有的节点分配这堆牌,让每个节点计算自己手中有几张是红桃&#…
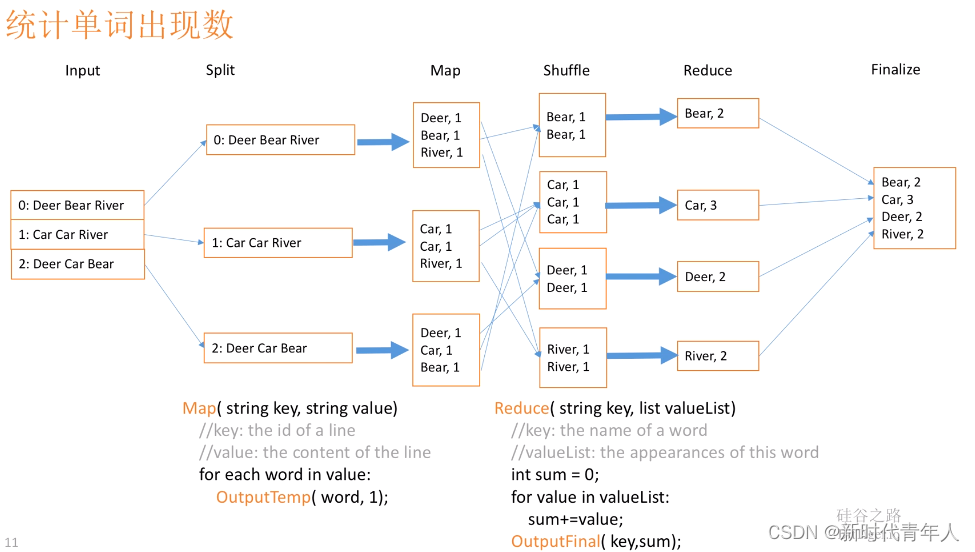
MapReduce原理
MapReduce 编程规范
MapReduce 的开发一共有八个步骤, 其中 Map 阶段分为 2 个步骤,Shuffle 阶段 4 个步骤,Reduce 阶段分为 2 个步骤Map 阶段 2 个步骤
设置 InputFormat 类, 将数据切分为 Key-Value(K1和V1) 对, 输入到第二步自定义 Map 逻辑, 将第一…
Mapreduce中WordCount源码理解
文章目录 0. MapReduce介绍1. 词频统计的代码 0. MapReduce介绍
Hadoop MapReduce是一个软件框架,可以轻松编写应用程序,以可靠、容错的方式在大型集群(数千个节点)的商用硬件上并行处理大量数据(多tb数据)。 MapReduce作业通常将输入数据集分割成独立的…
如何将Lucene索引写入Hadoop?
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2088076[/url]
[/size][/color][/b]
[b][colorgreen][sizemedium]Hadoop是Lucene的子项目,现在发展如火如荼,如何利…
SVD分解的应用——矩阵运算和文本处理中的分类问题
在自然语言处理中,最常见的两类的分 类问题分别是,将文本按主题归类(比如将所有介绍亚运会的新闻归到体育类)和将词汇表中的字词按意思归类(比如将各种体育运动的名称个归成一类)。这两种 分类问题都可用通…
Nutch主流程代码阅读笔记整理
Nutch 的Crawler和Searcher两部分被尽是分开,其主要目的是为了使两个部分可以布地配置在硬件平台上,例如Crawler和Searcher分别被放置在两个主机上,这样可以极大的提高灵活性和性能。 一、总体流程介绍 Nutch 的Crawler和Searcher两部分被尽…
2.6 数据连接的处理
2.6 数据连接的处理 在MapReduce中,连接可以在Map任务中完成,也可以在Reduce任务中完成。前者被称为Map侧的连接,后者被称为Reduce侧的连接。
2.6.1 Reduce侧的连接 基本的原理是,在每条记录添加一个标签指明数据的来源ÿ…
2.1MapReduce输入
2.1MapReduce输入 MapReduce作业依赖于Map阶段为它提供原始数据的输入,这个阶段提供了能获得的最大并行度,因此它的智能化对一个作业的提速至关重要。数据被分成块(chunk),然后Map任务对每块数据进行操作。每块数据被称…
Hadoop之MapReduce的使用示例
MapReduce的基本使用
添加依赖 <dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.3</version></dependency><dependency><groupId>or…
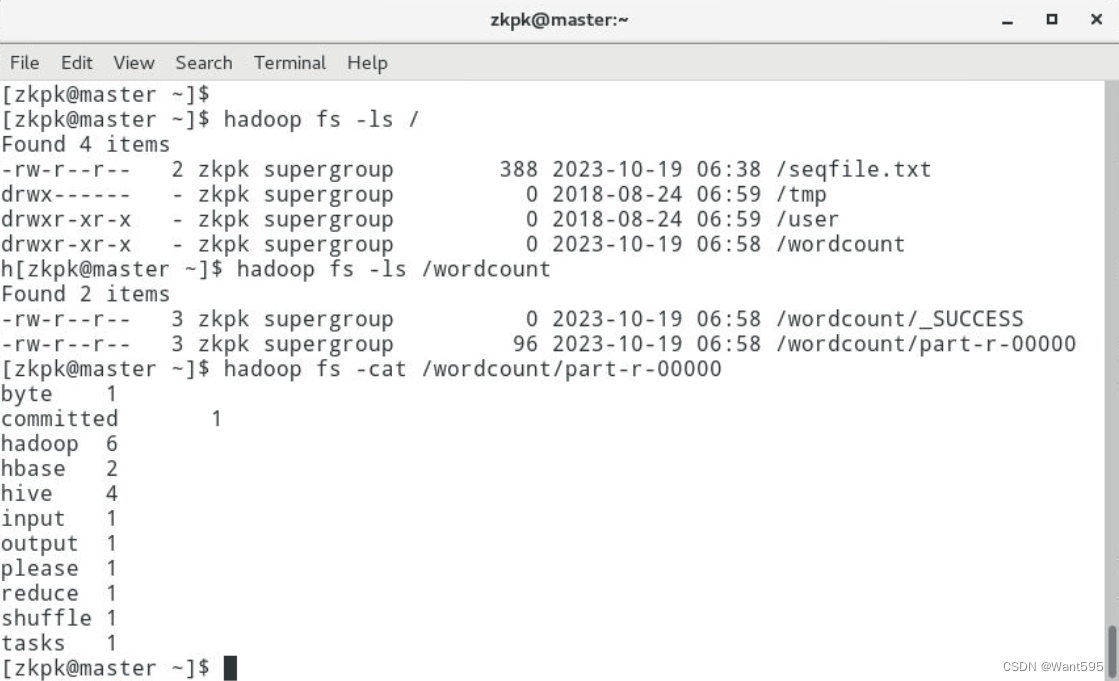
【大数据开发技术】实验06-SequenceFile、元数据操作与MapReduce单词计数
文章目录 SequenceFile、元数据操作与MapReduce单词计数一、实验目标二、实验要求三、实验内容四、实验步骤附:系列文章 SequenceFile、元数据操作与MapReduce单词计数
一、实验目标
熟练掌握hadoop操作指令及HDFS命令行接口掌握HDFS SequenceFile读写操作掌握Map…

Hadoop_MapReduce_Join应用
目录
1.Reduce Join
2.Reduce Join案例实操
1)需求
2)需求分析
3)代码实现
4)测试
5)总结
3.Map Join
4.Map Join案例实操
1)需求
2)需求分析
3)实现代码 1.Reduce Joi…
MapReduce简介
MapReduce是一个编程模型,用于处理和生成大数据。用户通过编写Map函数处理输入键值对生成中间键值对,通过编写Reduce函数来合并所有的中间键值对并生成结果。在我们的日常生活中,大部分的任务都可以被抽象成一个MapReduce模型,并通…
MapReduce(未完待续。。。)
一、MR概述
MapReduce是一个分布式运算的框架。优点:易于编程、扩展性良好、容错性高、适合上千台服务器集群并发工作。1、优点:易于编程、易扩展、高容错,适合PB级以上。
缺点:不擅长实时、流式、DAG计算
2、过程:…
MapReduce分布式编程
目录
一、MapReduce概述
(一)MapReduce定义
(二)MapReduce优缺点
(三)MapReduce核心原理
二、MapReduce编程示例
三、任务调度框架
(一)经典MapReduce任务调度模型
&#x…

Hadoop-MapReduce
Hadoop-MapReduce 文章目录Hadoop-MapReduce1 MapRedcue的介绍1.1 MapReduce定义1.2 MapReduce的思想1.3MapReduce优点1.4MapReduce的缺点1.5 MapReduce进程1.6 MapReduce-WordCount1.6.1 job的讲解2 Hadoop序列化2.1 序列化的定义2.2 hadoop序列化和java序列化的区别3 MapRedu…
MapReduce的FileInputFormat实现类对比
FileInputFormat实现类对比
类切片KV值TextInputFormat按块大小,小文件就是文件个数K:偏移量longWritable; V:这一行内容KeyValueTextInputFormat按块大小,小文件就是文件个数K:文件第一列 V:文件该行剩下的内容NLine…
Spark基础学习--基础介绍
1. Spark基本介绍
1.1 定义
Spark是可以处理大规模数据的统一分布式计算引擎。
1.2 Spark与MapReduce的对比
在之前我们学习过MapReduce,同样作为大数据分布式计算引擎,究竟这两者有什么区别呢? 首先我们回顾一下MapReduce的架构…

十一、了解分布式计算
1、什么是(数据)计算? 2、分布式(数据)计算
(1)概念 顾名思义,分布式计算,即以分布式的形式完成数据的统计,得到需要的结果。 分布式数据计算,顾名思义,就是…
【Spark SQL】1、初探大数据及Hadoop的学习
初探大数据
centos 6.4CDH5.7.0系列http://archive.cloudera.com/cdh5/cdh/5/
生产或测试环境选择对应CDH版本时,一定要采用尾号一样的版本 OOPTB
apache-maven-3.3.9-bin.tar.gzJdk-7u51-linux-x64.tar.gzZeppelin-0.7.1-bin.tgzHive-1.1.0-cdh5.7.0.tar.gzhado…
Pig0.15集成Tez,让猪飞起来
1,Tez是什么?Tez是Hortonworks公司开源的一种新型基于DAG有向无环图开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能,看下面一张图,就能说明问题:[img]http://dl2.iteye.co…
【MapReduce源码分析】
MapReduce源码分析 Client任务提交源码分析MapTask源码分析ReduceTask源码分析 Client任务提交源码分析
客户端通过 hadoop jar 的命令形式来提交这个 jar 运行 hadoop jar examples.jar WordCount /wc/input/ /wc/output/ hadoop 这shell脚本:如果参数是jar, clas…

HDFS Namenode是如何工作的?
来自:http://www.csdn.net/article/2012-07-03/2807066 HDFS(Hadoop Distributed Filesystem)客户端通过被称之为Namenode单服务器节点执行文件系统原数据操作,同时DataNode会与其他DataNode进行通信并复制数据块以实现冗余&#…

MapReduce - 读取 ORC, RcFile 文件
一.引言
MR 任务处理相关 hive 表数据时格式为 orc 和 rcFile,下面记录两种处理方法。 二.偷懒版读取 ORC, RcFile 文件
最初不太熟悉 mr,只会 textFormat 一种输入模式,于是遇到 orc 和 rcFile 形式的 hive 数据需要在 mr 读取时ÿ…

本地跑Mapreduce程序的相关配置
本地跑MapReduce程序需要配置的代码
为了在本地运行MapReduce程序,需要加如下的东西 在项目中创建一个如图所示的包:org.apache.hadoop.io.nativeio,并在该包下面创建一个名为:NativeIO的类(注意:名字不能…
【集群模式】执行MapReduce程序-wordcount
因为是在hadoop集群下通过jar包的方式运行我们自己写的wordcount案例,所以需要传递的是 HDFS中的文件路径,所以我们需要修改上一节【本地模式】中 WordCountRunner类 的代码:
//5.设置统计文件输入的路径,将命令行的第一个参数作为输入文件的…

MapReduce:Mapper阶段的输出之MapOutputBuffer、环形缓冲区工作原理
MapOutputBuffer
在上一篇博客中说过,Mapper的输出中有两个重要部分:一是collector,负责收集Mapper输出并将其交付给Reducer;二是partitioner,决定了应该将具体的输出交付给哪一个Reducer。
Mapper的输出是通过其Rec…
MapReduce概念
1、概念 MapReduce 是一种编程模型,用于大规模数据集的并行处理。它是由 Google 开发的,用于处理大规模数据集的分布式计算框架。 MapReduce 的主要作用是将一个大的任务分解成多个小的任务,并在多台机器上并行执行这些任务。它包括两…
MapReduce的执行过程(以及其中排序)
Map阶段(MapTask): 切片(Split)-----读取数据(Read)-------交给Mapper处理(Map)------分区和排序(sort) Reduce阶段(ReduceTask): 拷贝数据(copy)------排序(sort)-----合并(reduce)-----写出(write)
1、Map task读取: 框架调用InputFormat类的子类读取…
搭建hadoop集群常见坑一:secondarynamenode只在root账户能启动在一般账户不能启动的解决方法。
一、事情的起因:
本来是按照手册顺利的安装了全分布式集群,并且能够正常启动集群,集群有三台机器,hadoop102 是master,其他2台是node,secondarynamenode配置在hadoop104上,
一次手痒不小心在m…
9-MapReduce开发技术
单选题 题目1:MapReduce自定义排序规则需要重写下列那项方法 选项: A readFields() B compareTo() C map() D reduce() 答案:B ------------------------------ 题目2:下面关于MapReduce模型中Map函数与Reduce函数的描述正确的是 选项: A…
大数据处理三大瓶颈:大容量、多格式和速度
越来越多的大企业的数据集以及创建需要的一切技术,包括存储、网络、分析、归档和检索等,这些被认为是海量数据。这些大量信息直接推动了存储、服务器以及安全的发展。同时也是给IT部门带来了一系列必须解决的问题。
信息技术研究和分析的公司Gartner认为…

倒排索引和MapReduce简介
1.前言 学习hadoop的童鞋,倒排索引这个算法还是挺重要的。这是以后展开工作的基础。首先,我们来认识下什么是倒排索引: 倒排索引简单地就是:根据单词,返回它在哪个文件中出现过,而且频率是多少的结果。这就…

阿里云 E-MapReduce 全面开启 Serverless 时代
作者:李钰 - 阿里云资深技术专家、EMR 负责人
EMR 2.0 平台
阿里云正式发布云原生开源大数据平台EMR 2.0已历经一年时间,如今EMR 2.0全新平台在生产上已经全面落地,资源占比超过60%。EMR 2.0平台之所以在生产上这么快落地,源于其…
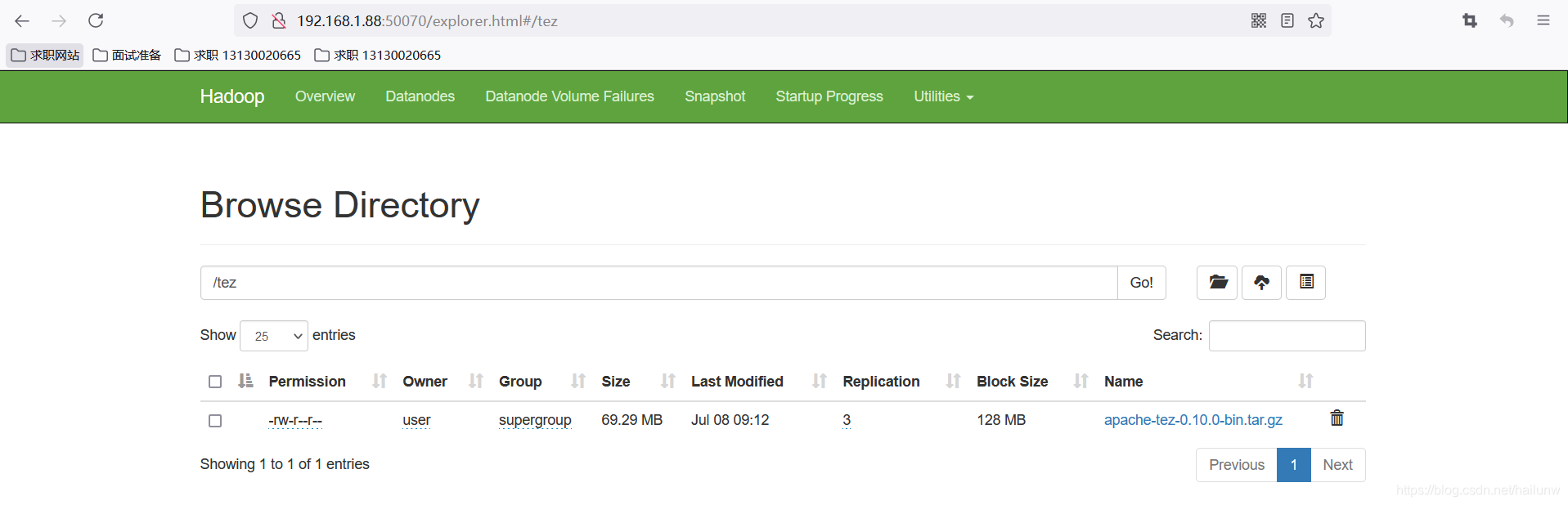
Tez的简介以及安装配置
Tez简介
Tez是一个Hive的运行引擎,由于没有中间存盘的过程,性能优于MR。Tez可以将多个依赖作业转换成一个作业,这样只需要写一次HDFS,中间节点少,提高作业的计算性能。 Tez的安装步骤
1)下载安装包到hive所在的66服务…

Hadoop 开启 histotryserver
Hadoop 开启 histotryserver Hadoop自带了一个历史服务,可以通过历史服务在web端查看已经运行完的Mapreduce作业记录, 默认情况下,Hadoop历史服务是没有启动的,需要自行启动。 启动后,在下图中点击history可跳转至历史…
实验5:MapReduce 初级编程实践
由于CSDN上传md文件总是会使图片失效 完整的实验文档地址如下: https://download.csdn.net/download/qq_36428822/85709497 实验内容与完成情况: (一)编程实现文件合并和去重操作 对于两个输入文件,即文件 A 和文件 B&…

【大数据】图解 Hadoop 生态系统及其组件
图解 Hadoop 生态系统及其组件 1.HDFS2.MapReduce3.YARN4.Hive5.Pig6.Mahout7.HBase8.Zookeeper9.Sqoop10.Flume11.Oozie12.Ambari13.Spark 在了解 Hadoop 生态系统及其组件之前,我们首先了解一下 Hadoop 的三大组件,即 HDFS、MapReduce、YARN࿰…
Hadoop3教程(十四):MapReduce中的排序
文章目录 (99)WritableComparable排序什么是排序什么时候需要排序排序有哪些分类如何实现自定义排序 (100)全排序案例案例需求思路分析实际代码 (101)二次排序案例(102) 区内排序案例…
大数据开发之Hadoop(完整版+练习)
第 1 章:Hadoop概述
1.1 Hadoop是什么
1、Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 2、主要解决,海量数据的存储和海量数据的分析计算问题。 3、Hadoop通常是指一个更广泛的概念-Hadoop生态圈
1.2 Hadoop优势(4高…

MapReduce小试牛刀
部署完hadoop单机版后,试下mapreduce是怎么分析处理数据的
Word Count
Word Count 就是"词语统计",这是 MapReduce 工作程序中最经典的一种。它的主要任务是对一个文本文件中的词语作归纳统计,统计出每个出现过的词语一共出现的次…

大数据技术实验一-在ubuntu18.04中安装伪分布式Hadoop并使用自带wordcount案例
必要时转载请标明出处 本文是在ubuntu上安装Hadoop的操作,关于如何在centOS上安装Hadoop可参考 https://blog.csdn.net/hgxiaojiujiu/article/details/120382331 实验一 熟悉常用的Linux操作和Hadoop操作
一、 实验目的
(1)掌握Linu虚拟机的…
怎样选择软件开发公司
随着疫情的到来,不少小伙伴已经在家办公了,这个时候就显示出办公软件的重要性了。那在众多的软件开发公司中,怎样选择靠谱的呢?这个问题估计是每个想要定制软件的人都很头疼的问题。 我们先来说一下,我们常规找软件公司…

利用MapReduce的思想用Hive做词频统计
利用MapReduce的思想用Hive做词频统计
关于mapreduce hive 等的关系大家可以参考这位博主的文章:
1.打开hadoop与hive
start-dfs.sh 或者 start-all.sh
qive或者进到hive安装目录的bin下再输入hive
2.在hive shell下面先建立数据库WordCount ,然后…
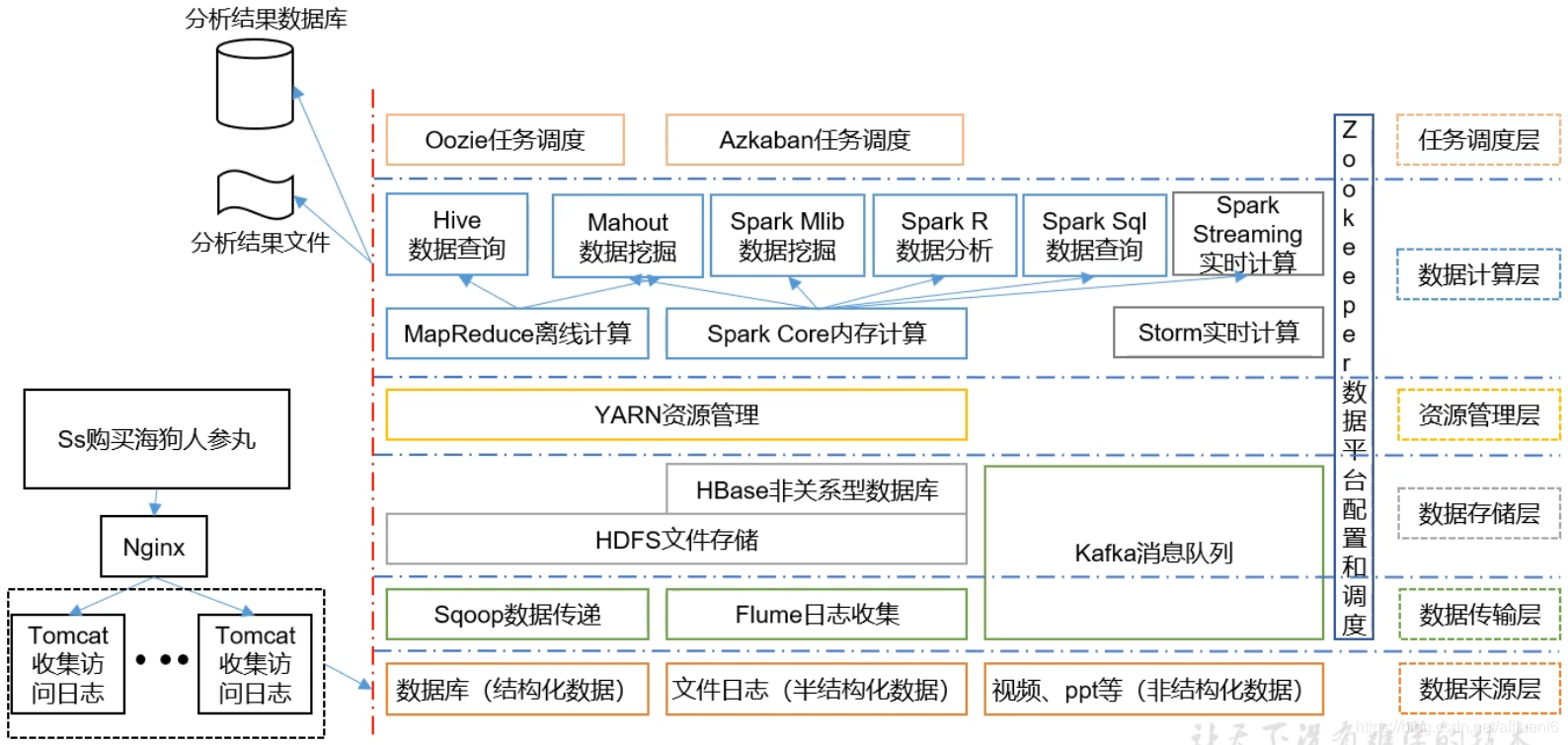
大数据学习框架综述-Hadoop组成、大数据生态、推荐系统技术框架
本文目录如下:大数据学习框架综述大数据学习框架综述
Hadoop的组成 注:YARN之上调用的是MapReduce计算框架,也可调用其它计算框架的资源,如Spark、Flink。 大数据技术生态体系 图中涉及的技术名词解释如下: Sqoop&…

1.MapReduce入门-MapReduce进程、常用序列化类型、WordCount实例
本文目录如下:第1章 MapReduce概述1.1 MapReduce进程1.2 常用数据序列化类型1.3 MapReduce编程规范1.3.1 Mapper阶段1.3.2 Reducer阶段1.3.3 Driver阶段1.4 WordCount实例1.4.1 创建一个Maven工程MapReduce-0100-WordCount1.4.2 导入相应依赖1.4.3 配置日志信息1.4.…

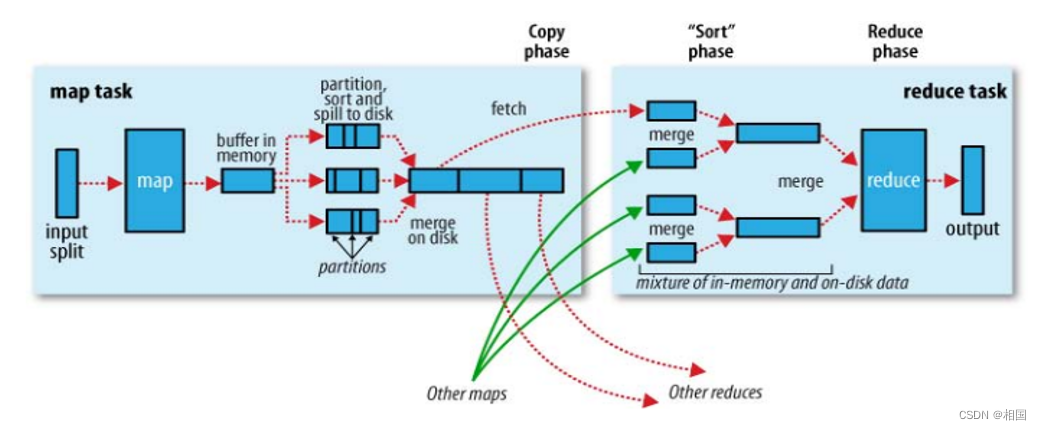
MapReduce:shuffle阶段之Mapper输出
shuffle本意为混洗,MR将排完序的mapper输出作为reducer的输入的过程就称为shuffle,可以理解为mapper到reducer的中间过程,在这个过程中MR框架其实干了很多事。 Mapper输出阶段概述
map函数开始产生输出时(调用context.write()方法࿰…
MapReduce编程框架的核心实现思想
Yran: 1.任务(Job)的监控 AM applicationMaster 2.管理集群中的资源(CPU 内存 网络 IO) Yarn汇总集群中所有物理机器的资源(CPU 内存 网络) 根据不同Job作业的需要按需分配给每一个job作业&…
Hadoop基本架构
说说你对集群概念的理解?
集群是多个服务器组成的一个群体,这些服务器做相同类型任务。好比饭店做饭一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关系是集群;切菜,备菜࿰…


Mapreduce:关于遍历Iterable迭代器添加到List中的问题
比如Reducer的输入为<1,(1,2,3,4,5)>
需要在reduce()方法中遍历两次Iterable迭代器,由于第一次遍历后迭代器的指针已经达到末尾,所以不能遍历两次同一个迭代器
有一种思路是通过foreach遍历,并添加到列表中;在…
第一个MapReduce程序——WordCount
通常我们在学习一门语言的时候,写的第一个程序就是Hello World。而在学习Hadoop时,我们要写的第一个程序就是词频统计WordCount程序。
一、MapReduce简介
1.1 MapReduce编程模型
MapReduce采用”分而治之”的思想,把对大规模数据集的操作&…
MapReduce案例:Reduce端join操作
需求: 假如数据量巨大,两表的数据是以文件的形式存储在hdfs中,需要MapReduce程序来实现以下SQL查询运算
select a.id,a.date,b.name.b.category_id,b.price
from
t_ordet a left join t_product b on a.pid b.id商品表:id …
使用MapReduce程序实现从hbase读写数据输出到hdfs分布式文件系统中
将hbase中的数据迁移到hdfs分布式文件系统中 package com.briup.hbase;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoo…
实验八 项目案例-电商数据分析
电商大数据离线计算第1关:统计用户流失情况任务描述相关知识数据文件格式说明用户流失情况编程要求测试说明代码实现第2关:统计所有商品点击量排行任务描述相关知识数据文件格式说明商品点击量排行cleanup()方法编程要求测试说明代码实现第3关࿱…
MapReduce 详细教程
文章目录1. MapReduce 概述1.1 MapReduce 定义1.2 MapReduce 优缺点1.3 MapReduce 核心思想1.4 MapReduce 进程1.5 MapReduce 编程规范1.6 WordCount 案例实操1.6.1 需求1.6.2 需求分析1.6.3 编写程序2. Hadoop 序列化2.1 序列化概述2.2 自定义 bean 对象实现序列化接口2.3 序列…

MapReduce 三个经典案例(倒排索引、TopN、找共同好友)
文章目录1. 倒排索引案例1.1 需求1.2 需求分析1.3 代码实现1.3.1 第一次处理1.3.2 第二次处理2. TopN 案例2.1 需求2.2 代码实现3. 找共同好友案例3.1 需求3.2 需求分析3.3 代码实现3.3.1 第一次处理3.3.2 第二次处理1. 倒排索引案例
1.1 需求 有大量的文本(文档、…
MapReduce之job配置信息介绍
一.job
hadoop中的MapReduce可以使用Java进行MapReduce的逻辑撰写。其中就需要job进行相关配置。job作为MapReduce的配置信息以及启动项直接打包成jar包,hadoop可以运行这个jar包实现mapreduce的功能。本文主要从源码中,将job的配置项信息提取出来&…
Hadoop系列文章SpringBoot编程实现HDFS读写文件、MapReduce程序
Hadoop系列文章 SpringBoot编程实现HDFS读写文件、MapReduce程序实现HDFS操作引入依赖winutils码代码读取HDFS中的文件写内容到文件中MapReduce操作MapReduce工作过程详解Mapper映射器Input的mapmap的outputmap的数量ReducershuffleSort(排序)二次排序reducePartitionerCounter…

Hadoop_MapReduce_Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。 理解:
1.Map方法得<k,v>数据,进行分区标记后存入环形缓冲区,图中环形缓冲区左边箭头是索引写入,右边箭头是数据写入,当环形缓冲区的容量达…

Hadoop_MapReduce_OutputFormat数据输出
目录
1.OutputFormat接口实现类
2. 自定义OutputFormat案例实操
1)需求
2)需求分析
3)代码
(1)编写LogMapper类
(2)编写LogReducer类
(3)自定义一个LogOutputF…
calculate the number of characters-统计文件中的字符数,非空白字符数,字母数,输入到文件和屏幕:...
calculate the number of characters-统计文件中的字符数,非空白字符数,字母数,输入到文件和屏幕://calculate the number of characters-统计文件中的字符数,非空白字符数,字母数,输入到文件和…

Hadoop权威指南(第2版)--第2章
1.MapReduce编程模型:线性可伸缩,使用无共享框架,将问题分为独立的块,再进行并行计算。
MapReduce编程模型可用于数据处理,模型比较简单,但用于绽有用的程序并不简单。Hadoop可以运行由各种语言编写的MapR…

hadoop学习笔记(八)MapReduce应用程序执行过程及java程序编写
MapReduce应用程序执行过 执行的MapReduce的程序会被部署到集群中去,Master负责作业调度,worker负责执行执行Map和Reduce任务从集群中选出执行Map任务的空闲机器,进行分片处理,然后进行mapmap任务读取输入数据,得到输出…
Hadoop之mapreduce参数大全-6
126.指定 Map 任务运行的节点标签表达式
mapreduce.map.node-label-expression 是 Hadoop MapReduce 框架中的一个配置属性,用于指定 Map 任务运行的节点标签表达式。节点标签是在 Hadoop 集群中为节点分配的用户定义的标签,可用于将 Map 任务限制在特定…
intellij 2020.3 中导入maven项目
2020.12.12
今天想开始搞点项目,项目开始时是要先运行别人的项目才开始学习。结果发现在一开始导入的时候就吃了很多苦头。(比如把一个Maven项目当做了一个普通项目来导入,直接白忙活。)
导入别人Maven项目的步骤如下
1、 【Fi…

Hadoop——HDFS、MapReduce、Yarn期末复习版(搭配尚硅谷视频速通)
一、HDFS 1.HDFS概述 1.1 HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自…

【MapReduce】MapReduce知识点总结及实例分析
初见
▍ 分布式并行编程
大名鼎鼎的摩尔定律告诉我们,CPU性能每18个月翻一番!然而,摩尔定律在21世纪初开始失效;雪上加霜的是,需要处理的数据量在呈几何倍数增长分布式的思想应运而生——将分布式程序运行在廉价的计…
Java8对List的求和
想要用流对List进行求和,但查找完资料都是对List中Object中的某个字段进行求和,就像这样:
long sum list.stream().mapToLong(User::getAge).sum();而我list中本身存的就是基本类型的数字,并不适用。后来在IBM开发者…
MapReduce编程:自定义分区和自定义计数器
文章目录 MapReduce编程:自定义分区和自定义计数器一、实验目标二、实验要求及注意事项三、实验内容及步骤 附:系列文章 MapReduce编程:自定义分区和自定义计数器
一、实验目标
熟练掌握Mapper类,Reducer类和main函数的编写方法…
Hadoop之倒排索引
前言: 从IT跨度到DT,如今的数据每天都在海量的增长。面对如此巨大的数据,如何能让搜索引擎更好的工作呢?本文作为Hadoop系列的第二篇,将介绍分布式情况下搜索引擎的基础实现,即“倒排索引”。
1.问题描述 将所有…
Hadoop入门介绍
Hadoop这个名字不是一个缩写,它是一个虚构的名字。该项目的创建者,Doug Cutting如此解释Hadoop的得名:"这个名字是我孩子给一个棕黄色的大象样子的填充玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多…
2024.1.5 Hadoop各组件工作原理,面试题
目录 1 . 简述下分布式和集群的区别
2. Hadoop的三大组件是什么?
3. 请简述hive元数据服务配置的三种模式?
4. 数据库与数据仓库的区别?
5. 简述下数据仓库经典三层架构?
6. 请简述内部表和外部表的区别?
7. 简述Hive的特点,以及Hive 和RDBMS有什么异同
8. hive中无…
在Web端查看各节点状态(总结)
本文目录如下:5 在Web端查看各节点状态(总结)5.1 Web端查看HDFS的NameNode5.2 Web端查看HDFS的DataNode5.3 Web端查看HDFS的SecondaryNameNode5.4 Web端查看YARN的ResourceManage5.5 查看HDFS上传的文件5.6 查看历史服务器信息5.7 查看日志聚集信息5 在Web端查看各节…
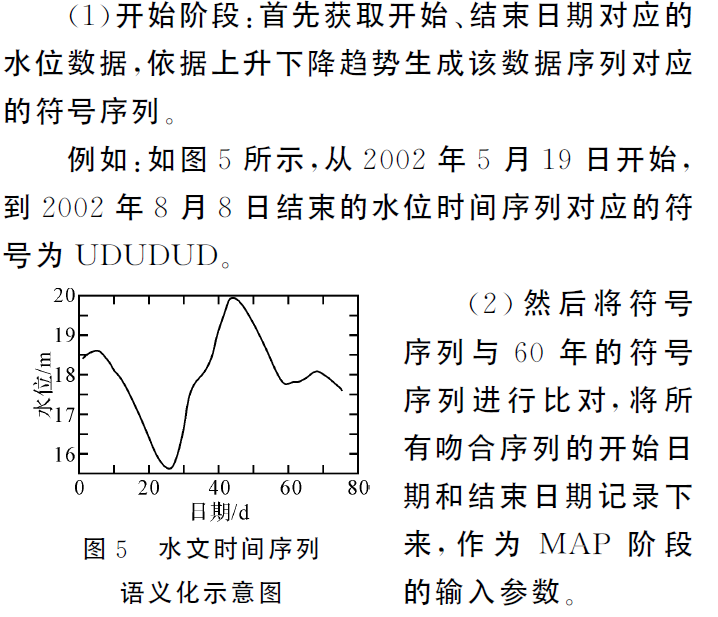
论文学习——基于Hadoop的水文时间序列相似性研究与应用
文章目录1 摘要2 引言3 MapReduce 计算模型3.1 Hadoop体系结构4 DTW 改进算法 FastDTW4.1 介绍DTW算法4.2 FastDTW 方法5 水文时间序列相似性查找方法5.1 水文数据的预处理5.2 MapReduce过程写在前面:《计算机与数字工程》;
作者:顾昕辰、万…

MapReduce案例:组合键、自定义分组器实现不同文件中的WordCount
需求:统计单词分别在不同文件中出现频率 组合键:单词-文件名
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;public class Wo…
HibernateShards-数据库水平分区解决方案
HibernateShard多数据库水平分区解决方案。 1. 简介Hibernate 的一个扩展,用于处理多数据库水平分区架构。 由google工程师 2007年 捐献给 Hibernate社区。 http://www.hibernate.org/414.html目前版本: 3.0.0 beta2, 未发GA版。 条件&…
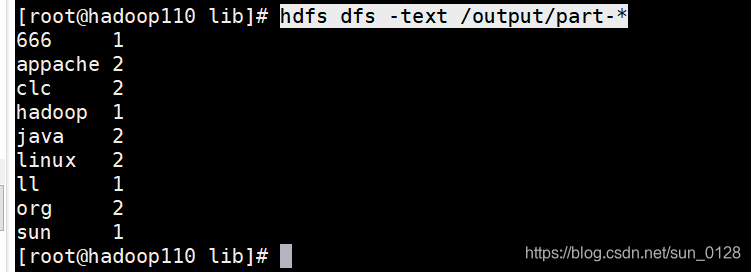
MapReduce实现WordCount词频统计
文章目录一.设计分析二.代码开发1.新建maven工程,添加依赖2.编写Mapper类3.编写Reduce类4.编写Driver类执行Job5.执行会在本工程目录出现一个test目录打开目录中的part-r-00000文件即统计词频文件,如下:6.在hadoop中运行1)修改Driver类中输入输出路径:2)打jar包将jar包上传到ha…

【Hadoop】三分钟快速了解Hadoop
一Hadoop初见
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。Hadoop的核心是:分布式文件系统HDFS 分布式计算模型MapReduceHadoo…
大数据开发 | MapReduce
1. MapReduce 介绍
1.1MapReduce的作用
假设有一个计算文件中单词个数的需求,文件比较多也比较大,在单击运行的时候机器的内存受限,磁盘受限,运算能力受限,而一旦将单机版程序扩展到集群来分布式运行,将极…

一个例子带你了解MapReduce
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成…
Hadoop-MapReduce案例-倒排索引
1 需求 有大量的文本(文档、网页),需要建立搜索索引 (1)数据输入 aa.txt
hadoop spark
hadoop java
hadoop java
hadoop scalabb.txt
hadoop spark
hadoop spark
spark scala
java scalacc.txt
hadoop scala
hadoop…

MapReduce:分区与分组
分区、分组
分区:在Mapper的输出时进行,默认会采用HashPartitioner,会根据key值和reduce数进行分组;在写入MapOutputBuffer的缓冲区之前每个kv对就已经获取了对应的分区索引,在溢写时默认会根据分区索引从小到大&…
MapReduce:序列化WritableComparable接口与WritableComparator比较器、组合键、二次排序
目录
序列化
WritableComparable接口
Writable接口
Comparable接口
WritableComparator比较器
自定义Writable类(组合键)实现二排 序列化
序列化:将结构化对象转化为字节流以便在网络上传输或写到磁盘进行存储的过程
反序列化:将字节流转回结构化…
HBase:客户端API之CompareFilter过滤器、与MapReduce集成
目录
过滤器
CompareFilter
MapReduce集成 hdfs->hbase hbase->hdfs hbase->hbase 过滤器
HBase中可以通过get()和scan()指定列族、列、时间戳及版本号来查询数据,但缺少一些细粒度的筛选功能,比如正则表达式对行键或值进行筛选。Get和Scan…
MapReduce:自定义RecordReader阅读器、自定义Partitioner分区器案例
需求
源文件中每行为一个数字,分别计算其中奇偶行数字之和
分析
默认的TextInputFormat会使Mapper接受到字符偏移量为K1,则需要自定义阅读器使K1为行号,在自定义分区器(也可以分组)根据行号将奇偶行分开进行累加
代…

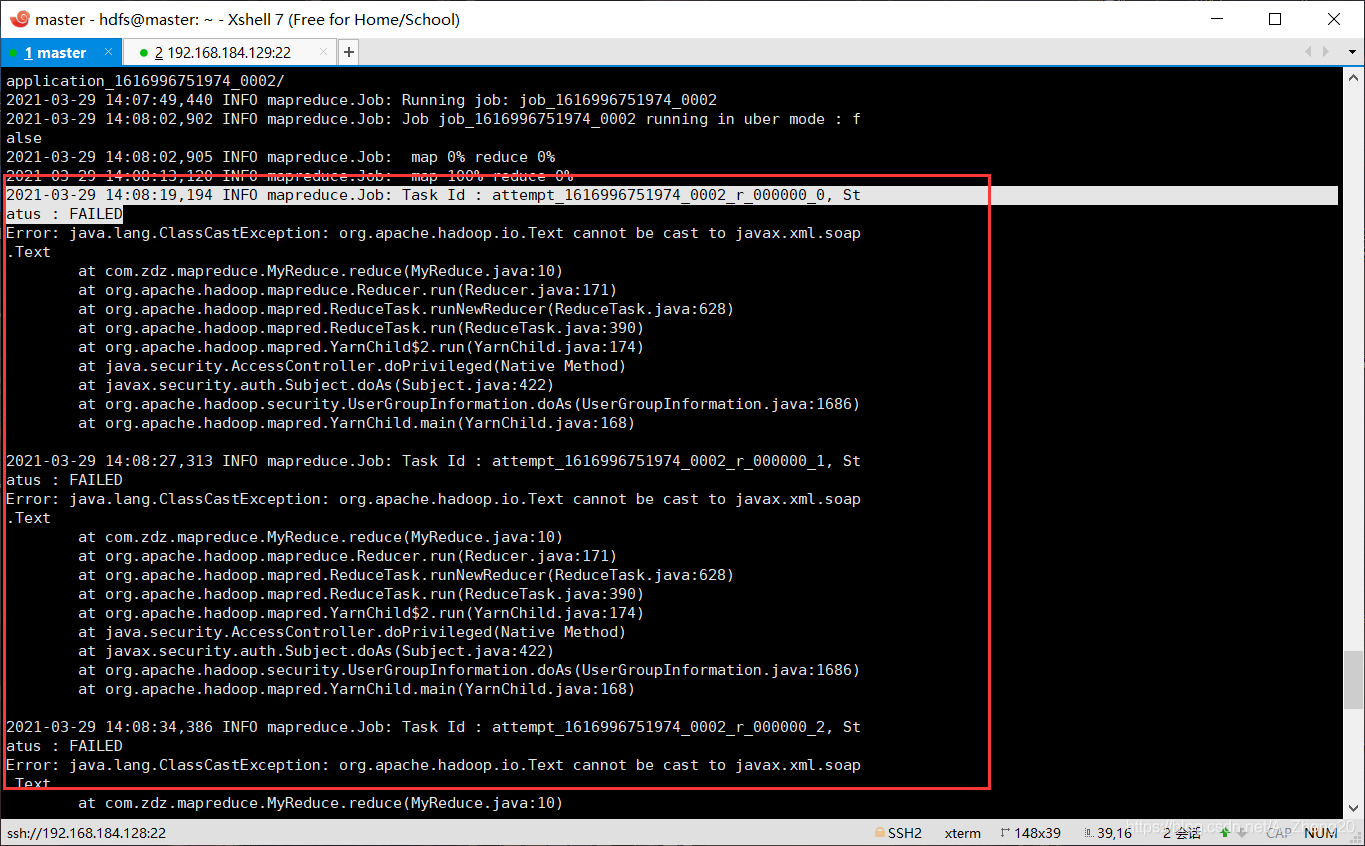
ExitCodeExcetion excode=-1073741701:eclipes运行mapreduce在本地local模式下报错
这几天在mapreduce上摸爬滚打,可谓是困难重重
背景如下:mapreduce.framework.name默认为local,在本地(file:///)eclipses运行mapreduce作业,报错 万万没想到是因为bin下的winutils.exe不能运行 下载个 DirectX修复工具 即可
一、Hadoop3.1.3集群搭建
一、集群规划
hadoop01(209.2)hadoop02(209.3)hadoop03(209.4)HDFSNameNode DataNodeDataNodeSecondaryNameNode DataNodeYARNNodeManagerResourceManager NodeManagerNodeManager NameNode和SecondaryNameNode不要放在同一台服务器上 二、创建用户
useradd atguigu
passwd *…

Hadoop必将风靡2012年的六个理由
毫无疑问,Hadoop已经赢得了大量投资者和IT媒体的青睐,但却很少看到任何的实际产出。即将过去的2011是风暴来袭前的准备阶段,为很多新公司新用户建立了一个海量数据的分析平台。就连微软这样的互联网巨头都已放弃其他平台而选择Hadoop…

kafka streams_另一个Java 8 Lamdbas和Streams示例
kafka streams我一直落后于Java 8所关注的功能,因此在这篇文章中,我将简要介绍我对lambda和stream的初步经验。 和往常一样,我将专注于Podcast课程: package org.codingpedia.learning.java.core;import java.util.Comparator;pu…
MapReduce案例:求共同好友
目录
需求1:所有人两两之间的共同好友
需求2:互为好友的两人之间的共同好友 需求1:所有人两两之间的共同好友
原文件:
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:…
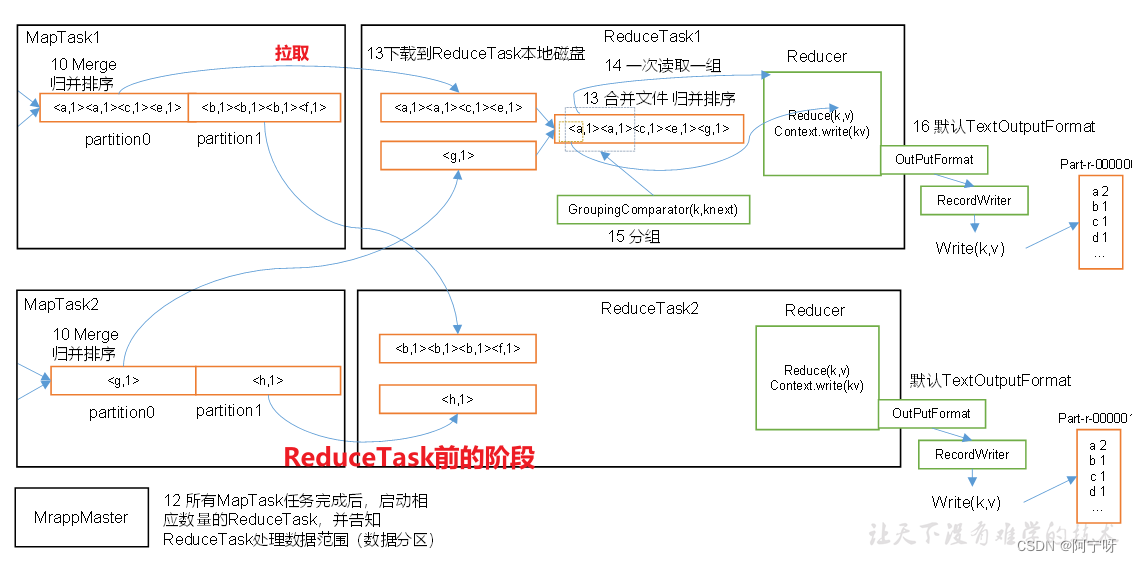
【大数据之Hadoop】十三、MapReduce之WritableComparable排序
MapReduce框架必须进行排序,MapTask和ReduceTask都会对key按字典顺序排序,是默认的行为(默认使用快速排序),有利于提高效率。任何程序数据都会进行排序,不管逻辑是否需要。 对于排序而言分为两个阶段&#…
mapreduce-maven--30.串联所有单词的字串
项目对象模型(Project Object Model,POM):Maven使用POM文件来描述项目的结构、依赖和构建设置。POM是一个XML文件,位于项目根目录下,并包含项目的基本信息、构建设置、依赖管理等。 依赖管理:M…

Hadoop3教程(十五):MapReduce中的Combiner
文章目录 (103)Combiner概述什么是CombinerCombiner有什么用处Combiner有什么特点如何自定义Combiner (104)Combiner合并案例实操如何从日志里查看Combiner如果不存在Reduce阶段,会发生什么自定义Combiner的两种方式 参…
hadoop中使用 Gzip 压缩格式支持笔记
hadoop中支持的压缩方式有多种,比如Gzip,bzip2,zlib等,其中Gzip是hadoop中内置就支持的一种压缩方式,这种压缩方式在平 时linux 的开发人员和管理 员中使用的比较广泛,压缩比也比较高,压缩速度也…

2.Hadoop运行模式-本地式、伪分布式 (仅用于测试) | 历史服务器、日志聚集
本文目录如下:Hadoop运行模式-本地式、伪分布式2.本地运行模式2.1 官方Grep案例2.2 官方WordCount案例3 伪分布式运行模式 (仅用于测试)3.1 启动HDFS并运行MapReduce程序3.1.1 配置集群3.1.2 启动集群3.1.3 查看集群3.1.4 操作集群3.2 启动YARN并运行MapReduce程序3…

个人笔记:分布式大数据技术原理(一)Hadoop 框架
Apache Hadoop 软件库是一个框架,它允许使用简单的编程模型,实现跨计算机集群的大型数据集的分布式处理。它最初的设计目的是为了检测和处理应用程序层的故障,从单个机器扩展到数千台机器(这些机器可以是廉价的)&#…
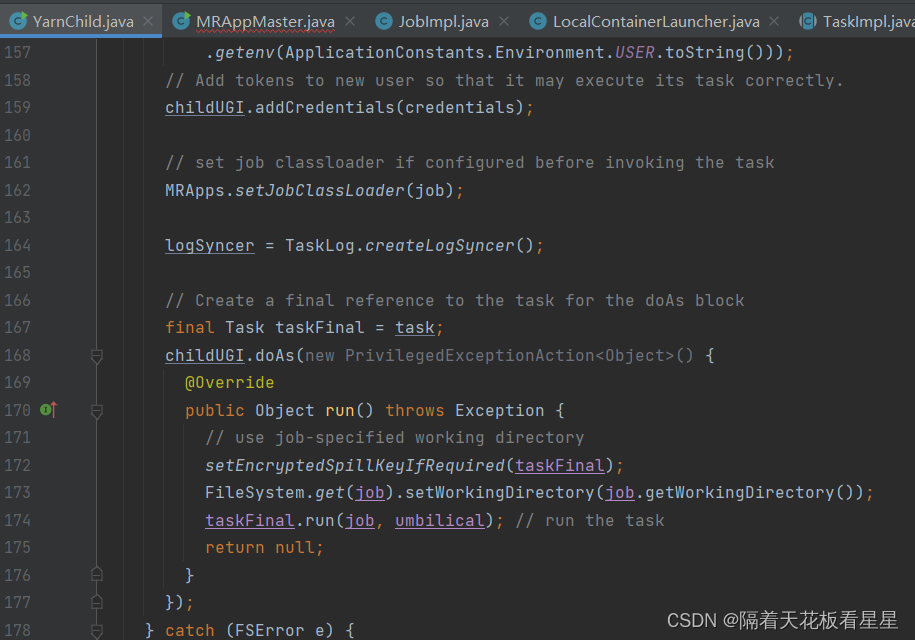
Hadoop-MapReduce-MRAppMaster启动篇
一、源码下载
下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧
Index of /dist/hadoop/core
二、上下文
在上一篇<Hadoop-MapReduce-源码跟读-客户端篇>中已经将到:作业提交到ResourceManager,那…
MapReduce基础之:MapReduce过程中的排序
mapreduce为什么要排序
是为了通过外排(外部排序)降低内存的使用量:因为reduce阶段需要分组,将key相同的放在一起进行规约,使用了两种算法:hashmap和sort,如果在reduce阶段sort排序(内部排序),太消耗内存&…
【大数据之Hadoop】三十四、Hadoop综合调优之小文件优化方法
1 Hadoop小文件弊端 HDFS上每个文件都要在NameNode上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode的内存空间,另一方面就是元数据文件…
设计一个基于MapReduce的算法,求出数据集中的最小值。假设Reducer任务数量大于1,请简要描述该算法(可使用分区. 合并过程)
设计一个基于MapReduce的算法,求出数据集中的最小值。假设Reducer任务数量大于1,请简要描述该算法(可使用分区. 合并过程)
设计一个基于MapReduce的算法来求数据集中的最小值需要考虑如何在多个Reducer任务中分配和合并工作。这里是算法的简要描述&…
mapreduce 的工作原理以及 hdfs 上传文件的流程
推荐两篇博文
mapreduce 的工作原理:
图文详解 MapReduce 工作流程_mapreduce工作流程_Shockang的博客-CSDN博客
hdfs 上传文件的流程
HDFS原理 - 知乎
大数据处理领域的经典框架:MapReduce详解与应用【上进小菜猪大数据】
上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。
MapReduce是一个经典的大数据处理框架,可以帮助我们高效地处理庞大的数据集。本文将介绍MapReduce的基本原理和实现方法,并给出一个简单的示例。
一、MapR…

MapReduce基础知识
MapReduce
1、介绍MapReduce
MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小…
Hadoop问题笔记之五问五答-日志配置
[b][colorgreen][sizelarge]接着上次,散仙所写的[urlhttp://qindongliang.iteye.com/blog/2200400]文章[/url],在Win7上的eclipse中使用Apache Hadoop2.2.0对接CDH5.3的Hadoop2.5调试时,很顺利,所有的问题全部KO,今天散…
大数据学习(16)-mapreduce详解
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…
Hadoop:MapReduce概述、WordCount
MapReduce概述
MapReduce是Hadoop的两大核心技术之一,HDFS解决了大数据存取问题,而MapReduce是对大数据的高效并行编程模型。
MapReduce任务分为两个阶段:map与reduce;每阶段都是以键值对(key-value)作为输入和输出的࿱…
MapReduce编程:检索特定群体搜索记录和定义分片操作
文章目录 MapReduce 编程:检索特定群体搜索记录和定义分片操作一、实验目标二、实验要求及注意事项三、实验内容及步骤 附:系列文章 MapReduce 编程:检索特定群体搜索记录和定义分片操作
一、实验目标
熟悉MapReduce编程涉及的主要类和接口…
大数据学习(6)-hive底层原理Mapreduce
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
MapReduce任务的优化
1、任务调度
任务调度是Hadoop中非常重要的一环,这个优化又涉及两个方面的内容。计算方面:Hadoop总会优先将任务分给空闲的机器,使得所有任务能公平地分享系统资源。IO方面:Hadoop会尽量将Map任务分配给InputSplit所在的机器&…
dubbo性能测试报告
测试说明
a、本次性能测试,测试了dubbo2.0所有支持的协议在不同大小和数据类型下的表现,并与dubbo1.0进行了对比。
b、整体性能相比1.0有了提升,平均提升10%,使用dubbo2.0新增的dubbo序列化还能获得10%~50%的性能提升࿰…
Hadoop3教程(七):MapReduce概述
文章目录 (68) MR的概述&优缺点(69)MR的核心思想MapReduce进程 (70)官方WC源码&序列化类型(71)MR的编程规范MapperReducerDriver (72)WordCount案例需…

Mapreduce小试牛刀(1)
1.与hdfs一样,mapreduce基于hadoop框架,所以我们首先要启动hadoop服务器
---------------------------------------------------------------------------------------------------------------------------------
2.修改hadoop-env.sh位置JAVA_HOME配…

云计算与大数据之间的羁绊(期末不挂科版):云计算 | 大数据 | Hadoop | HDFS | MapReduce | Hive | Spark
文章目录 前言:一、云计算1.1 云计算的基本思想1.2 云计算概述——什么是云计算?1.3 云计算的基本特征1.4 云计算的部署模式1.5 云服务1.6 云计算的关键技术——虚拟化技术1.6.1 虚拟化的好处1.6.2 虚拟化技术的应用——12306使用阿里云避免了高峰期的崩…

Linux使用Eclipse编写WordCount时没有out结果
创作不易,转载请注明出处 文章目录一、报错信息二、原因分析三、解决方法另附一、报错信息
2020-12-05 18:22:17,680 WARN util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... usi…
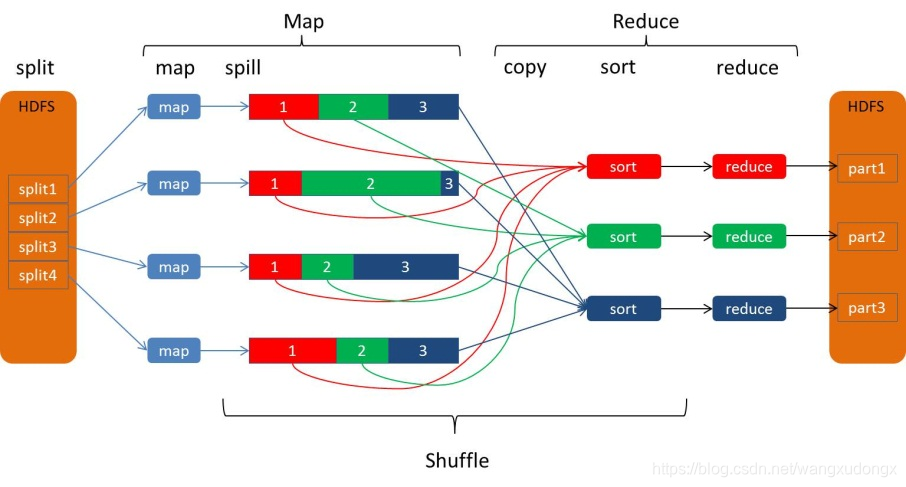
Hadoop系列文章 Hadoop架构、原理、特性简述
Hadoop系列文章 Hadoop架构、原理、特性简述Hadoop HDFSHDFS介绍HDFS架构图HDFS写入数据流程图HDFS读取数据流程图数据块的副本集Hadoop YARNYARN工作流程图YARN的原理及目标Hadoop MapReduceMapReduce工作流程MapReduce编程模型Apache™Hadoop项目开发用于可靠、可伸缩的分布式…
如何处理 Flink 作业中的数据倾斜问题?
分析&回答
什么是数据倾斜?
由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。
举例:一个 Flink 作业包含 200 个 Task 节点,其中有 199 个节点可以在很短的时间内完成计算。但是有一个节点执行时间…
hadoop 学习:mapreduce 入门案例一:WordCount 统计一个文本中单词的个数
一 需求
这个案例的需求很简单
现在这里有一个文本wordcount.txt,内容如下 现要求你使用 mapreduce 框架统计每个单词的出现个数
这样一个案例虽然简单但可以让新学习大数据的同学熟悉 mapreduce 框架 二 准备工作
(1)创建一个 maven 工…
面向未来的大数据核心技术都有什么?
1、数据采集
数据采集的任务就是把数据从各种数据源中采集和存储到数据存储上,期间有可能会做一些简单的清洗。数据源的种类比较多:
网站日志:作为互联网行业,网站日志占的份额最大,网站日志存储在多台网站日志服务器…
大数据讲课笔记5.1 初探MapReduce
文章目录 零、学习目标一、导入新课二、新课讲解(一)MapReduce核心思想(二)MapReduce编程模型(三)MapReduce编程实例——词频统计思路1、Map阶段(映射阶段)2、Reduce阶段(…
[转]HDFS+MapReduce+Hive+HBase十分钟快速入门
HDFS还从没部署过,算是把这篇文章暂留吧。 HDFSMapReduceHiveHBase十分钟快速入门 易剑 2009-8-19 1. 前言 本文的目的是让一个从未接触Hadoop的人,在很短的时间内快速上手,掌握编译、安装和简单的使用。 2. Hadoop家族 截止2009-8-19日…
专利引用关系数据集分析
专利引用关系数据集分析这次实验的两个题目,一个可以由词频统计代码改编,一个由倒排索引改编,改编的重点是将每一排的两个输入分开。 输出专利被引用次数统计结果: 根据题目要求需要输出被引用的专利和它的次数,在word…
从wordcount词频统计代码到倒排索引的改编
从wordcount词频统计代码到倒排索引的改编 分析word count代码 Map中输出了单词和intwriteable类的对象one,而倒排索引,需要输出单词和文件名偏移,偏移是key中含有的,使用.tostring方法就可以将它变成字符串与文件名和连接。要输出…
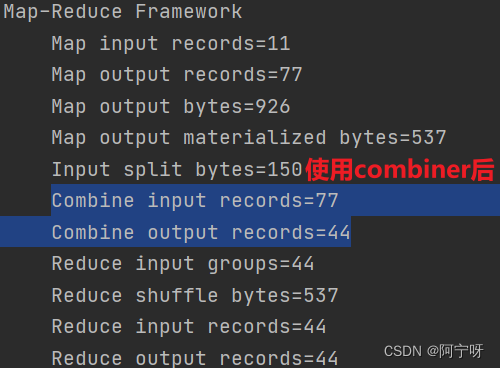
【大数据之Hadoop】十四、MapReduce之Combiner合并
Combiner是Mapper和Reducer之间的组件,其组件的父类是Reducer。
Combiner和Reducer的区别: Combiner是运行在每一个MapTask所在的节点,即对每一个MapTask的输出进行局部汇总,减少网络传输量。 Reducer则是接收全局是Mapper的输出…
Hadoop之MapReduce 详细教程
MapReduce仅作了解,生产上很少使用该计算程序
1、MapReduce介绍
MapReduce 思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。即使是…
MongoDB基本语法及其相关操作
一、MongoDB
MongoDB是一个基于分布式文件的存储的开源数据库系统。MongoDB具有以下特点:
MongoDB 是一个面向文档存储的数据库。你可以在MongoDB记录中设置任何属性的索引 来实现更快的排序。你可以通过本地或者网络创建数据镜像。如果负载的增加(需要…

MapReduce 读写数据库
MapReduce 读写数据库 经常听到小伙伴吐槽 MapReduce 计算的结果无法直接写入数据库, 实际上 MapReduce 是有操作数据库实现的 本案例代码将实现 MapReduce 数据库读写操作和将数据表中数据复制到另外一张数据表中 准备数据表
create database htu;
use htu;
creat…
Hadoop3教程(九):MapReduce框架原理概述
文章目录 简介参考文献 简介
这属于整个MR中最核心的一块,后续小节会展开描述。
整个MR处理流程,是分为Map阶段和Reduce阶段。
一般,我们称Map阶段的进程是MapTask,称Reduce阶段是ReduceTask。
其完整的工作流程如图ÿ…
MapReduce编程:join操作和聚合操作
文章目录 MapReduce 编程:join操作和聚合操作一、实验目标二、实验要求及注意事项三、实验内容及步骤 附:系列文章 MapReduce 编程:join操作和聚合操作
一、实验目标
理解MapReduce计算框架的分布式处理工作流程掌握用mapreduce计算框架实现…

MapReduce 序列化案例
文章目录MapReduce 序列化案例一、案例需求二、案例分析map 阶段Reduce 阶段三、代码实现1、编写流量统计的Bean对象2、Mapper阶段代码3、Reduce 阶段代码4、Driver 阶段代码MapReduce 序列化案例
一、案例需求
1、需求: 统计每一个手机号耗费的总上行流量&#x…

4.MapReduce 序列化
目录 概述序列化序列化反序例化java自带的两种Serializable非Serializable hadoop序例化实践 分片/InputFormat & InputSplit日志 结束 概述
序列化是分布式计算中很重要的一环境,好的序列化方式,可以大大减少分布式计算中,网络传输的数…

看看人家那高并发秒杀系统,那叫一个优雅
618,大家剁手了么?
说起618,就不得不提其中较为复杂的秒杀环节了。虽说秒杀只是一个促销活动,但对技术要求不低。
秒杀作为618、双十一等电商活动不可缺少的一环,是一个非常典型的活动场景。秒杀场景的业务特点是限时…
基于MapReduce的Hive数据倾斜场景以及调优方案
文章目录 1 Hive数据倾斜的现象1.1 Hive数据倾斜的场景1.2 解决数据倾斜问题的优化思路 2 解决Hive数据倾斜问题的方法2.1 开启负载均衡2.2 引入随机性2.3 使用MapJoin或Broadcast Join2.4 调整数据存储格式2.5 分桶表、分区表2.6 使用抽样数据进行优化2.7 过滤倾斜join单独进行…
MongoDB更新文档
3.4 MongoDB更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。
update() 更新
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(<query>,<update>,{upsert: <boolean>,multi: <boolean>,wri…
MapReduce 初级编程实践
(一)编程实现文件合并和去重操作**
对于两个输入文件,即文件 A 和文件 B,请编写 MapReduce 程序,对两个文件进行合并, 并剔除其中重复的内容,得到一个新的输出文件 C。下面是输入文件和输出文件的一个样例供参考。
输入文件 A 的样例如下:
20170101 x
20170102 y
2…

大数据周会-本周学习内容总结07
目录
01【hadoop】
1.1【编写集群分发脚本xsync】
1.2【集群部署规划】
1.3【Hadoop集群启停脚本】
02【HDFS】
2.1【HDFS的API操作】
03【MapReduce】
3.1【P077- WordCount案例】
3.2【P097-自定义分区案例】
历史总结 01【hadoop】
1.1【编写集群分发脚本xsync】…

MIT6.824 Spring2021 Lab 1: MapReduce
文章目录 0x00 准备0x01 MapReduce简介0x02 RPC0x03 调试0x04 代码coordinator.gorpc.goworker.go 0x00 准备
阅读MapReduce论文配置GO环境
因为之前没用过GO,所以 先在网上学了一下语法A Tour of Go
感觉Go的接口和方法的语法和C挺不一样, 并发编程也挺有意思
0x01 MapRed…

【Spark SQL】2、YARN的学习
YARN概述 YARN的基本思想是将资源管理和作业调度/监视的功能分解为单独的守护进程。我们的想法是拥有一个全局ResourceManager(RM)和每个应用程序ApplicationMaster(AM)。应用程序可以是单个作业,也可以是作业的DAG。 …
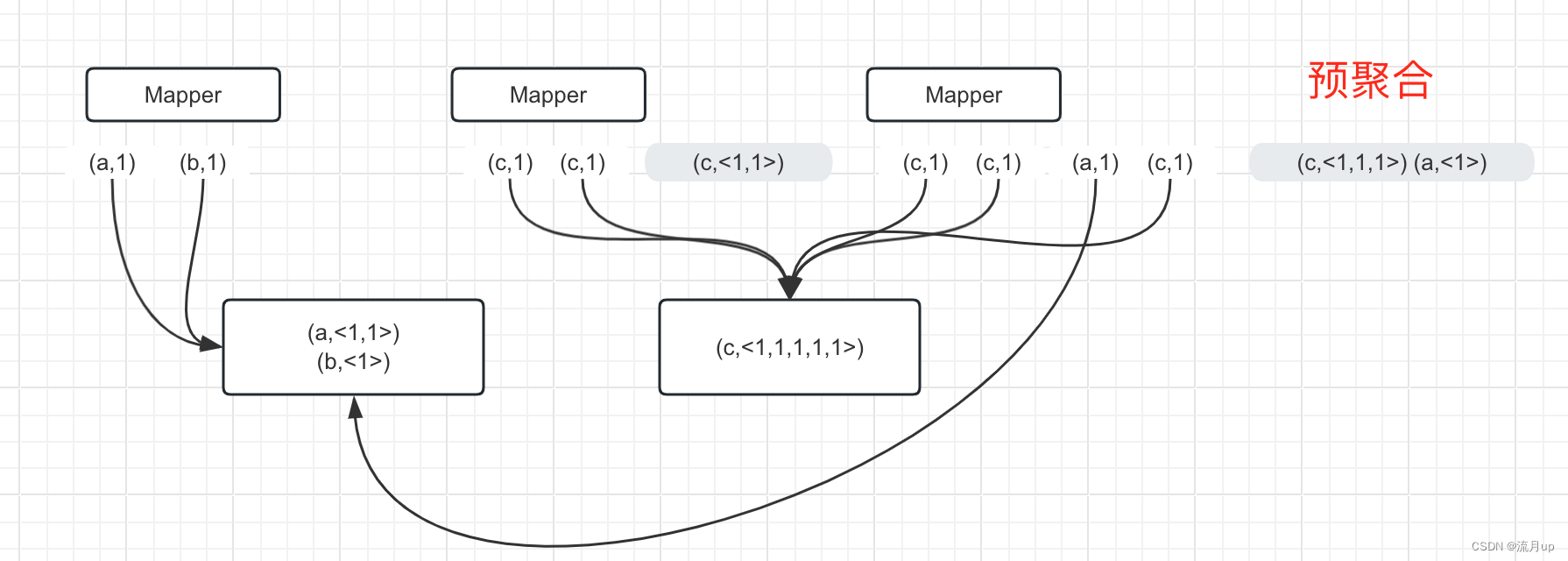
5.MapReduce之Combiner-预聚合
目录 概述本地预计算 Combiner 意义实践前提代码日志观察 结束 概述
在 MR、Spark、Flink 中,常用的减少网络传输的手段。 通常在 Reducer 端合并,shuffle 的数据量比在 Mapper 端要大,根据业务情况及数据量极大时,将大幅度降低效…
解析Hadoop三大核心组件:HDFS、MapReduce和YARN
目录 HadoopHadoop的优势 Hadoop的组成HDFS架构设计Yarn架构设计MapReduce架构设计 总结 在大数据时代,Hadoop作为一种开源的分布式计算框架,已经成为处理大规模数据的首选工具。它采用了分布式存储和计算的方式,能够高效地处理海量数据。Had…
IDEA 打包MapReduce程序到集群运行的两种方式以及XShell和Xftp过期的解决
参考博客
【MapReduce打包成jar上传到集群运行】http://t.csdn.cn/2gK1d
【Xshell7/Xftp7 解决强制更新问题】http://t.csdn.cn/rxiBG
IDEA打包MapReduce程序(方式一)【轻量级打包】
这里的打包是打包整个项目,后期等学会怎么打包单个指定…
MapReduce实现KNN算法分类推测鸢尾花种类
文章目录 代码地址一、KNN算法简介二、KNN算法示例:推测鸢尾花种类三、MapReduceHadoop实现KNN鸢尾花分类:1. 实现环境2.pom.xml 3.设计思路及代码1. KNN_Driver类2. MyData类3. KNN_Mapper类 4. KNN_Reducer类 代码地址
https://gitcode.net/m0_567453…
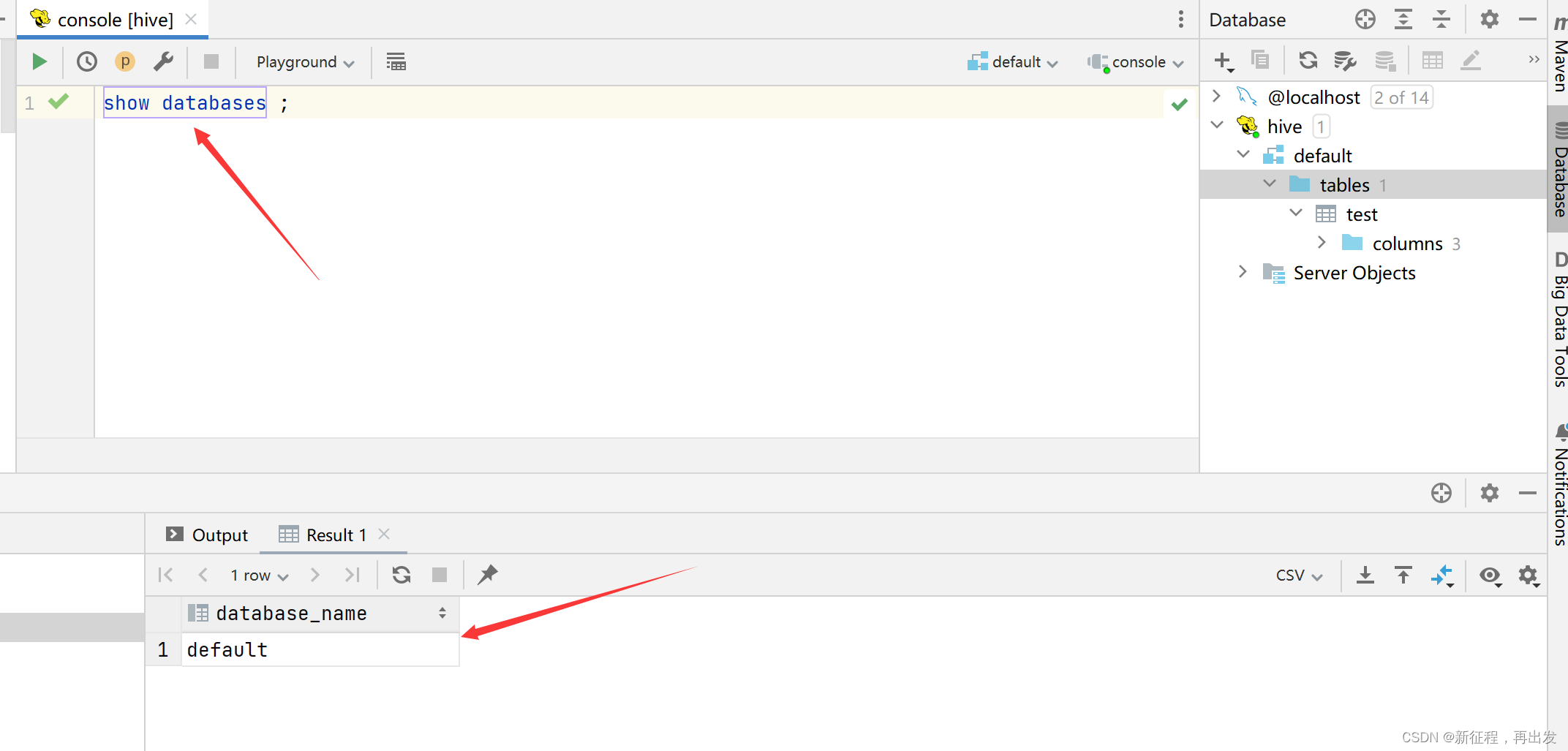
Hive部署,hive客户端
1、Hive部署
Hive是分布式运行的框架还是单机运行的?
Hive是单机工具,只需要部署在一台服务器即可。Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
1.1、规划
我们知道Hive是单机工具后,就需要准备一台服务…
0301yarnmapredude入门-hadoop-大数据学习
文章目录 1 MapReduce概述2 YARN2.1 yarn概述2.2 yarn与MapReduce关系2.3 yarn架构2.4 辅助角色 3 MapReduce & YARN部署3.1 集群规划3.2 配置文件3.3 分发配置文件 4 体验4.1 集群启动命令介绍4.2 提交MapReduce任务到YARN执行 结语 1 MapReduce概述
分布式计算是一种计算…
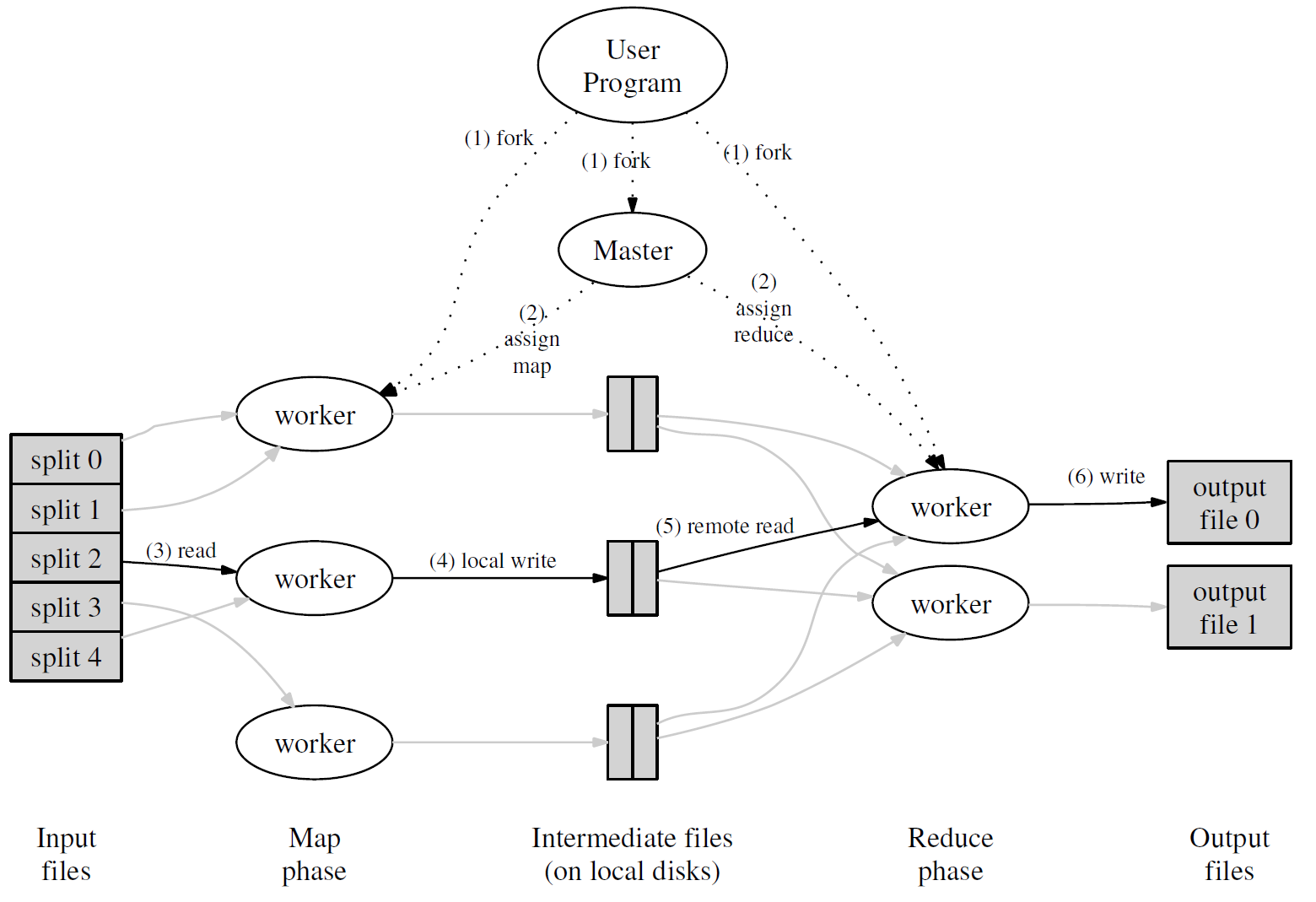
Google MapReduce 总结
Google MapReduce 总结
MapReduce 编程模型
总的来讲,Google MapReduce 所执行的分布式计算会以一组键值对作为输入,输出另一组键值对,用户则通过编写 Map 函数和 Reduce 函数来指定所要进行的计算。
由用户编写的Map 函数将被应用在每一个…
Hadoop3 - MapReduce ORC 列式存储
一、列式存储
常见的 DB 数据库,大多都是行式存储系统,比如 MySql,Oracle 等,利于数据一行一行的写入,所以数据的写入会更快,对按行查询数据也更简单。但是像现在常见的 HBase 存储大数据确使用的列式存储…
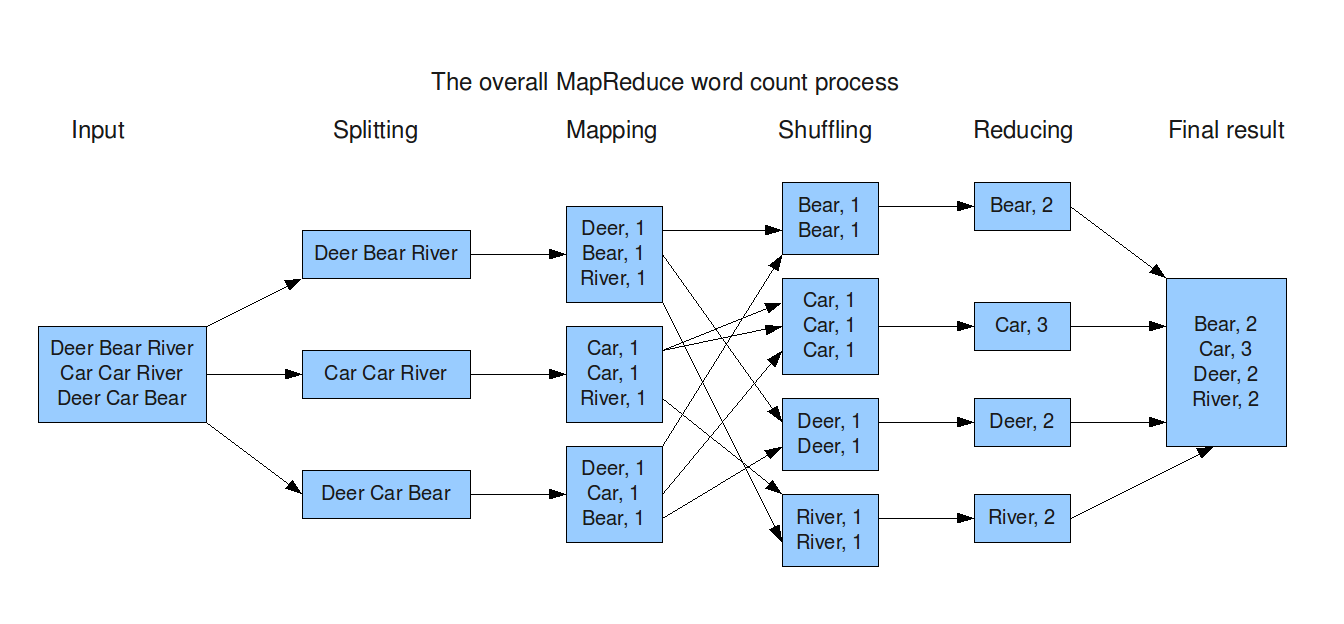
大数据 - MapReduce:从原理到实战的全面指南
本文深入探讨了MapReduce的各个方面,从基础概念和工作原理到编程模型和实际应用场景,最后专注于性能优化的最佳实践。 一、引言 1.1 数据的价值与挑战 在信息爆炸的时代,数据被视为新的石油。每天都有数以百万计的数据被生成、存储和处理&…
大数据学习(18)-任务并行度优化
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…

Hadoop——分布式计算MapReduce和资源调度Yarn
分布式计算 MapReduce YARN架构 YARN集群部署 一、Hadoop安装目录下/etc/hadoop修改mapred-env配置文件,mapred-site.xml文件 二、etc/hadoop文件内,修改yarn-env.sh,yarn-site.xml
三、将配置好的文件分发到其他服务节点
start-dfs.…

MapReduce 例子:WordCount
MapReduce 简单应用
WordCount是MapReduce编程中最经典的例子,主要用于统计文本中单词出现的个数。比如将下述文本作为输入对象
hello world
hello java
hello python
hello php
hello scala
经过执行之后,便会得到下述结果
hello 5
java 1
php…
Hadoop大数据实战(二)--ubtuntu14.0安装Hadoop最全教程
目录1.安装jdk2.下载Hadoop3.设置Hadoop环境变量4.Hadoop配置文件设置5.创建并格式化 hdfs目录6.关闭防火墙7.启动Hadoop8.打开Hadoop web界面1.安装jdk
步骤1:启动终端:使用快捷键 CtrlAltT启动。也可以单击快捷工具栏的“终端”程序图标来启动。
步骤…
测试环境搭建整套大数据系统(三:搭建集群zookeeper,hdfs,mapreduce,yarn,hive)
一:搭建zk https://blog.csdn.net/weixin_43446246/article/details/123327143 二:搭建hadoop,yarn,mapreduce。
1. 安装hadoop。
sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt2. 修改java配置路径。
cd /opt/hadoop-3.2.4/etc…
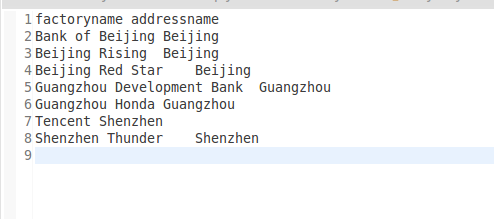
Hadoop 多表关联
一、实例描述 多表关联和单表关联类似,它也是通过对原始数据进行一定的处理,从其中挖掘出关心的信息。下面进入这个实例。 输入是两个文件,一个代表工厂表,包含工厂名列和地址编号列;另一个代表地址列,包含…

十四、YARN核心架构
1、目标
(1)掌握YARN的运行角色和角色之间的关系
(2)理解使用容器做资源分配和隔离
2、核心架构
(1)和HDFS架构的对比
HDFS架构: YARN架构:(主从模式) &…
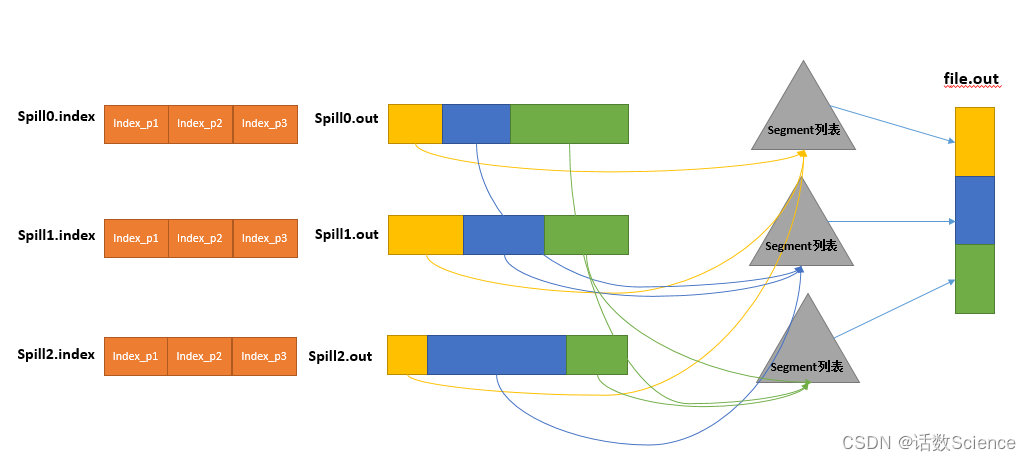
【Spark精讲】Spark与MapReduce对比
目录
对比总结
MapReduce流程
编辑
MapTask流程
ReduceTask流程
MapReduce原理
阶段划分
Map shuffle
Partition
Collector
Sort
Spill
Merge
Reduce shuffle
Copy
Merge Sort 对比总结
Map端读取文件:都是需要通过split概念来进行逻辑切片&…
MapReduce常用参数调优
一、资源相关参数
mapred-default.xml
配置参数参数说明mapreduce.map.memory.mb一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。mapreduce.reduce.memory.mb一个Redu…
计算机专业面试笔试问题之大数据量,海量数据 处理方法总结
大数据量的问题是很多面试笔试中经常出现的问题,比如baidu google 腾讯 这样的一些涉及到海量数据的公司经常会问到。 下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方…
MapReduce计算广州2022年每月最高温度
目录
数据集
1.查询地区编号
2.数据集的下载
编写MapReduce程序输入格式
输出格式
Mapper类
确定参数
代码
Reducer类
思路
代码
Runner类
运行结果 数据集
1.查询地区编号
NCDC是美国国家气象数据中心的缩写,是一个负责收集、存储和分发全球气象和气…
Eclipse搭建Hadoop环境及实战资源分享
首先搭建eclipse的haoop2.7.1开发环境,使用的资源链接如下:
windows安装hadoop2.7.1环境
eclipse下搭建hadoop开发环境
这样我们就可以在eclipse进行hadoop开发了 目录
一、MapReduce 模型简介
1.Map 和 Reduce 函数
2.MapR…

巴尔加瓦算法图解:算法运用。
树
如果能将用户名插入到数组的正确位置就好了,这样就无需在插入后再排序。为此,有人设计了一种名为二叉查找树(binary search tree)的数据结构。
每个node的children 都不大于两个。对于其中的每个节点,左子节点的值都比它小,…
【MapReduce】02.Hadoop序列化
实现bean对象序列化步骤 自定义bean对象实现序列化接口。
1)必须实现Writable接口
2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean(){super();
}
3)重写序列化方法
Override
public …
Hadoop3 - MapReduce DB 操作
一、MapReduce DB 操作
对于本专栏的前面几篇文章的操作,基本都是读取本地或 HDFS 中的文件,如果有的数据是存在 DB 中的我们要怎么处理呢?
Hadoop 为我们提供了 DBInputFormat 和 DBOutputFormat 两个类。顾名思义 DBInputFormat 负责从数…
Hadoop3 - MapReduce SequenceFile 、MapFile 格式存储
一、MapReduce 小文件问题
上篇文章说 MapReduce 并行机制时,讲到如果是针对小于 block 的小文件的话,会每个拆分成一个 MapTask 导致对大量小文件的处理,另外 HDFS 对大量小文件的存储效率其实也是不高,MapReduce在读取小文件进…
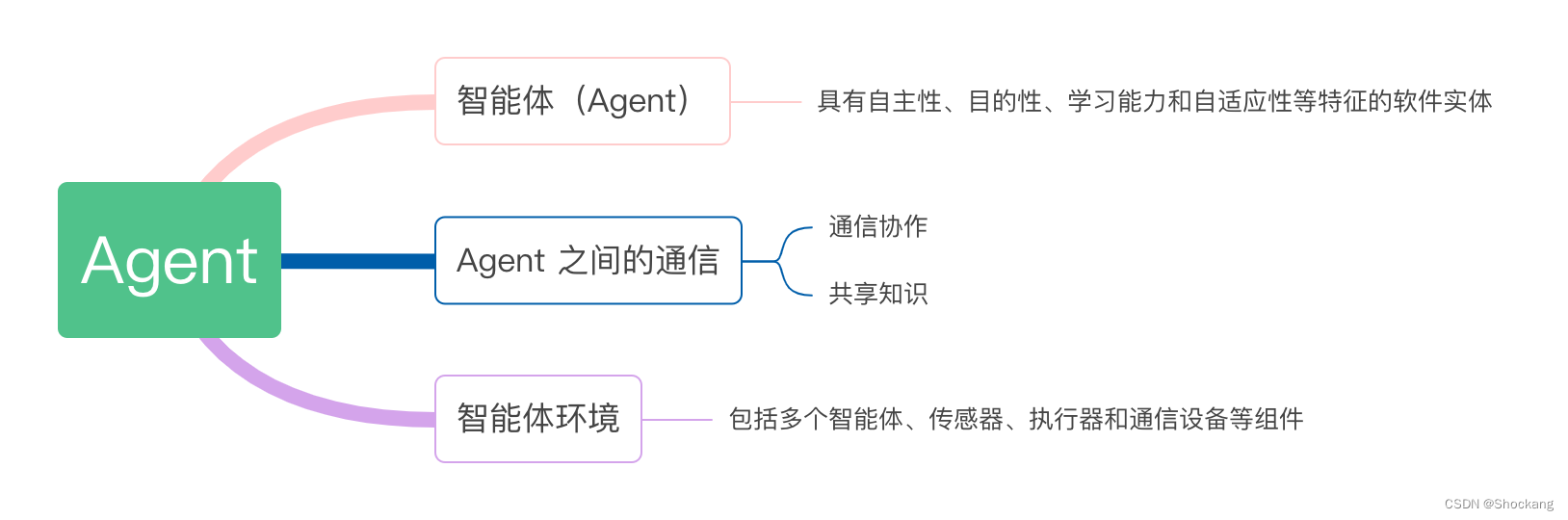
分布式计算模型详解:MapReduce、数据流、P2P、RPC、Agent
前言
本文隶属于专栏《大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据理论体系 思维导图 MapReduce
MapReduce 是一种分布式计算模…
MapReduce:Combiner与Shuffle阶段之Reducer输入
目录
Combiner
Reducer的输入
过程概述
源码分析
ReduceTask总览
数据抓取
合并排序 Combiner
网络I/O会限制MR作业的数量,因此尽量避免mapper和reducer任务之间的数据传输是有利的。在之前Shuffle阶段之Mapper输入中可以看到,会调用两次Combine…
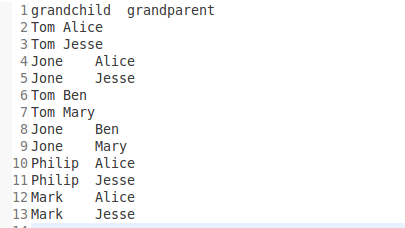
Hadoop 单表关联
前面的实例都是在数据上进行一些简单的处理,为进一步的操作打基础。单表关联这个实例要求从给出的数据中寻找到所关心的数据,它是对原始数据所包含信息的挖掘。下面进入这个实例。
1.实例描述 实例中给出child-parent表,要求输出grandchild-…
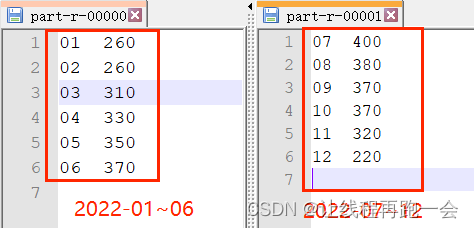
MapReduce【自定义分区Partitioner】
实际开发中我们可能根据需求需要将MapReduce的运行结果生成多个不同的文件,比如上一个案例【MapReduce计算广州2022年每月最高温度】,我们需要将前半年和后半年的数据分开写到两个文件中。
默认分区
默认MapReduce只能写出一个文件: 因为我…
![[Hadoop]MapReduce与YARN](https://img-blog.csdnimg.cn/3e30448c90074f74b9ee4196accc5b10.png)
[Hadoop]MapReduce与YARN
目录
大数据导论与Linux基础
Apache Hadoop、HDFS
MapReduce
MapReduce思想
MapReduce设计构思
MapReduce介绍
MapReduce官方实例
Map阶段执行流程
Reduce阶段执行流程
shuffle机制
YARN
YARN介绍
YARN架构、组件
程序提交YARN交互流程
YARN资源调度器Scheduler…

彷徨 | Hadoop之MapReduce个人浅谈
MapReduce是分布式运算编程框架,Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上
为什么要MAPREDUCE
(1)海量数据在单机上处理因为硬件资源限制,无法胜任…
MapReduce全局共享数据
由于继承Mapper基类的Map阶段类和继承Reducer基类的Reduce阶段类的运行都是独立的,并不像代码看起来那样会共享同一个Java虚拟机的资源,所以不能直接使用代码级别的全局变量。下面介绍几种在MapReduce编程中相对有效的设置全局变量的方法。 1、读写HDFS文…
彷徨 | MapReduce实例五 | MapReduce求TopN的三种方法 , 以电影数据为例
本文采用三种方式对movie数据进行TopN排序 第一种是直接排序,在ReduceTask中进行排序 第二种是利用Tree排序,该方式利用小顶堆和集合重复原理的方式 , 每过来一个数据 , 跟堆顶数据进行比较 , 如果比最小的大 , 则 踢掉换新的 , 否则直接跳过数据 . 以此对数据进行排序 . 第三…
Hadoop Map/Reduce实现细节
分布式计算(Map/Reduce),同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架。在Hadoop中,分布式文件系统,很大程度上,是为各种分布式计算需求所服务的。我们说分布式文件系统就是加了分布式的文件系统,类似的定义推广到

彷徨 | MapReduce实例四 | 统计每个单词在每个文件里出现的次数
示例:一个目录下有多个文件,每个文件里有相同的单词,统计每个单词在每个文件里出现的次数
即同一个单词在不同文件下的词频统计
文件目录如下: 各文件内容片断: 要求结果如下:及同一个单词在不同文件下的词频统计 思路:
第一步:我们可以先将单词和文件名作为key,将出现次数作…
Apache Pig学习笔记之内置函数(三)
[img]http://dl2.iteye.com/upload/attachment/0105/3491/7c7b3bef-0dda-3ac6-8cdb-1ecc1dd9c194.jpg[/img]1 简介
Pig附带了一些的内置函数,这些函数包括(转换函数,加载和存储函数,数学函数,字符串函数,以…

Apache Pig入门学习文档(一)
1,Pig的安装 (一)软件要求 (二)下载Pig (三)编译Pig 2,运行Pig (一)Pig的所有执行模式 (二)pig的交互式模式 (三&#x…

MapReduce全排序和二次排序
排序是MapReduce框架中最重要的操作之一。MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。对于MapTask…
Apache Pig5行代码怎么实现Hadoop的WordCount?
[img]http://dl2.iteye.com/upload/attachment/0105/1908/1805d55c-2b7f-3246-b732-02121f8698ac.jpg[/img][b][colorgreen][sizelarge]初学编程的人,都知道hello world的含义,当你第一次从控制台里打印出了hello world,就意味着,…
MapReduce 基础之:图文讲解 MapReduce 工作原理
图文讲解 MapReduce 工作原理理解什么是map,什么是reduce,为什么叫mapreducemapreduc工作流程分片、格式化数据源执行 MapTask执行 Shuffle 过程执行 ReduceTask写入文件整体流程图MapTaskReduceTask理解什么是map,什么是reduce,为…
如何在CentOS6.5下编译64位的Hadoop2.x
[colorgreen][sizelarge]hadoop2.x在apache官网直接下载的并没有64位直接能用的版本,如果我们想在64位系统使用,那么就需要重新编译hadoop,否则直接使用32位的hadoop运行在64位的系统上,将会出现一些库不兼容的异常。如下图所示&a…
分布式处理框架 MapReduce
3.2.1 什么是MapReduce
源于Google的MapReduce论文(2004年12月)Hadoop的MapReduce是Google论文的开源实现MapReduce优点: 海量数据离线处理&易开发MapReduce缺点: 实时流式计算
3.2.2 MapReduce编程模型 MapReduce分而治之的思想 数钱实例:一堆钞票࿰…
如何基于新API使用Hadoop的Reduce Side Join
[b][colorgreen][sizelarge]上篇,散仙介绍了基于Hadoop的旧版API结合DataJoin工具类和MapReduce实现的侧连接,那么本次,散仙就来看下,如何在新版API(散仙的Hadoop是1.2版本,在2.x的hadoop版本里实现代码一样…
MapReduce原理剖析(深入源码)
文章目录1. 概述1.1 提交任务1.2 初始化作业1.3 任务分配1.4 任务执行1.5 进度和状态更新1.6 作业完成2. 提交任务&切片源码分析2.1 提交任务源码分析2.2 提交核心之切片流程源码分析2.3 FileInputFormat 切片机制2.3.1 切片机制2.3.2 案例分析2.3.3 源码中计算切片大小的公…
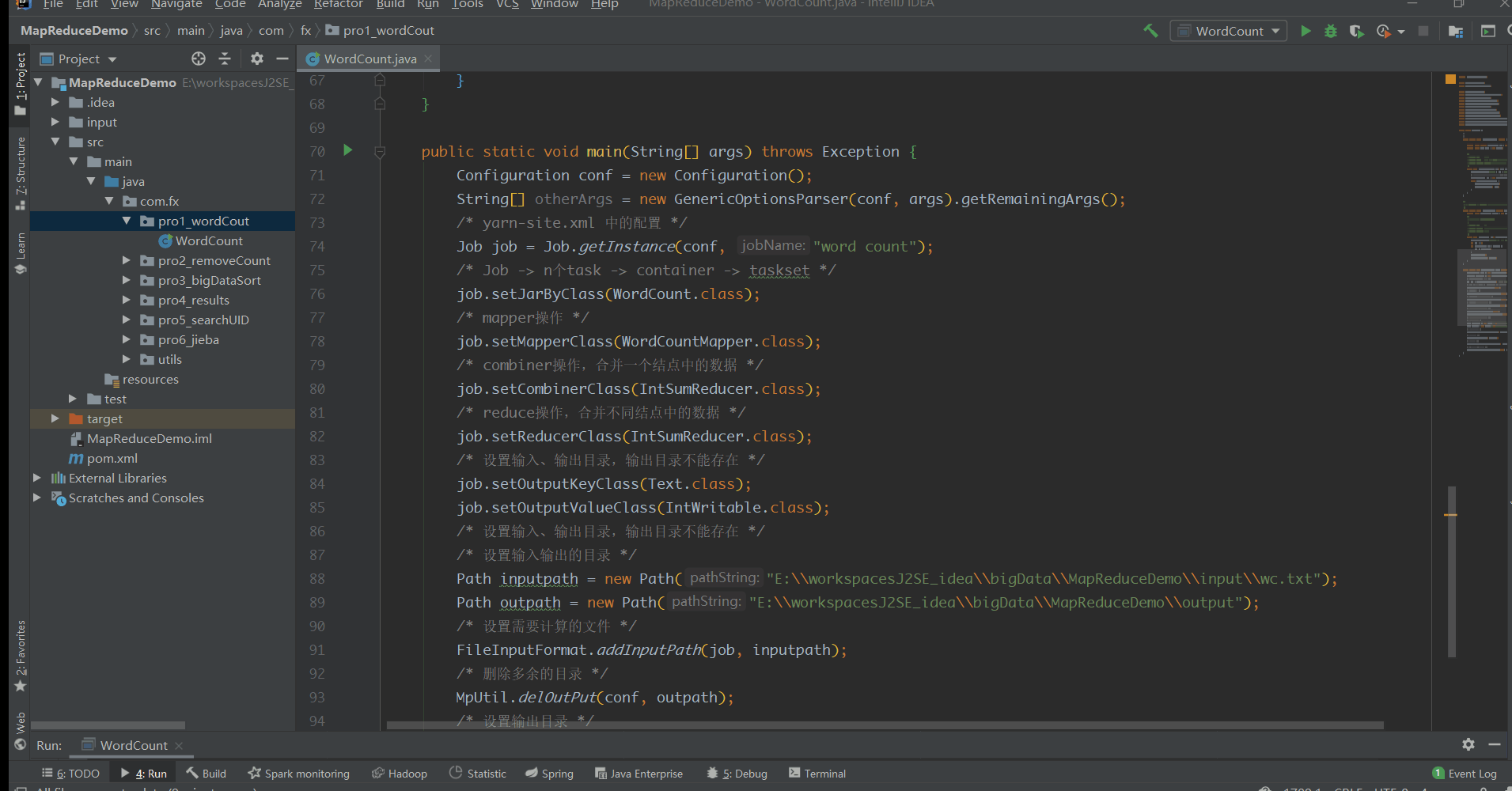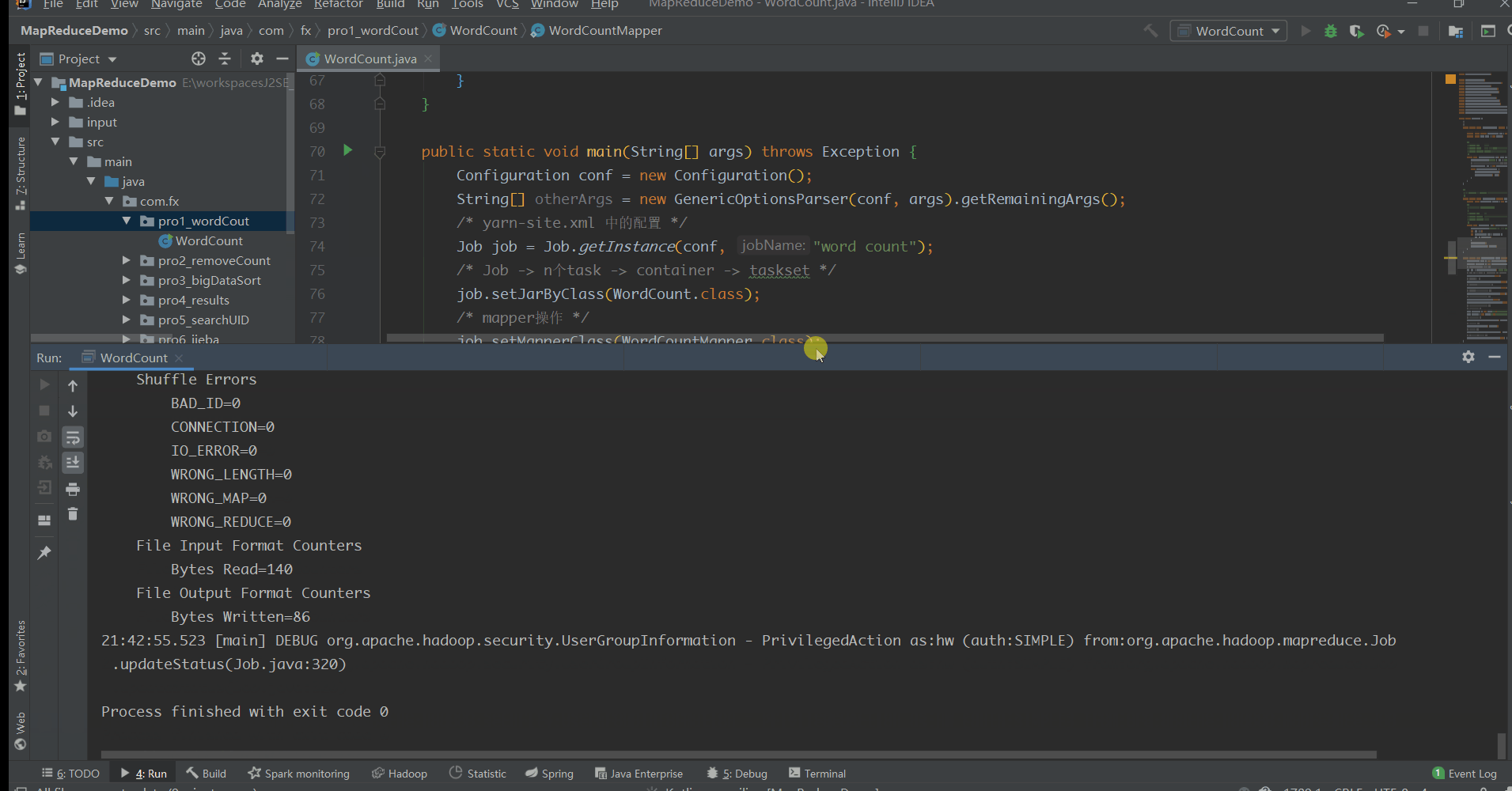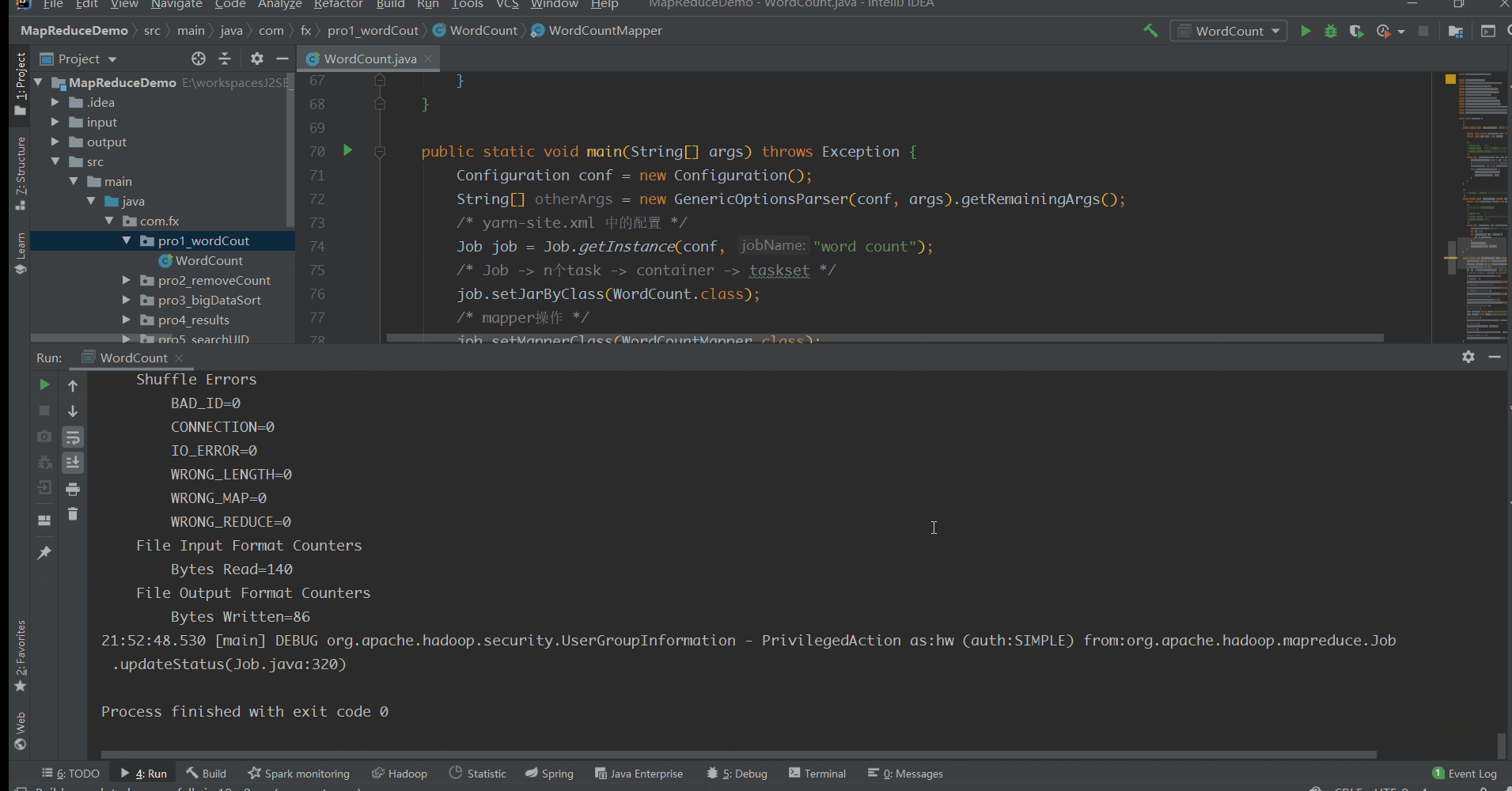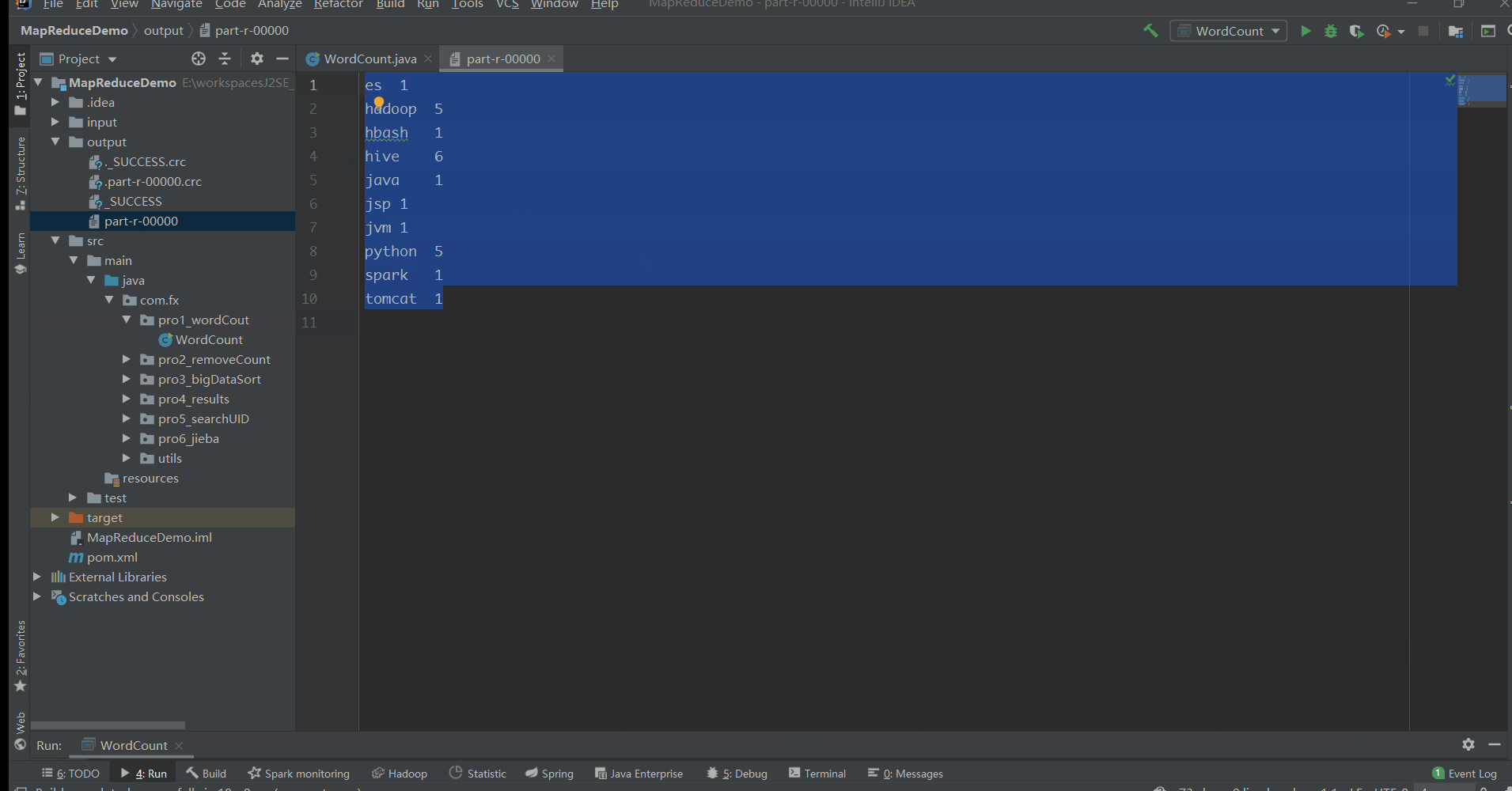
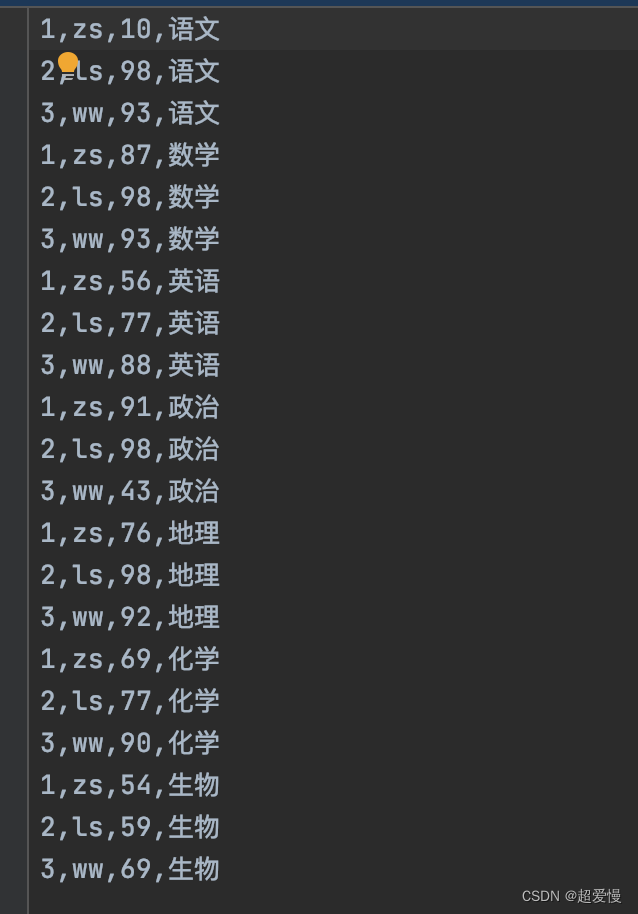
MapReduce实战小案例(自定义排序、二次排序、分组、分区)
文章目录1. MapReduce概念2. 单词计数3. 排序数字4. 🎯求平均成绩5. 天气统计1. MapReduce概念 MapReduce是什么? 我们来看官方文档的解释(我们下载的hadoop中有离线文档:hadoop-2.10.1/share/doc) Hadoop MapReduce 是…
如何使用Hadoop的Reduce Side Join
[b][colorgreen][sizelarge]我们都知道在数据库里,多个表之间是可以根据某个链接键进行join的,这也是数据库的范式规范,通过主外键的关联,由此来减少数据冗余,提高性能。当然近几年,随着NOSQL的兴起&#x…
Map/Reduce执行流程
[b][colorgreen][sizelarge]FileSplit:文件的子集--文件分割体
简介:这篇文档描述在hadoop中map和reduce操作是怎样具体完成的。如果你对Google的MapReduce各式模式不熟悉,请先参阅MapReduce--http://labs.google.com/papers/mapreduce.htmlMap由于Map是…

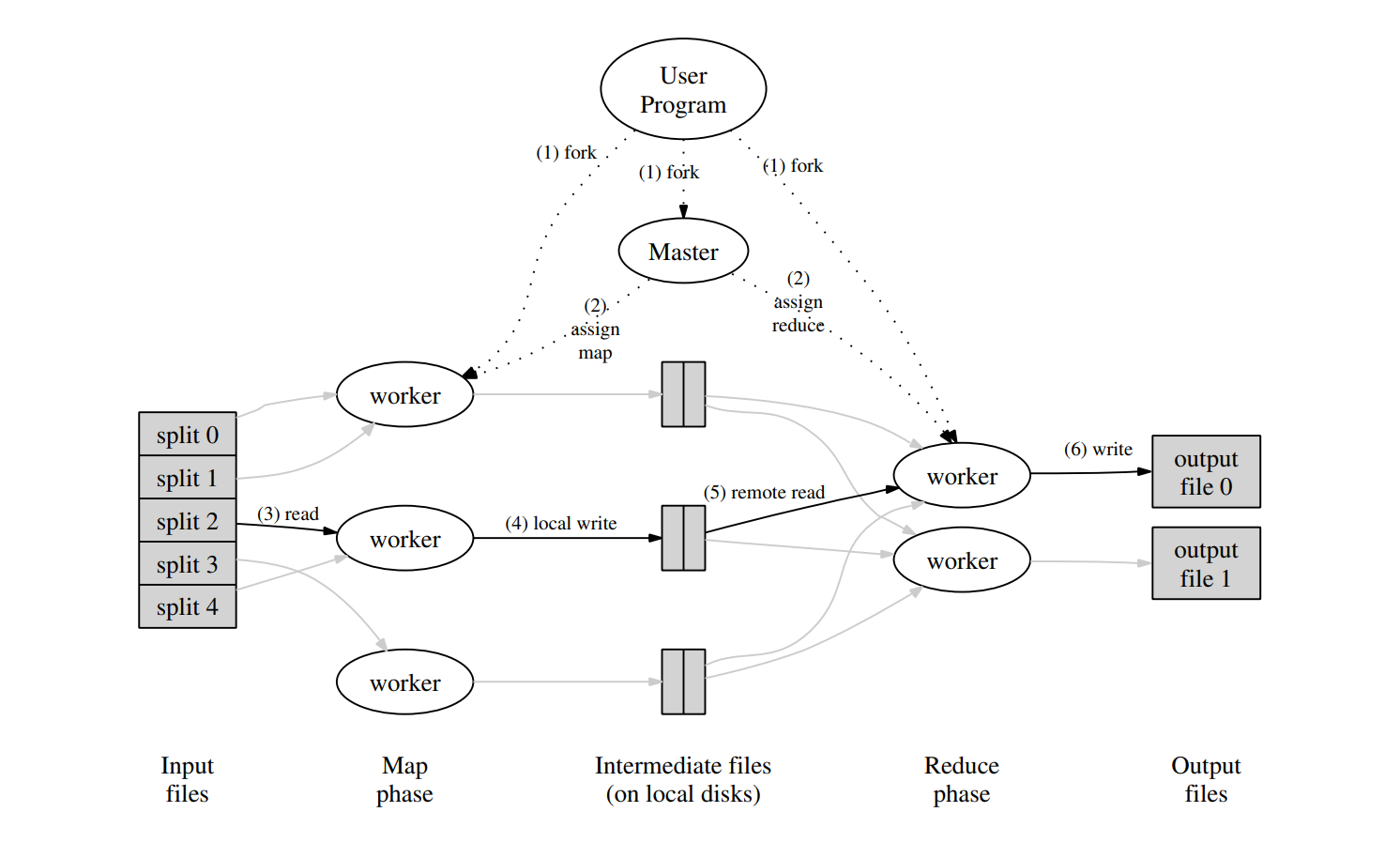
用 Hadoop 进行分布式并行编程, 第 3 部分
一 前言 在本系列文章的第一篇:用 Hadoop 进行分布式并行编程,第 1 部分: 基本概念与安装部署 中,介绍了 MapReduce 计算模型,分布式文件系统 HDFS,分布式并行计算等的基本原理, 并且详细介绍了如何安装…

用 Hadoop 进行分布式并行编程, 第 2 部分
前言 在上一篇文章:“用 Hadoop 进行分布式并行编程 第一部分 基本概念与安装部署”中,介绍了 MapReduce 计算模型,分布式文件系统 HDFS,分布式并行计算等的基本原理, 并且详细介绍了如何安装 Hadoop,如何运行基于 …

Cloudeep对象存储系统简介(1)
Cloudeep 对象存储系统简介 -1 ---- Adam Cloudeep 团队在过去的一段时间,致力于开发一个类似 Amazon S3 ( http://aws.amazon.com/ )和 Google Storage ( http://code.google.com/apis/storage/docs/overview.html &#…
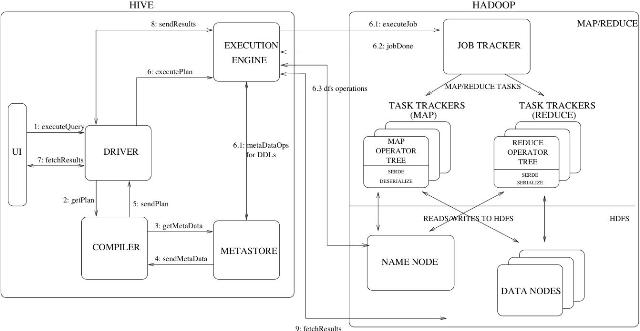
Hive简介和扩展设想
Hive简介和扩展设想
By云深作者:Alen/Adam 2009年6月
转载请注明出处 1. Hive是什么 - Hive是Data Warehouse,Hive不是基于传统数据库上的Data Warehouse,但它能处理的数据量往往比传统数据库要大得多,…
105-120-Hadoop-MapReduce-outputformat:
105-Hadoop-MapReduce-outputformat:
OutputFormat 数据输出,OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了 OutputFormat 接口。下面我们介绍几种常见的OutputFormat实现类。
1.O…
分布式计算模型Mapreduce实践与原理剖析(一)
第一章 MapReduce核心理论
1.1 什么是MapReduce
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据应用” 的核心框架 。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并行运…

大数据技术之Hadoop(MapReduce)
第1章 MapReduce概述
1.1 MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个H…
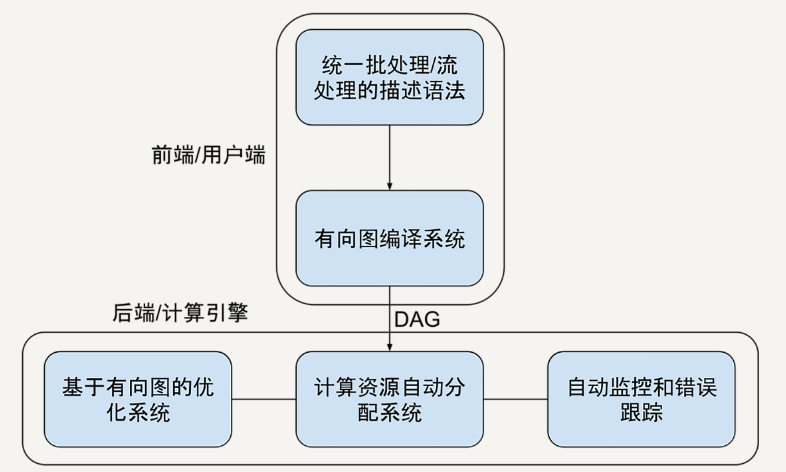
1理想的大数据处理框架设计
以下内容基于极客 蔡元楠老师的《大规模数据处理实战》做的笔记哈。感兴趣的去极客看蔡老师的课程即可。
MapReduce 缺点
高昂的维护成本
因为mapreduce模型只有map和reduce两个步骤。所以在处理复杂的架构的时候,需要协调多个map任务和多个reduce任务。
例如计…

Hadoop开启Yarn的日志监控功能
1.开启JobManager日志
(1)编辑NameNode配置文件${hadoop_home}/etc/hadoop/yarn-site.xml和mapred-site.xml 编辑yarn-site.xml
<!-- Site specific YARN configuration properties -->
<configuration><property><name>yarn.…
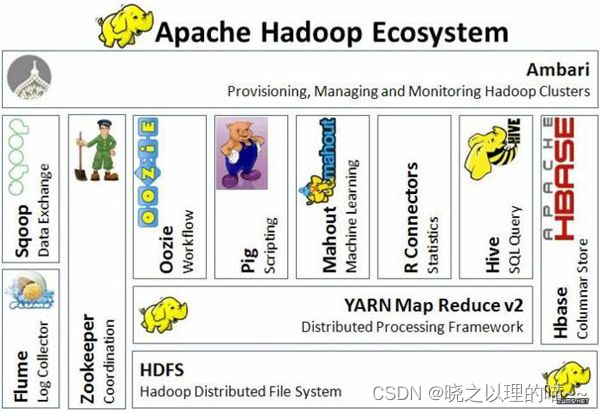
Hadoop核心组成和生态系统简介
一、Hadoop的概念 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System)&am…
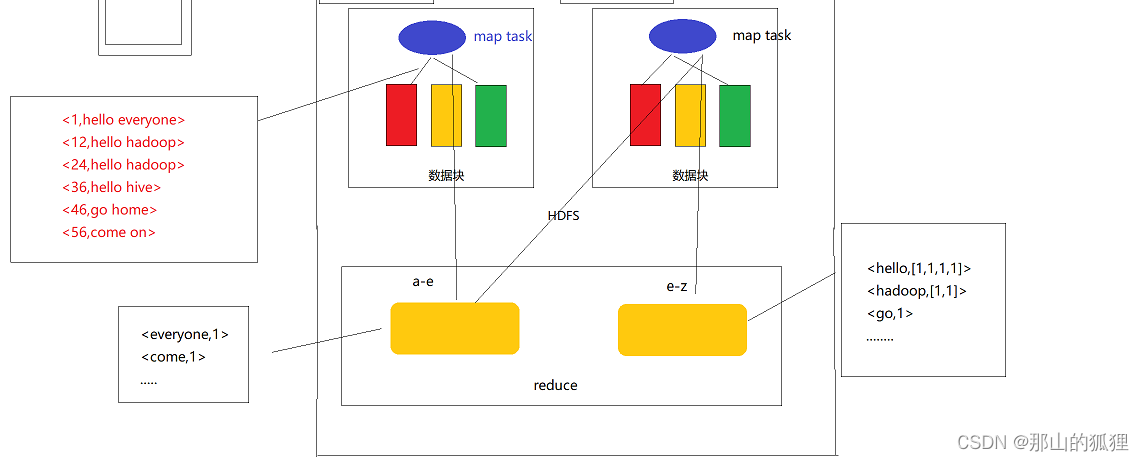
Hadoop中单词统计案例
需要的软件和工程代码下载地址:
Hadoop中单词统计案例(访问密码:7567):
https://url56.ctfile.com/d/34653256-48746892-4c8f2e?p7567 https://url56.ctfile.com/d/34653256-48746892-4c8f2e?p7567
一、搭建本地环境
1、…
大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——MapReduce开发总结
在编写MapReduce程序时,需要考虑如下几个方面:
1、输入数据接口:InputFormat
默认使用的实现类是:TextInputFormatTextInputFormat的功能逻辑是:一次读一行文本,然后将该行的起始偏移量作为key࿰…

Hadoop YARN的发展史与详细解析
带有 MapReduce 的 Apache Hadoop 是分布式数据处理的骨干力量。借助其独特的横向扩展物理集群架构和由 Google 最初开发的精细处理框架,Hadoop 在大数据处理的全新领域迎来了爆炸式增长。Hadoop 还开发了一个丰富多样的应用程序生态系统,包括 Apache Pi…
MapReduce生产经验
目录
1 MapReduce跑的慢的原因
2 MapReduce常用调优参数
map阶段
reduce阶段
3 MapReduce数据倾斜问题 1 MapReduce跑的慢的原因
MapReduce程序效率的瓶颈在于两点:
1)计算机性能
CPU、内存、磁盘、网络
2)I/O操作优化
(…

HadoopV1 vs HadaoopV2 (Yarn) hadoop新旧框架对比
Hadoop 新 MapReduce 框架 Yarn 详解 唐 清原, 咨询顾问简介: 本文介绍了 Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理,优势,运作机制和配置方法等;着重介绍新的 yarn 框架相对于原框架的差异及改进&…
Hadoop_HDFS、Hadoop_MapReduce、Hadoop_Yarn 实践 (一)
Hadoop_HDFS、Hadoop_MapReduce、Hadoop_Yarn 实践 (一)
前要:Hadoop3.3.1完全分布式部署请参考此文章:Hadoop3.3.1完全分布式部署
一、Hadoop_HDFS
1、概述、背景、优缺点
1.1、概述
Hadoop Distributed File System,简称 HDFS&…
MapReduce数据倾斜产生的原因及其解决方案
在shuffle的时候,必须在各个节点尚来去相同的key到某个节点尚的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大,就会发生数据倾斜。比如大部分key对饮10条数据,但个别key对应了100万条数…
MapReduce在Zookeeper集群上鉴权失败
MapReduce在Zookeeper集群上鉴权失败 这是zookeeper上的一封邮件问答。内容比较简单,请大家直接查看正文。 我现在使用配置了Kafka的zookeeper集群,这个Kafka没有任何SASL安全配置。另外我还有一个hadoop集群,这个集群使用了另一个配置了安全…

Map Reduce高级篇:Join-Reduce
Join关联操作
背景
在实际的数据库应用中,我们经常需要从多个数据表中读取数据,这时就可以使用SQL语句中的连接(JOIN),在两个或者多个数据表中查询数据。在使用MapReduce框架进行数据查询的过程中,也会涉…

MapReduce 源码分析-1
源码追踪
Class Job
作为使用Java语言编写的MapReduce城西,其入口方法位main方法,在MapReduce Main方法中,整个核心都在围绕着job类,中文称之为作业。
public class WordDriver {public static void main(String[] args) throw…
Hadoop-----WorldCount代码编写、温度案例
WorldCount代码编写
WordCountMapper
package day34.com.doit.demo02;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;pub…

MapReduce 作业状态卡死 ACCEPTED: waiting for AM container to be allocated, launched and register with RM.
前言:配置好了yarn后,跑wordcount的例子,但是一直未完成。web页面查看任务状态为:ACCEPTED: waiting for AM container to be allocated, launched and register with RM. 在web页面查看其状态,如果active nodes为0&am…

Mapreduce案例之---统计手机号耗费的总上行流量、下行流量、总流量
1.需求:
统计每一个手机号耗费的总上行流量、下行流量、总流量
2.数据准备:
2.1 输入数据格式:
时间戳、电话号码、基站的物理地址、访问网址的ip、网站域名、数据包、接包数、上行/传流量、下行/载流量、响应码 2.2 最终输出的数据格式&…
MapReduce【自定义OutputFormat】
MapReduce默认的输出格式为TextOutputFormat,它的父类是FileOutputFormat,即按行来写,且内容写到一个文本文件中去,但是并不能满足我们实际开发中的所有需求,所以就需要我们自定义OutPutFormat。
自定义OutPutFormat
输出数据到…
hadoop之yarn部署
yarn伪分布式部署: 官网要求: YARN on Single Node You can run a MapReduce job on YARN in a pseudo-distributed mode by setting a few parameters and running ResourceManager daemon and NodeManager daemon in addition. The following instruct…
实验四:MapReduce初级编程实践
1.编程实现文件合并和去重操作 对于两个输入文件,即文件A和文件B,编写MapReduce程序,对两个文件进行合并, 并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样 例供参考。 输入文件A的样例如下&#…
mapJoin与reduceJoin
mapreduce中可以实现map端的join以及reduce端的join,我们看下有什么区别。 mapJoin与reduceJoin数据准备reduce joinmap joinhive的map join测试数据准备
有一张订单表(order):
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6三列对应的…

Hadoop MapReduce入门实验:WordCount
环境:ubuntu 18.04, Hadoop 3.3.5 参考资料:Hadoop官网:MapReduce Tutorial 前置工作
运行Hadoop。 参考:单节点模式,集群模式
单节点模式(for first-time users)
在YARN上以pseu…
MongoDB操作_数据库_集合
..........................................................................................................................................................
三、MongoDB操作
3.1 数据库操作
一个mongodb中可以建立多个数据库。
MongoDB的默认数据库为"test…
Eclipse4.2向hadoop2.2提交MR作业异常
[b][colorgreen][sizelarge]之前散仙也用过eclipse直接向hadoop提交MR作业,也提交成功过,这次换了集群环境,提交作业时发现几个异常,特此整理一下,以防后面再出现类似问题。主要的问题的有2个:
第一个问题,…

mongdb系列之最详细基础知识
文章目录mongdb基础简介与其他数据产品的对比基础概念常用的数据类型简单的CIUD高级管道查询 Aggregate高级MapReduce索引设计应用反范式化skip深度分页性能分片Chunk 数据块服务器管理副本集介绍副本集读写集群架构集群选举集群的搭建常用的语句整理mongdb基础
简介
MongoDB…
Hadoop之mapreduce参数大全-4
76.指定在 MapReduce 作业中,哪些输出文件应该在任务失败时保留
mapreduce.task.files.preserve.filepattern 是 Hadoop MapReduce 框架中的一个配置属性,用于指定在 MapReduce 作业中,哪些输出文件应该在任务失败时保留。
在 MapReduce 作…

大数据技术之Hadoop:MapReduce与Yarn概述(六)
目录
一、分布式计算
二、分布式资源调度
2.1 什么是分布式资源调度
2.2 yarn的架构
2.2.1 核心架构
2.2.2 辅助架构 前面我们提到了Hadoop的三大核心功能:分布式存储、分布式计算和资源调度,分别由Hadoop的三大核心组件可以担任。
即HDFS是分布式…
HDU 1004 Let the Balloon Rise(map的使用)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid1004 Let the Balloon Rise Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submission(s): 143275 Accepted Submission(s): 56670 Problem DescriptionContes…
Sqoop1.99.7安装、配置和使用(一)
转载请注明出处:http://blog.csdn.net/u012842205/article/details/52344196 最近被Sqoop2彻底搞蒙了,各种各样的奇怪问题,层出不穷,而且网上资料都没有针对这些问题的,官方文档也有各种各样的不完整描述。一些注意事项…
Hadoop之mapreduce参数大全-7
151.设置客户端与 AM 之间的IPC(Inter-Process Communication)连接在发生超时时的最大重试次数
yarn.app.mapreduce.client-am.ipc.max-retries-on-timeouts 是 Apache Hadoop YARN 中 MapReduce Application Master(AM)的一个配…

HBase基础知识(五):HBase 对接 Hadoop 的 MapReduce
通过 HBase 的相关 JavaAPI,我们可以实现伴随 HBase 操作的 MapReduce 过程,比如使用 MapReduce 将数据从本地文件系统导入到 HBase 的表中,比如我们从 HBase 中读取一些原 始数据后使用 MapReduce 做数据分析。 1 官方 HBase-MapReduce 1&am…

SparkSQL函数操作
1.5 SparkSQL函数操作
1.5.1 函数的定义
SQL中函数,其实说白了就是各大编程语言中的函数,或者方法,就是对某一特定功能的封装,通过它可以完成较为复杂的统计。这里的函数的学习,就基于Hive中的函数来学习。
1.5.2 函…
Hive优化笔记(1 - 非数据倾斜)
目录
列裁剪和分区裁剪
谓词下推
本地模式(local mode)
并行执行
严格模式
Map端聚合
调整mapper数
调整reducer数
小文件合并优化
设置jvm重用
引擎选择
输出结果压缩 最重要的:查看SQL的执行计划,优化业务逻辑 exp…
MapReduce编程规范
MapReduce编程规范 MapReduce的开发一共有八个步骤,其中Map阶段分为2个步骤,Shuffle阶段4个步骤,Reduce阶段分为2个步骤。 Map阶段2个步骤 设置InputFormat类,将数据切分为Key-Value(K1和V1)对,输入到第二步。 自定义Map逻辑,将第一步的结果转换成另外的…

大数据技术之Hadoop:提交MapReduce任务到YARN执行(八)
目录
一、前言
二、示例程序
2.1 提交wordcount示例程序
2.2 提交求圆周率示例程序
三、写在最后 一、前言
我们前面提到了MapReduce,也说了现在几乎没有人再写MapReduce代码了,因为它已经过时了。然而不写代码不意味着它没用,当下很火…

Chapter2 大数据处理架构Hadoop
2.1 Hadoop简介和版本演变
2.1.1 Hadoop简介
Hadoop是Apache软件基金会旗下开源软件,为用户提供高层接口,为用户提供了底层细节透明的分布式基础架构。 Hadoop是基于java语言开发的,具有很好的跨平台性,但是它支持多种语言&…
MapReduce基础编程
文章目录 第1关:合并去重第2关:整合排序第3关:信息挖掘 第1关:合并去重
编程要求 对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容…
spark为什么比mapreduce快?
spark为什么比mapreduce快?
首先澄清几个误区:
1:两者都是基于内存计算的,任何计算框架都肯定是基于内存的,所以网上说的spark是基于内存计算所以快,显然是错误的
2;DAG计算模型减少的是磁盘I/O次数&…
Hadoop的序列化机制
文章目录一.什么是序列化和反序列化二.Hadoop的序列化三.Hadoop的序列化案例一.什么是序列化和反序列化
序列化:将对象转化为字节流,以便在网络上传输或者写在磁盘磁盘上进行永久存储反序列化:将字节流转回成对象序列化在分布式数据处理的两个领域经常出现: 进程间通信和永久储…

大数据常见面试题之MapReduce
文章目录一.MapReduce的执行流程二.MapReduce写过吗?有哪些关键类?mapper的方法有哪些?setup方法是干嘛的?它是每读一行数据就调用一次这个方法吗?1.关键类2.mapper的方法有setup,map,cleanup&a…

MapReduce Shuffle 参数调优【转载】
MapReduce Shuffle性能调优
MapReduce shuffle过程剖析及调优
MapReduce的shuffle过程详解 Map阶段 -- 环形缓冲区大小,默认100
set mapreduce.task.io.sort.mb 200;-- 环形缓冲区溢写阈值,默认0.8
set mapreduce.map.sort.spill.percent 0.9;-- 并行…
hadoop学习:mapreduce入门案例二:统计学生成绩
这里相较于 wordcount,新的知识点在于学生实体类的编写以及使用 数据信息: 1. Student 实体类
import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class Stude…

2023.11.14-hive的类SQL表操作之,4个by区别
目录 1.表操作之4个by,分别是
2.Order by:全局排序
3.Cluster by
4.Distribute by :分区
5. Sort by :每个Reduce内部排序
6.操作练习
步骤一.创建表
步骤二.加载数据 步骤三.验证数据 1.表操作之4个by,分别是
order by 排序字段名
cluster by 分桶并排序字段名
dis…

MapReduce之Shuffle
承接上文MapReduce之Map阶段。
我们需要将map后的数据往外写。 shuffle收集数据排序和溢写合并收集数据
我们写出的数据是("I", 1)。 我们需要往kvbuffer中写key和value。
写key的时候我们既要写I,又要写它的位置,不然怎么能找到它呢&#…

MapReduce和Yarn部署+入门
看的黑马视频记的笔记 目录
1.入门知识点
2.部署
mapred-env.sh
mapred-site.xml
yarn-env.sh
yarn-site.xml
分发到另外两个节点
启动YARN
启动WEB UI页面 3.提交自带MapReduce示例程序到YARN运行
wordcount
求圆周率 1.入门知识点
明天 2.部署 在node1以hadoop用…
Go实现MapReduce
背景
当谈到处理大规模数据集时,MapReduce是一种备受欢迎的编程模型。它最初由Google开发,用于并行处理大规模数据以提取有价值的信息。MapReduce模型将大规模数据集分解成小块,然后对这些小块进行映射和归约操作,最终产生有用的…
Hadoop 3:YARN
YARN简介
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器。 YARN是一个【通用资源管理系统和调度平台】,可为上层应用提供统一的资源管理和调度。 它的引入为集群在利用率、…

大数据技术与原理实验报告(MapReduce 初级编程实践)
MapReduce 初级编程实践
验环境:
操作系统:Linux(建议Ubuntu16.04); Hadoop版本:3.2.2;
(一)编程实现文件合并和去重操作
对于两个输入文件,即文件 A 和…
如何使用hadoop对海量数据进行统计并排序
[b][colorgreen][sizex-large]不得不说,Hadoop确实是处理海量离线数据的利器,当然,凡是一个东西有优点必定也有缺点,hadoop的缺点也很多,比如对流式计算,实时计算,DAG具有依赖关系的计算&#x…

hadoop学习:mapreduce的wordcount时候,继承mapper没有对应的mapreduce的包
踩坑描述:在学习 hadoop 的时候使用hadoop 下的 mapreduce,却发现没有 mapreduce。
第一反应就是去看看 maven 的路径对不对
settings——》搜索框搜索 maven 检查一下 Maven 路径对不对
OK 这里是对的
那么是不是依赖下载失败导致 mapreduce 没下下…
Hadoop之mapreduce参数大全-5
101.指定任务启动过程中允许的最大跳过尝试次数
mapreduce.task.skip.start.attempts 是 Hadoop MapReduce 框架中的一个配置属性,用于指定任务启动过程中允许的最大跳过尝试次数。
在 MapReduce 作业中,如果某个任务(Map 任务或 Reduce 任…

MapReduce开发流程及示例
文章目录MapReduce开发流程(1)输入数据接口:InputFormat(2)逻辑处理接口:Mapper(3)Partitioner分区(4)Comparable排序(5)Combiner合并…
大数据 MapReduce如何让数据完成一次旅行?
专栏上一期我们聊到MapReduce编程模型将大数据计算过程切分为Map和Reduce两个阶段,先复习一下,在Map阶段为每个数据块分配一个Map计算任务,然后将所有map输出的Key进行合并,相同的Key及其对应的Value发送给同一个Reduce任务去处理…

【智能大数据分析】实验1 MapReduce实验:单词计数
【智能大数据分析】实验1 MapReduce实验:单词计数 文章目录 【智能大数据分析】实验1 MapReduce实验:单词计数一、实验目的二、实验要求三、实验原理1 MapReduce编程2 Java API解析 四、实验步骤1 启动Hadoop2 验证HDFS上没有wordcount的文件夹3 上传数据…

玩转大数据:2-揭秘Hadoop家族神秘面纱
1. 初识Hadoop家族
在当今的数字化时代,大数据已成为企业竞争的关键因素之一。为了有效地管理和分析这些庞大的数据,许多企业开始采用Hadoop生态系统。本文将详细介绍Hadoop生态系统的构成、优势以及应用场景。
首先,让我们来了解一下什么是…
MapReduce共享单车练习
MapReduce 本机运行 文章目录 MapReduce 本机运行✅前置工作1. 配置JDK2. 创建Java项目3. 导入所需JAR包 编程实现以下题目1. 统计各个月份共享单车使用的总数2. 统计不同天气情况下共享单车使用的总数3. 统计每个季度共享单车使用的总数4. 统计每个月份的注册数量5. 统计每天1…
MapReduce之Map阶段
MapReduce阶段分为map,shuffle,reduce。
map进行数据的映射,就是数据结构的转换,shuffle是一种内存缓冲,同时对map后的数据分区、排序。reduce则是最后的聚合。
此文探讨map阶段的主要工作。 map的工作代码介绍split…

大数据开发技术与实践期末复习(HITWH)
目录
分布式文件处理系统HDFS
分布式文件系统
HDFS简介
块(block)
主要组件的功能
**名称节点
FsImage文件
名称节点的启动
名称节点运行期间EditLog不断变大的问题
SecondaryNameNode的工作情况
数据节点
HDFS体系结构
HDFS体系结构的局限…

Google MapReduce中文版(转载)
摘要
MapReduce是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。用户首先创建一个Map函数处理一个基于 key/value pair的数据集合,输出中间的基于key/value pair的数据集合;然后再创建一个Reduce函数用来合并所有的具有相…
海量数据处理专题(转)【算法、数据结构】
大数据量的问题是很多面试笔试中经常出现的问题,比如baidu google 腾讯这样的一些涉及到海量数据的公司经常会问到。下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法…
一样的Java,不一样的HDInsight大数据开发体验
1首先开始科普 什么是 HDInsight
Azure HDInsight 是 Hortonworks Data Platform (HDP) 提供的 Hadoop 组件的云发行版,适用于对计算机集群上的大数据集进行分布式处理和分析。目前 HDInsight 可提供以下集群类型:Apache Hadoop、…
从数据仓库到大数据,数据平台这25年是怎样进化的?
数据产品&数据分析总监,2000年开始从事数据领域,从业传统制造业、银行、保险、第三方支付&互联网金融、在线旅行、移动互联网行业 。
我是从2000年开始接触数据仓库,大约08年开始进入互联网行业。很多从传统企业数据平台转到互联网同…
零基础徒手搭建大数据监控主机系统Grafana
注:本文搭建需掌握Linux基本命令。成功后的截图实例如图,随着时间的增长会更加帅气!
一. 需要的安装包
prometheus-2.9.2.linux-amd64.tar.gznode_exporter-0.17.0.linux-amd64.tar.gzgrafana-6.1.4.linux-amd64.tar.gz
注:安装…
海量数据处理:从并发编程到分布式系统
本系列文章主要围绕高并发这一话题展开,分享笔者在并发处理上的学习思路以及踩过的坑。具体思路大体分为三部分:
Java多线程编程;高并发的解决思路;分布式架构中Redis、Zookeeper分布式锁的应用。
本文将重点讲解第一部分——Jav…

MapReduce工作流程
2.3 MapReduce工作流程
整个MapReduce的重点
Map阶段
步骤1,已有数据,在/user/input下步骤2,该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value其实就是切片步骤3,提交信息&a…
Hadoop权威指南(第2版)--第1章
1.RAID和HDFS的区别
2.MapReduce编程模型:线性可伸缩,使用无共享框架,将问题分为独立的块,再进行并行计算。
3.Hadoop提供一个可靠的共享存储和分析系统,HDFS实现存储,而MapReduce实现分析处理。
4.磁盘…
Hadoop实现词频统计(按照词频降序排列以及相同词频的单词按照字母序排列)
Hadoop实现词频统计(按照词频降序排列以及相同词频的单词按照字母序排列) 分为两步词频统计和排序。第一个map reduce与过滤停用词的代码相同;第二个map reduce中的map将键值对内容交换,map到reduce的shufle中会自动进行key值升序…
linux内核调度算法(1)--快速找到最高优先级进程
为什么要了解内核的调度策略呢?呵呵,因为它值得我们学习,不算是废话吧。内核调度程序很先进很强大,管理你的LINUX上跑的大量的乱七八糟的进程,同时还保持着对用户操作的高灵敏响应,如果可能,为什…

[推荐系统]COLLABORATIVE FILTERING 学习总结
Collaborative filtering, 即协同过滤,是一种新颖的技术。最早于1989年就提出来了,直到21世纪才得到产业性的应用。应用上的代表在国外有Amazon.com,Last.fm,Digg等等。
最近由于毕业论文的原因,开始研究这…
搭建Hadoop分布式集群
搭建Hadoop分布式集群
【系统配置说明】
1)系统环境:CentOS-7-x86-Minimal 2)集群部署:一主三从(master/slave1/slave2/slave3) 3)Java环境:jdk-7u79-linux-x86 4)Hado…
nutch与hadoop
Nutch是最早用MapReduce的项目 (Hadoop其实原来是Nutch的一部分),Nutch的plugin机制吸取了eclipse的plugin设计思路。在Nutch中 MapReduce编程方式占据了其核心的结构大部分。从插入url列表(Inject),生成抓…
Hadoop2.x学习笔记-1(Hadoop架构+NTP集群时间同步配置)
一、前言 本人认为,学习一门技术首先需要系统的了解技术整个框架,才能让自己对这门技术的理解更进一步。同时,先有理论,后有技术的出现。这代表着,我们需要在学习好理论基础的前提上完成实践的操作,这样才能…
Hadoop基本介绍
1、Hadoop的整体框架 Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。 &…

使用MapReduce统计每一个用户的使用总流量
有上图这样的文件,需要统计每个用户使用的上行总流量,下行总流量和总流量
第一步:创建一个用户类如下:
package com.zut.flow;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;import org.ap…
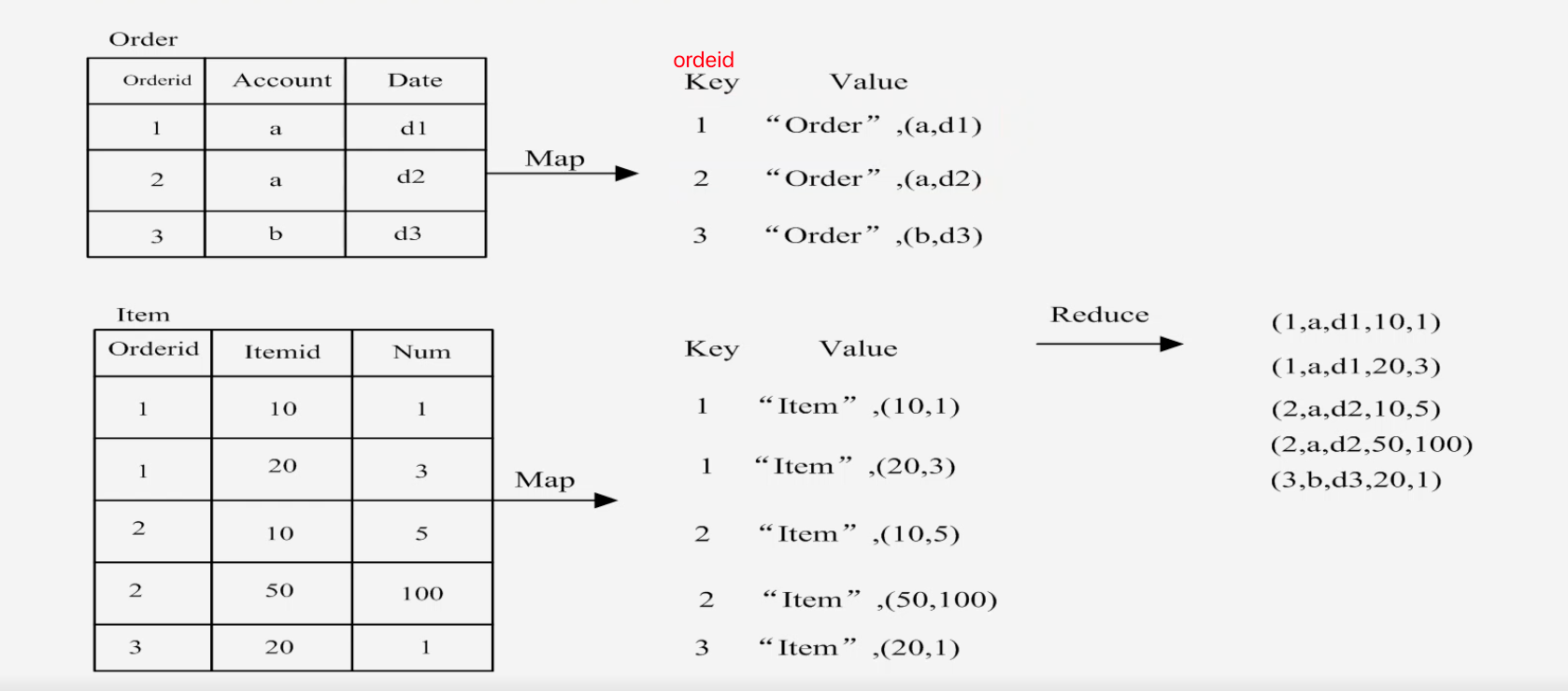
hadoop 学习:mapreduce 入门案例三:顾客信息与订单信息相关联(联表)
这里的知识点在于如何合并两张表,事实上这种业务场景我们很熟悉了,这就是我们在学习 MySQL 的时候接触到的内连接,左连接,而现在我们要学习 mapreduce 中的做法
这里我们可以选择在 map 阶段和reduce阶段去做 数据:
…
大数据平台/大数据技术与原理-实验报告--MapReduce编程
实验名称 MapReduce编程 实验性质 (必修、选修) 必修 实验类型(验证、设计、创新、综合) 综合 实验课时 2 实验日期 2023.10.30-2023.11.03 实验仪器设备以及实验软硬件要求 专业实验室(配有centos7.5系统…
[转载]大数据量,海量数据 处理方法总结
原文地址:大数据量,海量数据 处理方法总结(转载)作者:秋金遇水 最近有点忙,稍微空闲下来,发篇总结贴。 大数据量的问题是很多面试笔试中经常出现的问题,比如baidu google 腾讯这样的一些涉及到海量数据的公…

Java Worker 设计模式
Worker模式
想解决的问题
异步执行一些任务,有返回或无返回结果
使用动机
有些时候想执行一些异步任务,如异步网络通信、daemon任务,但又不想去管理这任务的生命周。这个时候可以使用Worker模式,它会帮您管理与执行任务&#…
Spark_Spark比mapreduce快的原因
Spark 为什么比 mapreduce 快?
最重要的3点,
数据缓存 : 中间结果可以缓存在内存中复用
资源管理 :executor task 管理,不同stage的task可以运行在同一个executor上
任务调度 : dag 对比多阶段mr 1.任务模型的优化(DAG图对比…
彷徨 | MapReduce实例六 | 求平均值Avg,以电影数据为例
给一组数据求平均值 , 将原始数据的 id 作为 key , 将要求的列作为 value , Map阶段将 key 和 value 提取出来交给 Reduce 处理 , Reduce将数据求和并求出平均值 , 这是一个相对比较简单的MapReduce案例 .
原始数据样本 :
{"movie":"1193","rate&…

彷徨 | MapReduce实例三 | 求共同好友
原始数据 :
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
代码实现 :
CommonFriendsOne
import java.io.File;
import java.io.IOException;import org.apache.com…

11.hadoop系列之MapReduce框架原理之InputFormat数据输入
我们先简要了解下InputFormat输入数据
1.数据块与数据切片
数据块: Block在HDFS物理上数据分块,默认128M。数据块是HDFS存储数据单位 数据切片: 数据切片只是在逻辑上对输入进行分片,并不会物理上切片存储。数据切片是MapReduce…

使用MapReduce实现join操作
文章目录一.概述二.需求三.mapreduce实现join四.MapReduce Map端 join实现原理(没有reduce处理)一.概述
熟悉SQL的读者都知道,使用SQL语法实现join是很简单的,只需要一条SQL语句即可,但是在大数据场景下使用MapReduce编程模型实现join还是比较繁琐的在实际生产中我们可以借助H…
海量数据处理常用思路和方法
海量数据处理常用思路和方法 最近有点忙,稍微空闲下来,发篇总结贴。 大数据量的问题是很多面试笔试中经常出现的问题,比如baidu google 腾讯 这样的一些涉及到海量数据的公司经常会问到。 下面的方法是我对海量数据的处理方法进行了一个…

Hadoop之MapReduce工作原理
Map阶段
①输入分片(inputsplit),这个时候也就是输入数据的时候,这时会进行会通过内部计算对数据进行逻辑上的分片。默认情况下这里的分片与HDFS中文件的分块是一致的。每一个逻辑上的分片也就对应着一个mapper任务。
②Mapper将…
MapReduce:超大机群上的简单数据处理
摘要MapReduce是一个编程模型,和处理,产生大数据集的相关实现.用户指定一个map函数处理一个key/value对,从而产生中间的key/value对集.然后再指定一个reduce函数合并所有的具有相同中间key的中间value.下面将列举许多可以用这个模型来表示的现实世界的工作.以这种方式写的程序能…
【hadoop运维】running beyond physical memory limits:正确配置yarn中的mapreduce内存
文章目录 一. 问题描述二. 问题分析与解决1. container内存监控1.1. 虚拟内存判断1.2. 物理内存判断 2. 正确配置mapReduce内存2.1. 配置map和reduce进程的物理内存:2.2. Map 和Reduce 进程的JVM 堆大小 3. 小结 一. 问题描述
在hadoop3.0.3集群上执行hive3.1.2的任…

Hadoop的第二个核心组件:MapReduce框架第一节
Hadoop的第二个核心组件:MapReduce框架第一节 一、基本概念二、MapReduce的分布式计算核心思想三、MapReduce程序在运行过程中三个核心进程四、如何编写MapReduce计算程序:(编程步骤)1、编写MapTask的计算逻辑2、编写ReduceTask的…
MapReduce(林子雨慕课课程)
文章目录 7. MapReduce7.1 MapReduce简介7.1.1 分布式并行编程7.1.2 MapReduce模型简介 7.2 MapReduce体系结构7.3 MapReduce工作流程概述7.4 Shuffle过程原理7.5 MapReduce应用程序的执行过程7.6 WordCount实例分析7.7 MapReduce的具体应用7.8 MaReduce编程实践 7. MapReduce …
Amazon Elastic MapReduce介绍
Amazon Elastic MapReduce 是一项托管服务,旨在通过使用短期运行且每秒成本较高的作业来处理和分析大量数据,或者用于长时间运行的工作负载,从而允许您在架构中构建高可用性。
EMR 基于流行且可靠的 Apache Hadoop 框架,这是一个…
MapReduce面试重点
文章目录 1. 简述MapReduce整个流程 1. 简述MapReduce整个流程 数据划分(Input Splitting):开始时,输入数据被分割成逻辑上的小块,每个块被称为Input Split。 映射(Map):每个Input Split 由一个或多个Map任务处理,这些…
大型数据集处理之道:深入了解Hadoop及MapReduce原理
在大数据时代,处理海量数据是一项巨大挑战。而Hadoop作为一个开源的分布式计算框架,以其强大的处理能力和可靠性而备受推崇。本文将介绍Hadoop及MapReduce原理,帮助您全面了解大型数据集处理的核心技术。
Hadoop简介 Hadoop是一个基于Google…

深入理解与应用Hadoop中的MapReduce
现在大数据是越来越火了,而我自己研究这方面也很长时间了,今天就根据我自己的经验教会大家学会如何使用MapReduce,下文中将MapReduce简写为MR。 本篇博客将结合实际案例来具体说明MR的每一个知识点。
1、本篇博客核心内容: 2、MR的基本概念 …
Hadoop3教程(八):MapReduce中的序列化概述
文章目录 (79)MR序列化概述(80)自定义序列化步骤(81)序列化案例需求分析(82)序列化案例代码参考文献 (79)MR序列化概述
什么是序列化,什么是反序…
【大数据存储】实验五:Mapreduce
实验Mapreduce实例——排序(补充程序) 实验环境
Linux Ubuntu 16.04
jdk-8u191-linux-x64
hadoop-3.0.0
hadoop-eclipse-plugin-2.7.3.jar
eclipse-java-juno-SR2-linux-gtk-x86_64 实验内容
在电商网站上,当我们进入某电商页面里浏览…

深入解析Hadoop生态核心组件:HDFS、MapReduce和YARN
这里写目录标题 01HDFS02Yarn03Hive04HBase1.特点2.存储 05Spark及Spark Streaming关于作者:推荐理由:作者直播推荐: 一篇讲明白 Hadoop 生态的三大部件 进入大数据阶段就意味着进入NoSQL阶段,更多的是面向…
搭建服务器集群的方法介绍
搭建服务器集群的方法介绍搭建本地服务器集群软硬件要求安装服务器网络配置搭建本地服务器集群
软硬件要求
一台电脑(系统不限,配置高一点更好)
VirtualBox
Centos7
VirtualBox 提供了各个系统的安装版本,下载完成后,直接点击软件包进行…
Hadoop3教程(十六):MapReduce中的OutputFormat
文章目录 (105)OutputFormat概述(106)自定义OutputFormat案例需求分析(107/108)自定义OutputFormat案例实现自定义Mapper自定义Reducer自定义OutputFormatDriver 参考文献 (105)Outp…
hadoop mapreduce的api调用WordCount本机和集群代码
本机运行代码
package com.example.hadoop.api.mr;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache…
【大数据面试】MapReduce常见问题与答案
目录
介绍下MapReduce
MapReduce优缺点
MapReduce架构
MapReduce工作原理
MapReduce哪个阶段最费时间
✅MapReduce中的Combine是干嘛的?有什么好出?
✅MapReduce环形缓冲区是什么
✅MapReduce为什么一定要有环型缓冲区
MapReduce为什么一定要有Shuffle过程
MapRedu…
Hadoop 复习 ---- chapter03【Hadoop安装】
Hadoop 复习 ---- chapter03【Hadoop安装】见:[虚拟机安装配置Hadoop(图文教程)](https://blog.csdn.net/qq_52354698/article/details/126638344)1. 安装教程2. 常见问题见:虚拟机安装配置Hadoop(图文教程)…

数据科学导论复习个人整理
综合了各方的材料整理综合了这一份 但是考试被EDA打脸(doge) 把图片删了,老师课件外传不好 所以涉及老师课件的图都删了,只写知识点名称 大数据概述
1.大数据时代技术支撑:存储设备容量不断增加、CPU处理能力大幅提升…
Hadoop MapReduce简介
本节首先简单介绍大数据批处理概念,然后介绍典型的批处理模式 MapReduce,最后对 Map 函数和 Reduce 函数进行描述。
批处理模式
批处理模式是一种最早进行大规模数据处理的模式。批处理主要操作大规模静态数据集,并在整体数据处理完毕后返回…
Hadoop2.6.0-cdh5.4.1源码编译安装
[b][colorgreen][sizelarge]版本使用范围,大致 与Apache Hadoop编译步骤一致大同小异,因为CDH的Hadoop的本来就是从社区版迁过来的,所以,这篇文章同样适合所有的以Apache Hadoop为原型的其他商业版本的hadoop编译,例如…
Hadoop 2.7分布式部署
转载请注明出处: http://blog.csdn.net/u012842205/article/details/52503514 Hadoop是一个开源的计算框架,致力于在廉价计算机集群上大规模数据集的分布式存储和计算。简介可通过此文章了解:Hadoop概述
当然,最好的学习方式&am…

MapReduce概述
MapReduce概述
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
MapReduce…
大数据之Hive(二)
文章目录前言一、Hive数据库和表操作(一)数据库操作1. 创建数据库2. 删除数据库(二)数据表操作1. 内部表和外部表的操作1.1 内部表操作1.2 外部表操作2. 复杂类型操作2.1 Array类型2.2 map类型2.3 struct类型前言
#博学谷IT学习技…

MapReduce:关于RecordReader调用getCurrentKey()和getCurrentValue()时返回相同键-值对象
在《Hadoop权威指南 第4版》的P219,关于Mapper类的run()方法部分有这样一段描述: 由于效率的原因,RecordReader程序每次调用getCurrentKey()和getCurrentValue()时将返回相同的键-值对象。只是这些对象的内容被reader的netKeyValue()方法改变…

Hadoop:MapReduce之Mapper类的输入
目录
Mapper类
Mapper的输入
InputFormat
文件输入FileInputFormat & 输入分片InputSplit
文本输入TextInputFormat & 行记录阅读器LineRecordReader
Mapper的输出
收集器Collector
分区器Partitioner
案例:分别计算奇数行和偶数行之和 Hadoop的代…
MapReduce Partition 分区
MapReduce Partition 分区
MapReduce输出结果个数研究 在默认情况下 不管Map阶段有多少个并发执行的task,到Reduce阶段,所有结果都将有一个task来进行处理,并且最终结果将输出到一个文件中,part-r-0000。 可以进行手动的设置re…
Hadoop2.8.5 MapReduce计算框架
Hadoop 中 YARN 子系统的使命是为用户提供大数据的计算框架。早期的Hadoop ,甚至早期的 YARN 都只提供一种计算框架,那就是 MapReduce。 Hadoop 后来有了一些新的发展,除 MapReduce 外又提供了称为 Chain 和 Stream 的计算框架,一来使用户不必非得用 Java 编程;二来更允许用户利…
高可用Hadoop大数据部署流程
补充:mp引擎切换为tez、解决yarn 8081端口报错问题
解决hive comment中文乱码问题:hive-site配置如下
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.4.151.58:3306/hive?allowMultiQueriestrue&…
大数据框架和数仓高频面试题总结
目录
Hadoop
Hive
Hbase
Spark
协作组件
数仓 Hadoop
1、简答说一下hadoop的map-reduce编程模型 MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce。 Map是映射,负责数据的过滤分法,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处…
MIT6.5840-2023-Lab1: MapReduce
前置知识
MapReduce:Master 将一个 Map 任务或 Reduce 任务分配给一个空闲的 worker。 Map阶段:被分配了 map 任务的 worker 程序读取相关的输入数据片段,生成并输出中间 k/v 对,并缓存在内存中。 Reduce阶段:所有 ma…

手写MapReduce实现WordCount
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 需求分析编写MapReduce实现上述功能Mapper类Reducer类Driver类 查看输出结果 需求 假设有一个文本文件word.txt,我们想要统计这个文本文件中每个单词出现的次数。 文件内容如下…
![Hadoop(2):常见的MapReduce[在Ubuntu中运行!]](https://img-blog.csdnimg.cn/direct/e92fa12d952d40348d401129031dfced.png)
Hadoop(2):常见的MapReduce[在Ubuntu中运行!]
1 以词频统计为例子介绍 mapreduce怎么写出来的
弄清楚MapReduce的各个过程: 将文件输入后,返回的<k1,v1>代表的含义是:k1表示偏移量,即v1的第一个字母在文件中的索引(从0开始数的);v1表…

个人笔记:分布式大数据技术原理(二)构建在 Hadoop 框架之上的 Hive 与 Impala
有了 MapReduce,Tez 和 Spark 之后,程序员发现,MapReduce 的程序写起来真麻烦。他们希望简化这个过程。这就好比你有了汇编语言,虽然你几乎什么都能干了,但是你还是觉得繁琐。你希望有个更高层更抽象的语言层来描述算法…
3.MapReduce实践-单词统计
目录 概述MapReduce 核心进程MapReduce 编程规范单词统计案例源码 结束 概述
官网文档速递
MapReduce :分布式计算框架 通常情况下,一个 MR 作业是有 2 个部分构成:MapTask ReduceTask(可以没有) MapReduce 核心进程
主要有三个࿱…

怎样通过MapReduce完成排序工作,使其有序(字典序)呢?
第一步 对原始的数据进行分割(Split), 得到N个不同的数据分块 第二步 对每一个数据分块都启动一个Map进行处理。 采用桶排序的方法,每个Map中按照首字母将字符串分配到26个不同的桶中 第三步 对于Map之后得到的中间结果ÿ…
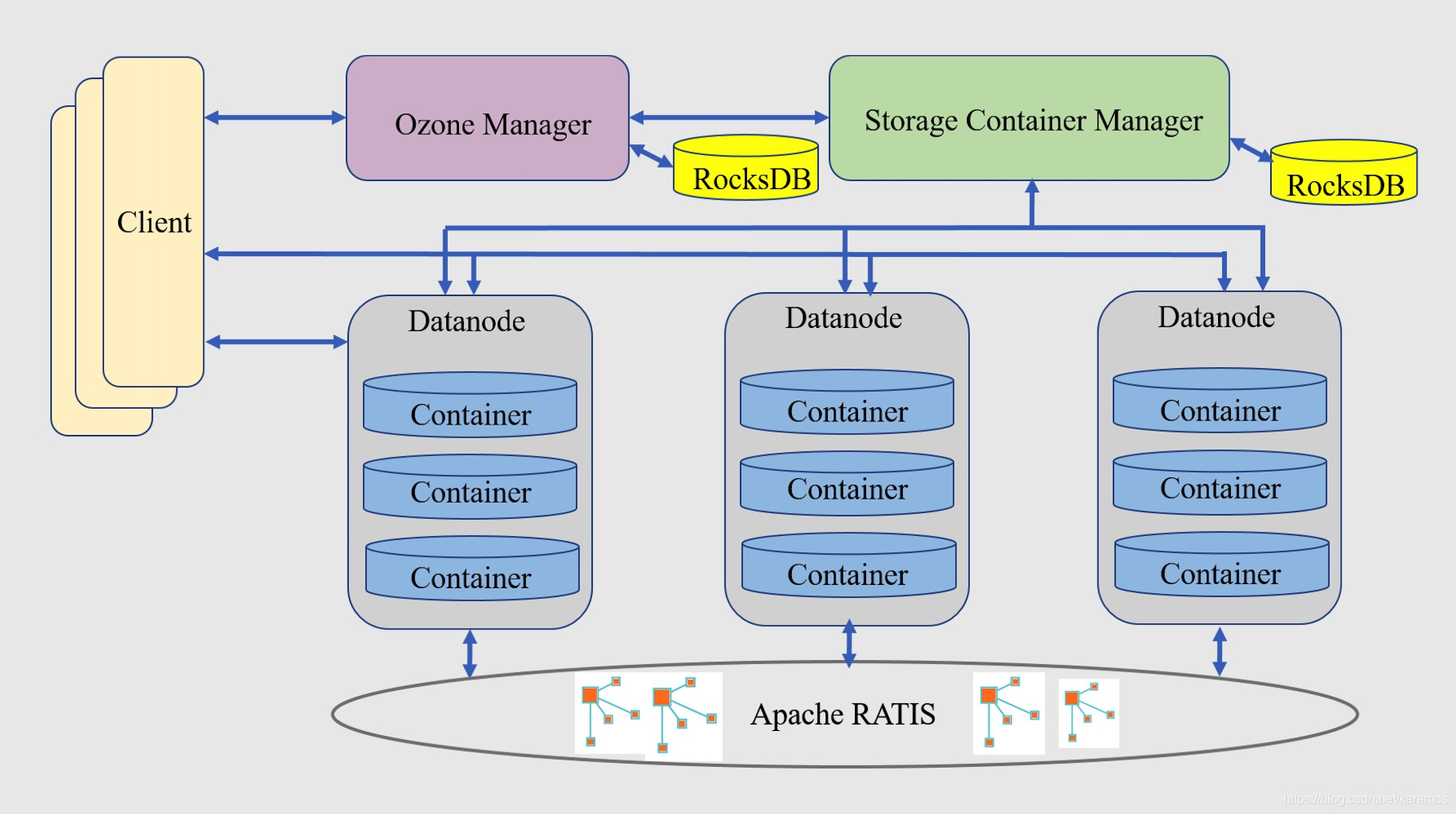
腾讯云大数据团队主导Apache社区新一代分布式存储系统Ozone 1.0.0发布
刚刚获悉,由腾讯云大数据团队主导的Ozone 1.0.0版本在Apache Hadoop社区正式发布。据了解,经过2年多的社区持续开发和内部1000节点的实际落地验证,Ozone 1.0.0已经具备了在大规模生产环境下实际部署的能力。
Ozone 是Apache Hadoop社区推出的…
Parquet存储的数据模型以及文件格式
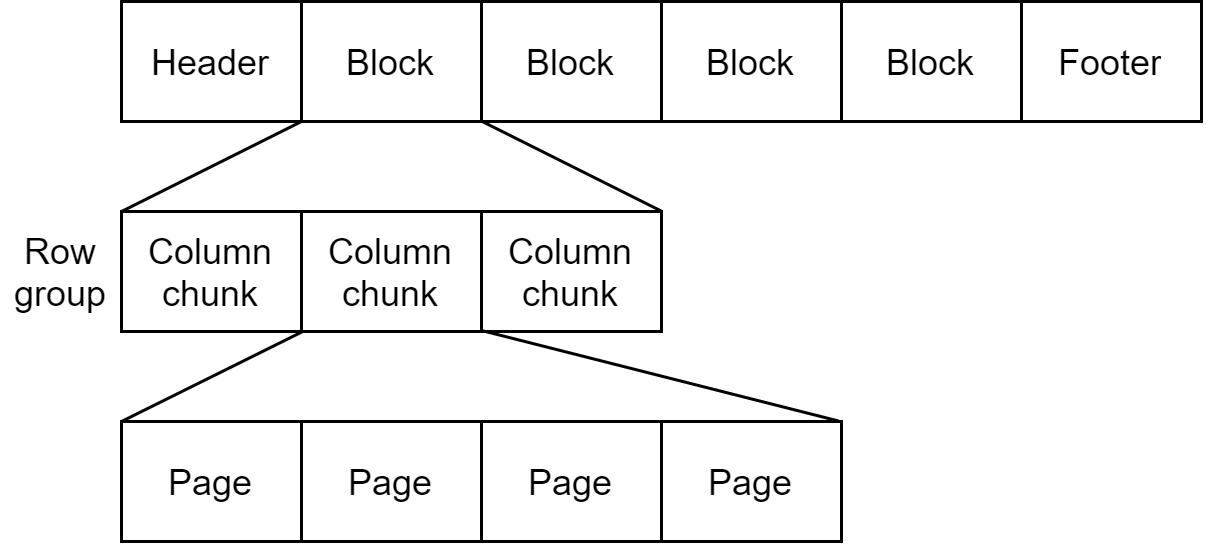
文章目录 数据模型Parquet 的原子类型Parquet 的逻辑类型嵌套编码 Parquet文件格式 本文主要参考文献:Tom White. Hadoop权威指南. 第4版. 清华大学出版社, 2017.pages 363. Aapche Parquet是一种能有效存储嵌套数据的列式存储格式,在Spark中应用较多。 …
干翻Hadoop系列:MapReduce详解
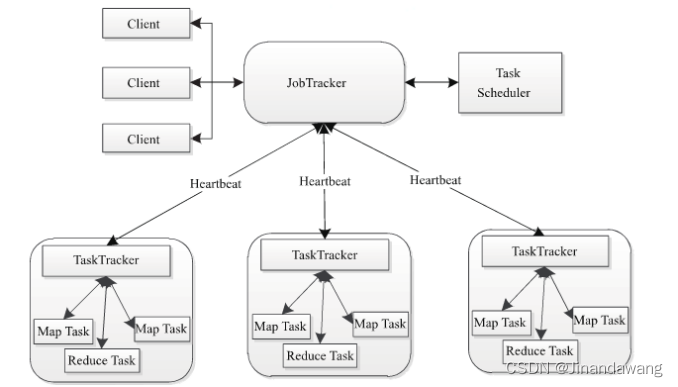
第一章:MapReduce原理
数据存储在分布式文件系统中HDFS里边,通过使用Hadoop资源管理系统YARN,Hadoop可以将MapReduce计算,转移到有存储部分的数据的各台机器上。
一:概念和原理
1:MapReduce作业
MapRed…
最全分布式文件系统 HDFSYARNMapReduce详讲
HDFS简介
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDF…
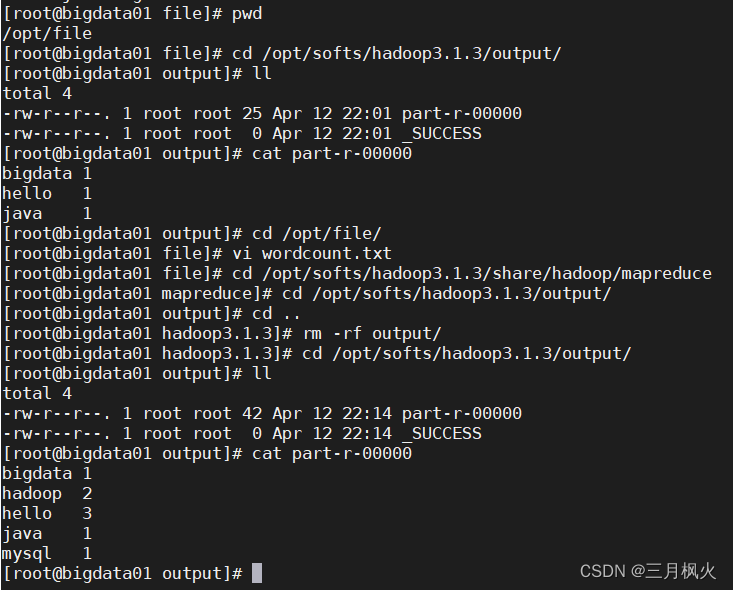
hadoop单机版安装
文章目录1. 将安装包hadoop-3.1.3.tar.gz上次至linux中2. 进行解压操作3. 修改目录名称4. 配置环境变量5. 使用官方提供的jar包实现wordcount案例1. 将安装包hadoop-3.1.3.tar.gz上次至linux中 2. 进行解压操作
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/softs/##tar: 解压打包的…

Hadoop集群搭建教程(二)
Hadoop集群搭建教程(一)
master管理集群
在上一篇hadoop集群搭建教程中,启动集群的方式是:需要在每一台节点机器上分别键入启动命令。但是,这样的方法显然很麻烦,而且不人性化,那么我们可以通…
Google架构学习
原文:[urlhttp://www.highscalability.com/google-architecture]Google Architecture[/url]Google是伸缩性的王者。Google一直的目标就是构建高性能高伸缩性的基础组织来支持它们的产品。[b]平台[/b]
Linux
大量语言:Python,Java,…
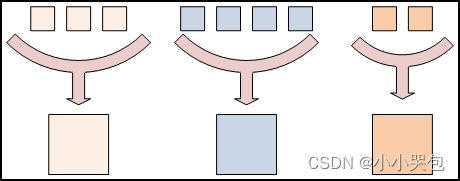
MapReduce基础
函数式编程概念MapReduce程序是设计用来并行计算大规模海量数据的,这需要把工作流分划到大量的机器上去,如果组件(component)之间可以任意的共享数据,那这个模型就没法扩展到大规模集群上去了(数百或数千个节点)&#…
Spark 和 MapReduce 的对比
在此之前,我们先来了解一下 MapReduce 。MapReduce 本质就是两个过程:Map切分 和 reduce聚合。
一、内存计算 spark 将数据存储在内存中进行计算;MapReduce 将数据存储在磁盘上。 由于内存访问速度更快,spark 在处理迭代计算和交…

十六、YARN和MapReduce配置
1、部署前提
(1)配置前提
已经配置好Hadoop集群。
配置内容: (2)部署说明 (3)集群规划 2、修改配置文件
MapReduce
(1)修改mapred-env.sh配置文件
export JAVA_HOM…
MapReduce之Reduce
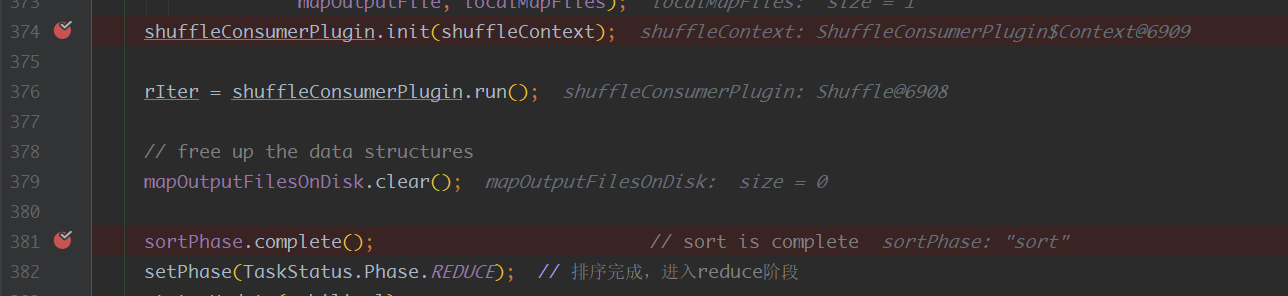
我们接着MapReduce之Shuffle ReduceCopyMergeReduceCopy 走到这里,我们就进入到reduce了。 reduce有三个明确的阶段:copy,sort,reduce。
在初始化ShuffleConsumerPlugin的时候,他需要创建一个MergeManager:…
Sqoop1.99.7安装、配置和使用(二)
转载请注明出处:http://blog.csdn.net/u012842205/article/details/52346595 本文将接上文,记录Sqoop1.99.7基本使用。这里我们使用sqoop2将MySQL中的一个数据表导出到HDFS,都是最简单的使用。 请确保Sqoop2服务器已经启动,并确保…
如何使用Hadoop读写数据库
[b][colorgreen][sizelarge]在我们的一些应用程序中,常常避免不了要与数据库进行交互,而在我们的hadoop中,有时候也需要和数据库进行交互,比如说,数据分析的结果存入数据库,或者是,读取数据库的…
【大数据】Hadoop MapReduce与Hadoop YARN(学习笔记)
一、Hadoop MapReduce介绍
1、设计构思
1)如何对付大数据处理场景
对相互间不具有计算依赖关系的大数据计算任务,实现并行最自然的办法就是采取MapReduce分而治之的策略。
不可拆分的计算任务或相互间有依赖关系的数据无法进行并行计算! …
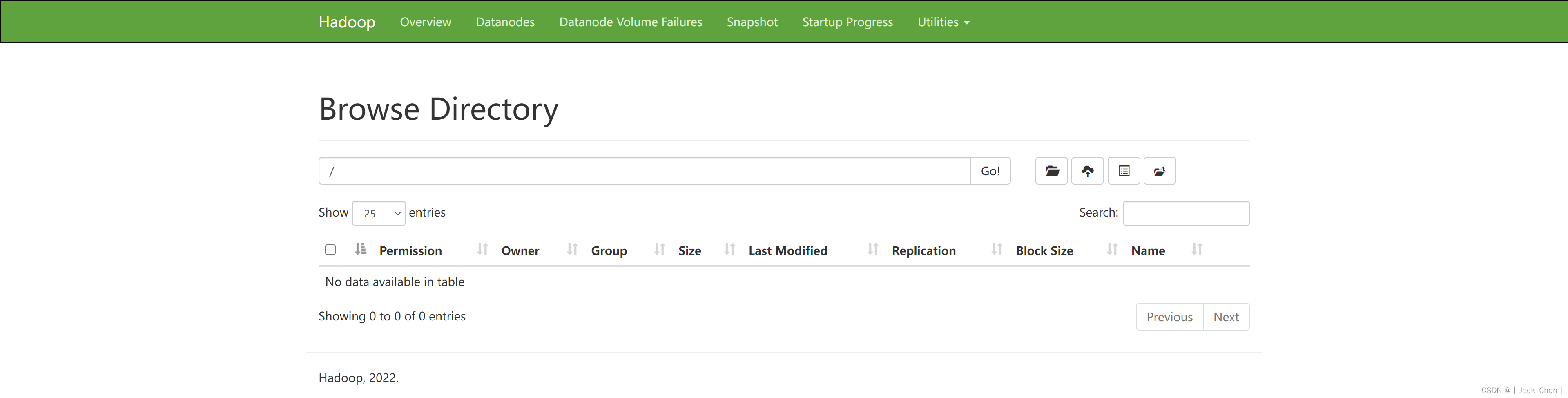
Linux服务器搭建Hadoop单节点伪分布式
Linux服务器搭建Hadoop单节点伪分布式
官网:https://hadoop.apache.org/
安装Hadoop
下载地址:https://archive.apache.org/dist/hadoop/core/
wget http://archive.apache.org/dist/hadoop/core/hadoop-3.3.2/hadoop-3.3.2.tar.gz解压且重命名
tar…
Hadoop运行模式
hgfhfg
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:Apache Hadoop 一、本地运行模式 官方Grep案例
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹 mkdir input
2. 将Hadoop的xml配置文件复制到input cp et…
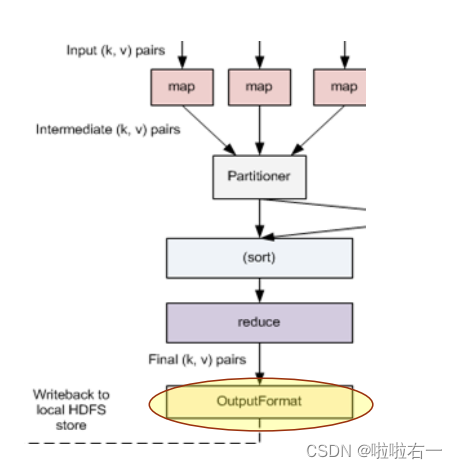
大数据|MapReduce模型 | Hadoop MapReduce的基本工作原理
前文回顾:HDFS分布式文件系统 目录
📚对付大数据处理:分而治之
🐇大数据的并行化计算
🐇大数据任务划分和并行计算模型
📚构建抽象模型:Map和Reduce
🐇关键思想
🥕…
OpenRS—— 开放式遥感数据处理与服务平台 OpenRS-Cloude:基于MapReduce的并行遥感处理系统
江万寿研究员介绍了开放式遥感数据处理与服务平台项目的来源、进展情况,项目思路以及要达到的目标:可扩展、可伸缩、可配置、可定制。 OpenRS的最终目标是搭建一个基本的遥感图像数据处理与应用的框架,实现最常用的图像读写、显示、漫游&…
Hadoop MapReduce各阶段执行过程以及Python代码实现简单的WordCount程序
视频资料:黑马程序员大数据Hadoop入门视频教程,适合零基础自学的大数据Hadoop教程 文章目录Map阶段执行过程Reduce阶段执行过程Python代码实现MapReduce的WordCount实例mapper.pyreducer.py在Hadoop HDFS文件系统中运行Map阶段执行过程
把输入目录下文件…
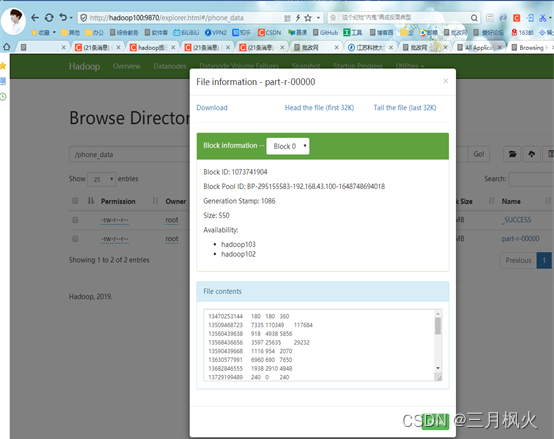
探讨Hive是否转为MapReduce程序
目录 前提条件
数据准备
探讨HQL是否转为MapReduce程序执行
1.设置hive.fetch.task.conversionnone
2.设置hive.fetch.task.conversionminimal
3.设置hive.fetch.task.conversionmore 前提条件
Linux环境下安装好Hive,这里测试使用版本为:Hive2.3.…
深入理解MapReduce
相关概念 MapReduce是一个基于HDFS的分布式计算框架,是一个可以将分布式计算抽象为Map和Reduce的编程模型,它的核心思想是分治,将大量数据分到不同机器上去分别计算最终汇总从而进行高效的数据处理,但是MapReduce不支持迭代和循环…

彷徨 | MapReduce实例七 | Join拼接
以用户订单数据为例 : JoinBean
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;import org.apache.hadoop.io.Writable;public class JoinBean implements Writable{private String oid;private String uid;private String name;private…

彷徨 | MapReduce实例二 | 去重复
原始数据
prefix phone province city isp post_code city_code area_code
130 1300000 山东 济南 联通 250000 0531 370100
130 1300001 江苏 常州 联通 213000 0519 320400
130 1300002 安徽 巢湖 联通 238000 0551 340181
130 1300003 四川 宜宾 联通 644000 0831 511500
1…
Hadoop2.7.1配置NameNode+ResourceManager高可用原理分析
[sizemedium]
关于NameNode高可靠需要配置的文件有core-site.xml和hdfs-site.xml
关于ResourceManager高可靠需要配置的文件有yarn-site.xml逻辑结构:[img]http://dl2.iteye.com/upload/attachment/0113/0183/068b6538-174b-394a-818f-da4ca3e87e9e.png[/img]NameNo…
Hadoop2.2如何集成Apache Pig0.12.1?
[b][colorgreen][sizelarge]散仙假设你的Hadoop环境已经安装完毕(1)到[url]https://archive.apache.org/dist/pig/[/url]下载对应的tar包,如果是hadoop0.20.x之前的版本,则直接可以用,如果Hadoop2.x之后的,…
如何在Hadoop里面实现二次排序
[b][colorgreen][sizelarge]在hadoop里面处理的数据,默认按输入内容的key进行排序的,大部分情况下,都可以满足的我们的业务需求,但有时候,可能出现类似以下的需求,输入内容:
[/size][/color][/b…

2.MapReduce序列化—实现序列化接口、序列化案例实战
本文目录如下:第二章 MapReduce序列化案例2.1 自定义FloBean对象实现序列化接口(Writable)2.2 序列化案例实操2.3.1 需求2.3.2 需求分析2.3.3 编写MapReduce程序第二章 MapReduce序列化案例
2.1 自定义FloBean对象实现序列化接口(…
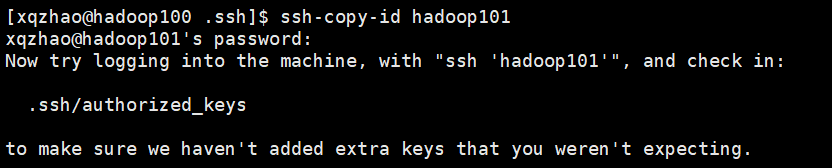
3.Hadoop运行模式-完全分布式(重点)—xsync集群分发脚本、集群配置、SSH无密登录、启动集群
本文目录如下:4 完全分布式运行模式(开发重点)4.1 虚拟机准备4.2 scp(secure copy)安全拷贝4.3 rsync 远程同步工具4.4 **xsync集群分发脚本**4.4.1 需求分析:4.4.2 脚本实现4.4.3 xsync相关错误4.5 集群配置4.5.1 集群部署规划4.…
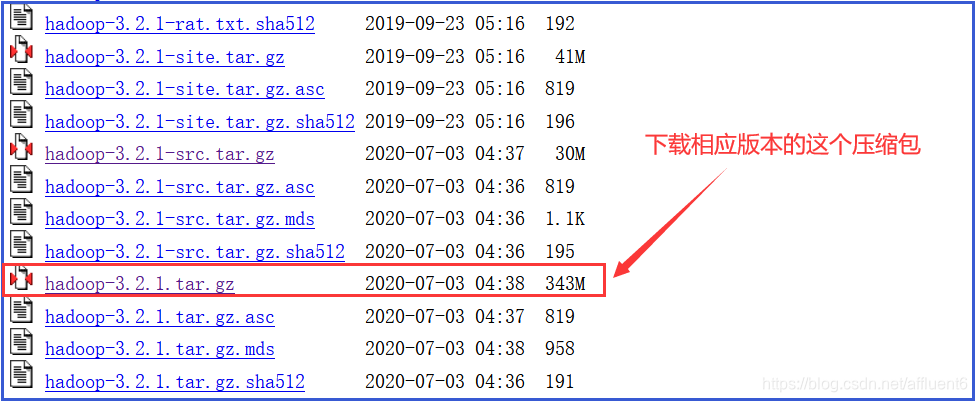
1.Hadoop运行环境搭建-Linux虚拟机准备、JDK安装、Hadoop安装、Windows安装Hadoop
本文目录如下:1.Hadoop运行环境搭建1.1 虚拟机环境准备1.2 安装JDK1.2.1 卸载现有JDK1.2.2 在Linux系统下的opt目录中查看软件包是否导入成功1.2.3 解压JDK到/opt/module目录下1.2.4 配置JDK环境变量1.2.5 测试JDK是否安装成功1.3 安装Hadoop1.3.1 进入到Hadoop安装…
如何查看Hadoop运行过程中产生日志
[b][colorgreen][sizelarge]用hadoop也算有一段时间了,一直没有注意过hadoop运行过程中,产生的数据日志,比如说System打印的日志,或者是log4j,slf4j等记录的日志,存放在哪里,日志信息的重要性&a…

Spark、Hive、Hbase比较
1.spark
spark是一个数据分析、计算引擎,本身不负责存储;可以对接多种数据源,包括:结构化、半结构化、非结构化的数据;其分析处理数据的方式有多种发,包括:sql、Java、Scala、python、R等&…
Java操作Apache HBase API以及HBase和MapReduce整合
Java操作HBase API
添加依赖 <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.apache.hadoop</g…

mapreduce运行环境涉及的相关配置
近日安装HIVE时执行HIVE的操作发现一问题,现记录下来。
在hive中,创建数据库,创建数据表,插入数据时,发现并调用mapreduce和yarn,插入操作未成功。如下图: map和reduces未启动。
解决…
XShell7 + Xftp7 + IDEA 打包MapReduce程序到集群运行
参考博客
【MapReduce打包成jar上传到集群运行】http://t.csdn.cn/2gK1d
【Xshell7/Xftp7 解决强制更新问题】http://t.csdn.cn/rxiBG
IDEA打包MapReduce程序
这里的打包是打包整个项目,后期等学会怎么打包单个指定的mapreduce程序再来更新博客。
1、编译打包 …

MapReduce YARN 的部署
1、部署说明
Hadoop HDFS分布式文件系统,我们会启动:
NameNode进程作为管理节点DataNode进程作为工作节点SecondaryNamenode作为辅助 同理,Hadoop YARN分布式资源调度,会启动:ResourceManager进程作为管理节点NodeM…
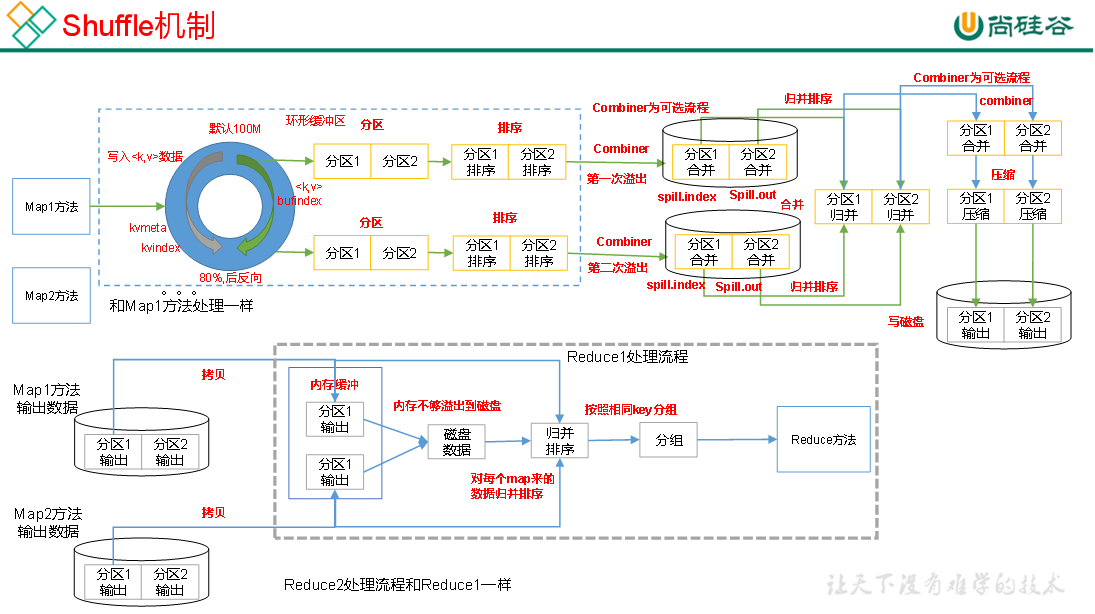
Hadoop3教程(十二):MapReduce中Shuffle机制的概述
文章目录 (95) Shuffle机制什么是shuffle?Map阶段Reduce阶段 参考文献 (95) Shuffle机制
面试的重点
什么是shuffle?
Map方法之后,Reduce方法之前的这段数据处理过程,就叫做shuff…
Hadoop3教程(十三):MapReduce中的分区
文章目录 (96) 默认HashPartitioner分区(97) 自定义分区案例(98)分区数与Reduce个数的总结参考文献 (96) 默认HashPartitioner分区
分区,是Shuffle里核心的一环…
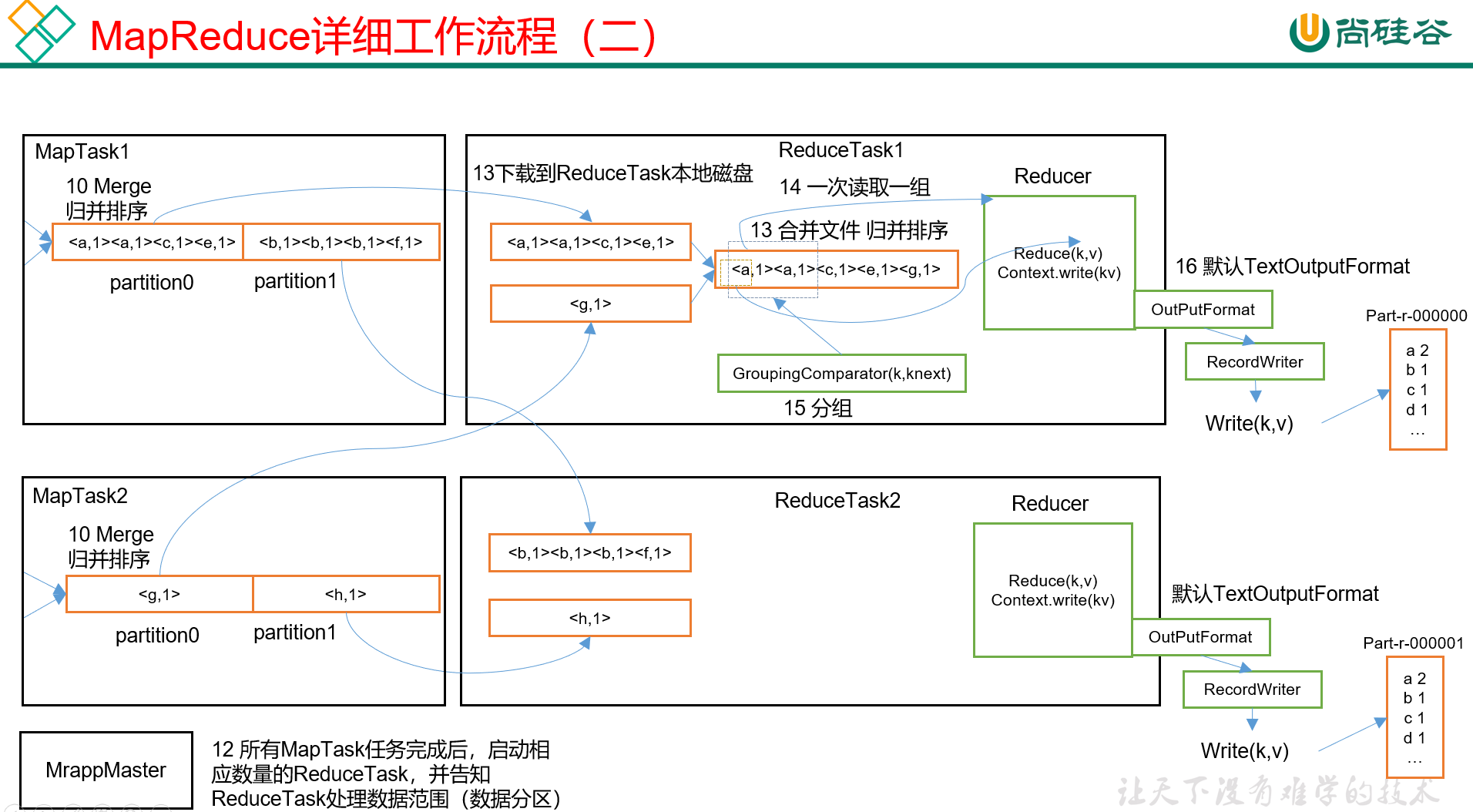
Hadoop3教程(十一):MapReduce的详细工作流程
文章目录 (94)MR工作流程Map阶段Reduce阶段 参考文献 (94)MR工作流程
本小节将展示一下整个MapReduce的全工作流程。
Map阶段
首先是Map阶段: 首先,我们有一个待处理文本文件的集合; 客户端…
手机爬虫用Appium详细教程:利用Python控制移动App进行自动化抓取数据
Appium是一个强大的跨平台工具,它可以让你使用Python来控制移动App进行自动化操作,从而实现数据的抓取和处理。今天,我将与大家分享一份关于使用Appium进行手机爬虫的详细教程,让我们一起来探索Appium的功能和操作,为手…
Hadoop3教程(十八):MapReduce之MapJoin案例分析
文章目录 (118)MapJoin案例需求分析ReduceJoin的问题如何解决ReduceJoin的问题如何将一个文件主动缓存到集群的内存里 (119)MapJoin案例代码实现参考文献 (118)MapJoin案例需求分析
ReduceJoin的问题
在R…
Hadoop3教程(十九):MapReduce之ETL清洗案例
文章目录 (121)ETL数据清洗案例参考文献 (121)ETL数据清洗案例
ETL,即Extract-Transform-Load的缩写,用来描述数据从源端,经过抽取(Extract)、转换(transfor…
Hadoop3教程(二十一):MapReduce中的压缩
文章目录 (123)压缩概述在Map阶段启用在Reduce阶段启用 (124)压缩案例实操如何在Map输出端启用压缩如何在Reduce端启用压缩 参考文献 (123)压缩概述
压缩也是MR中比较重要的一环,其可以应用于M…
大数据学习(17)-mapreduce task详解
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…
大数据中的分布式文件系统MapReduce的选择题
一 . 选择题
一. 单选题(共9题,49.5分)
(单选题)下列传统并行计算框架,说法错误的是哪一项? A. 刀片服务器、高速网、SAN,价格贵,扩展性差上 B. 共享式(共享内存/共享存储),容错性好 C. 编程难度高 D. 实时、细粒度计算、计算密集型 正确答…
头哥实践平台之MapReduce基础实战
一. 第1关:成绩统计
编程要求
使用MapReduce计算班级每个学生的最好成绩,输入文件路径为/user/test/input,请将计算后的结果输出到/user/test/output/目录下。
先写命令行,如下: 一行就是一个命令
touch file01
echo Hello World Bye Wor…

【Hadoop】MapReduce详解
🦄 个人主页——🎐开着拖拉机回家_大数据运维-CSDN博客 🎐✨🍁 🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁…
38 _ 分治算法:谈一谈大规模计算框架MapReduce中的分治思想
MapReduce是Google大数据处理的三驾马车之一,另外两个是GFS和Bigtable。它在倒排索引、PageRank计算、网页分析等搜索引擎相关的技术中都有大量的应用。
尽管开发一个MapReduce看起来很高深,感觉跟我们遥不可及。实际上,万变不离其宗,它的本质就是我们今天要学的这种算法思…

【学习笔记】尚硅谷Hadoop大数据教程笔记
本文是尚硅谷Hadoop教程的学习笔记,由于个人的需要,只致力于搞清楚Hadoop是什么,它可以解决什么问题,以及它的原理是什么。至于具体怎么安装、使用和编写代码不在我考虑的范围内。
一、Hadoop入门
大数据的特点:
Vo…
Hive优化笔记(2 - 数据倾斜)
一 基本概念
简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少。默认情况下, Map 阶段同一 Key 数据分发给一个 reduce,当一个 key 数据过大时,就发生倾斜了
数据倾斜一般有两种情况…
Apache Hive 的 SQL 执行架构
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据技术体系 正文
本文介绍 Apache Hive 如何将 SQL 转化为 Map…
[转]Adobe发布Puppet Recipes for Hadoop
转自:http://www.infoq.com/cn/news/2010/07/adobe-released-puppet-recipes
近日,Adobe向社区发布了Puppet recipes , 该工具用于自动化Hadoop/HBase的部署工作。InfoQ有幸采访到了PuppetLabs的创建者Luke Kanies以了解更多信息。
Puppet是…

Hadoop伪分布安装详解+MapReduce运行原理+基于MapReduce的KNN算法实现
本篇博客将围绕Hadoop伪分布安装MapReduce运行原理基于MapReduce的KNN算法实现这三个方面进行叙述。
(一)Hadoop伪分布安装 备注:centos安装可以参考: https://blog.51cto.com/13570216/2060583 https://www.cnblogs.com/saryli/…


MapReduce笔记
总计:切片就是对一个文件按逻辑进行切片,默认每128m为一个切片,不是物理切片,每个切片对应着一个mapTask进行处理。而且切片是针对每一个文件进行切片的,即一个文件一个文件切片,不是把所以待处理的文件总量…
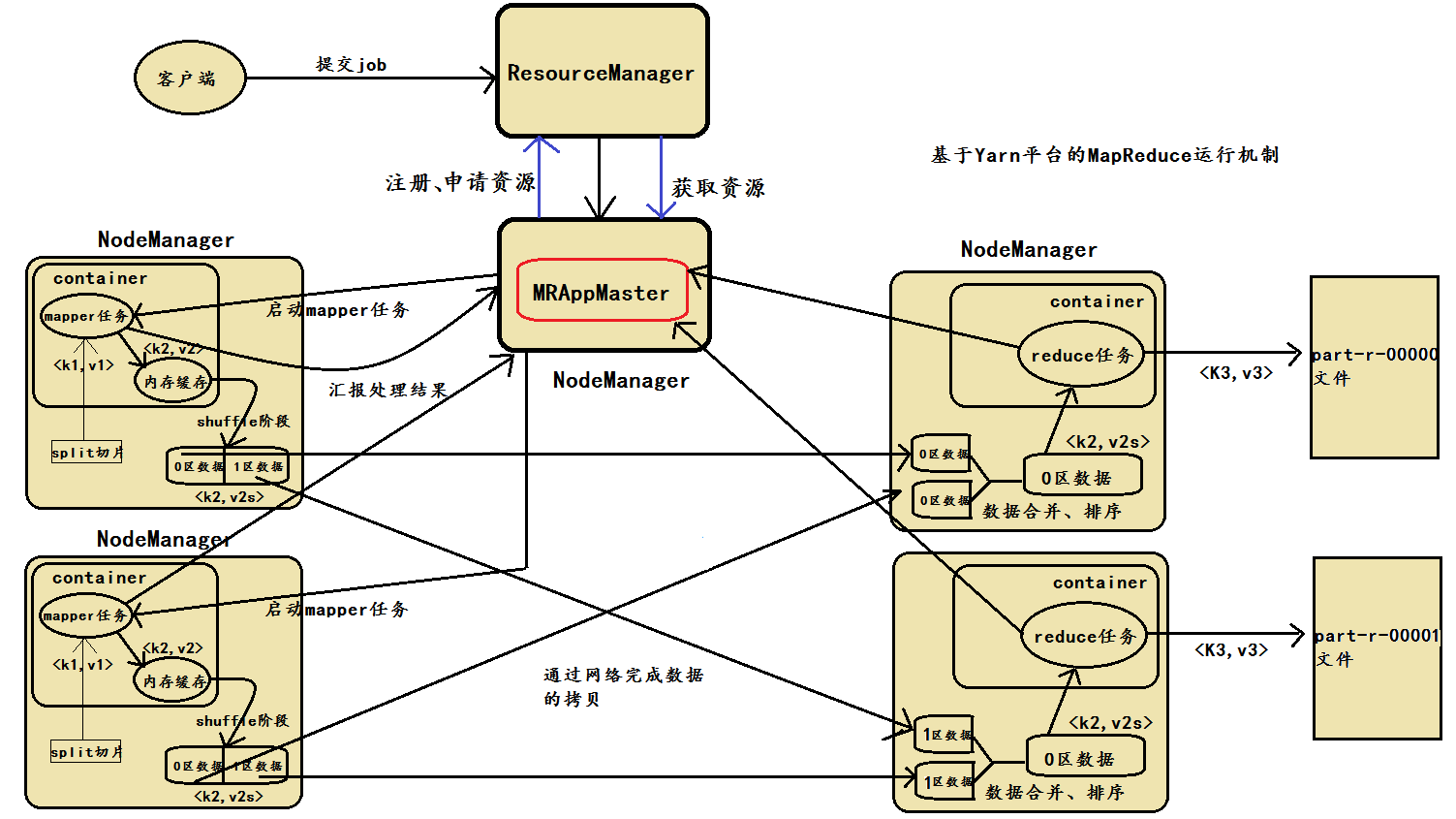
基于Yarn平台的MapReduce运行机制
基于Yarn平台的MapReduce运行机制如下图所示: 详细步骤: 1>用户向yarn平台提交应用程序 2>yarn平台的ResourceManager接收到我们客户端提交给的MapReduce程序后,把程序交给某个NodeManager节点,随后在这个NodeManager节…
基于MapReduce的手机上网流量统计分析
Hadoop简介:适合大数据的分布式存储与计算平台。 运行在Hadoop之上的大型服务器集群: 数据情况:(摘取部分) 字段描述:时间戳、手机号码、AP mac、AP mac、访问的网址、网址种类、上行数据包、下行数…
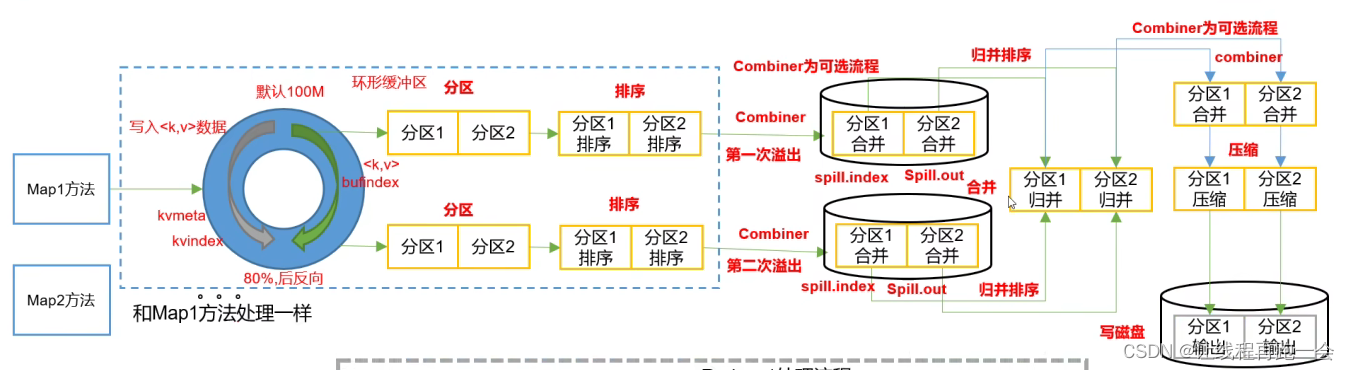
MapReduce【Shuffle-Combiner】
概述 Conbiner在MapReduce的Shuffle阶段起作用,它负责局部数据的聚合,我们可以看到,对于大数据量,如果没有Combiner,将会在磁盘上写入多个文件等待ReduceTask来拉取,但是如果有Combiner组件,我们…
MapReduce程序的3种集群提交运行模式详解---基于Windows与Linux两种开发环境
继上一篇博客—-Hadoop本地运行模式深入理解,本篇文章将详细介绍在基于Windows与Linux两种开发环境下,MapReduce程序的3种集群运行方式。在通篇文章中,仍然以经典的WordCount程序为例进行说明,以提高文章的易读性,下面…
MapReduce【mapJoinreduceJoin】
ReduceJoin需求
类似于MySQL的join操作,我们希望将两张表合并为一张表,即将order.txt的pid替换为pd.txt中pid对应的pname。
输入
order.txt
id pid amounts
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
pd.txt
pid pname
0…

MapReduce实战案例(3)
案例三: MR实战之TOPN(自定义GroupingComparator)
项目准备
需求测试数据
有如下订单数据
订单id商品id成交金额Order_0000001Pdt_01222.8Order_0000001Pdt_0525.8Order_0000002Pdt_03522.8Order_0000002Pdt_04122.4Order_0000002Pdt_05722.4Order_0000003Pdt_01222.8
现在…
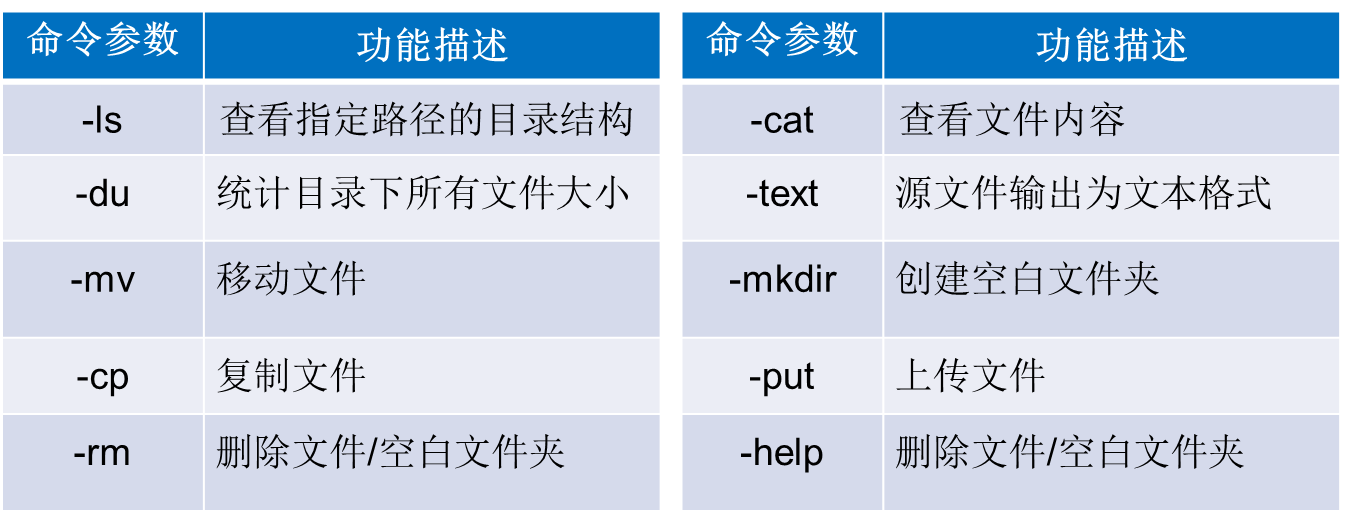
【大数据】大数据相关概念
文章目录 大数据:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型以及价值密度四大特征。Hadoop:是一个能够对大量数据进行分布式处理的软件框…
Hadoop本地运行模式深入理解
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1、独立模式即本地运行模式(standalone或local mode) 无需运行任何守护进程(daemon)…
MapReduce分布式计算(一)
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。
练习:计算a.txt文件中每个单词出现的次数
hello world
hello ha…
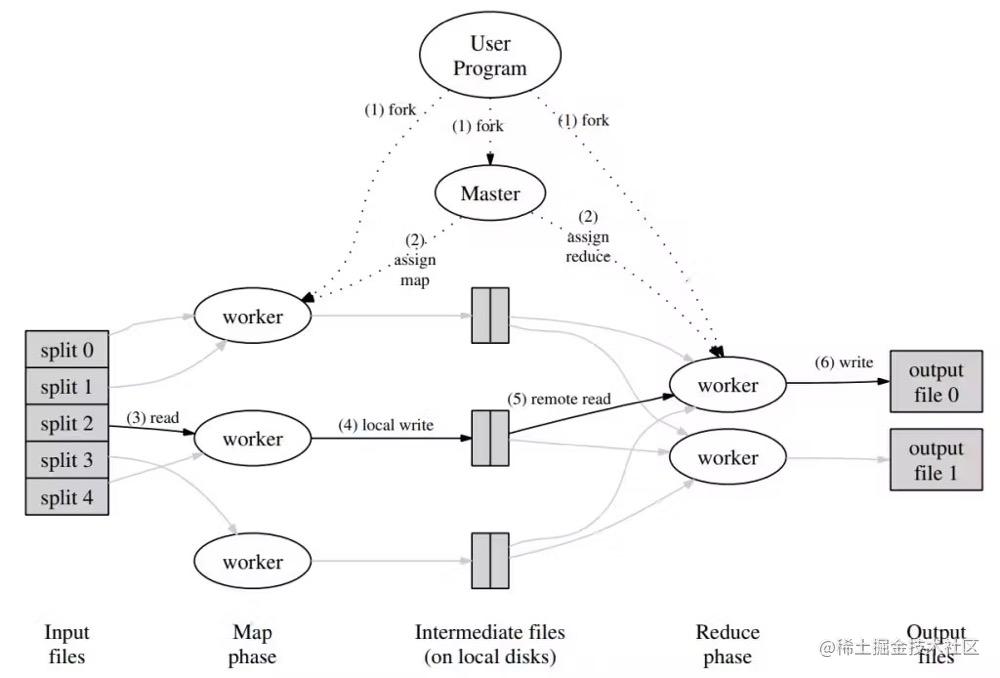
分布式批处理:MapReduce初探
大家好,我是方圆。《数据密集型应用系统设计》第十章中有介绍到 MapReduce 相关的内容,当时觉得看得意犹未尽,所以便找了一些资料又看了一下。随着深入发现能扩展的东西实在太多,考虑时间有限,准备先把 MapReduce 基础…
MapReduce流程及调优
流程原理
1 Map
1.1 map
根据输入,形成切片,并行运行MapTask。(MapTask并行度由切片数决定,每个切片对应一个MapTask)
1.2 partition
map()函数处理后得到的键值对在写入环形缓冲区前,需要先进行分区操…
自己撸一个Wordcount
新建maven工程 修改pom文件 <?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apa…

MapReduce Yarn参数优化
MapReduce & Yarn参数优化资源相关参数容错相关参数本地运行mapreduce 作业效率和稳定性相关参数关于yarn常用参数设置资源相关参数
以下调整参数都在mapred-site.xml这个配置文件当中有
//以下参数是在用户自己的mr应用程序中配置就可以生效
(1) mapreduce.map.memory.…

Spark/Scala - 读取 RcFile OrcFile
一.引言 上文提到了 MapReduce - 读取 OrcFile, RcFile 文件,这里通过 Java MapReduce 实现了读取 RcFile 和 OrcFile 文件,后续又遇到 MapReduce - 同时读取 RcFile 和 OrcFile 的依赖冲突,也顺利解决,但是平常开发还是习惯 spa…
Hadoop上的python框架实现map-reduce
map-reduce框架里面由一个mapper和reducer组成 以键值对的方式处理数据 以对文本中的单词计数为例 mapper所做的事情就是简单的拆分每一行的单词,并且以单词 1 这样的格式输出到stdout 然后经过一个shuffle 和 sort,使mapper的输出根据键值排序ÿ…

Java - MR 读写 orc 之 NoSuchMethodError: hive.ql.exec.vector.VectorizedRowBatch.getMaxSize()
一.引言
上一篇文章提到了 Java map-reduce 如何单独读取 ORC 文件以及 RcFile 文件,在同一个 MR 任务下分别读取 RcFile 以及 ORC 文件时,报如下错误: java.lang.NoSuchMethodError: org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch.getMax…
Hadoop MapReduce任务的执行过程
注:本文注重原理介绍,较少涉及编程实现,有错误请指正,感谢~
在进入正文之前需要了解这几个概念:
HDFS:可以先简单理解为它是一个大型分布式的文件系统,里面存放了大量文件,也可以理…

MapReduce java.io.IOException: No FileSystem for scheme: d
欢迎大家扫码关注我的微信公众号: MapReduce java.io.IOException: No FileSystem for scheme: d一、 异常分析二、 解决方式2.1 解决方式一2.2 解决方式二三、 总结一、 异常分析
最近, 在使用服务器运行 MapReduce 的 jar 包时报了如下错误ÿ…

Hadoop2.8.5 MapReduce计算流程
上一篇我们从宏观的角度从作业认领到分发考察了MapReduce框架。今天我们来探究其内部,从宏观上说, MR 框架主要就是 Map 和 Reduce 这两个阶段。但是实际上远不是那么简单,这两个宏观的阶段都进一步划分成好几个更微观的阶段,前面提到过的排序(Sort )阶段…
mapreduce输出数据保存到本地main函数代码
MapReduce是一种大数据处理框架,它可以将大规模的数据分成多个小块,并使用分布式计算系统中的多台机器并行处理这些小块数据。输出数据通常会被保存在分布式文件系统(如HDFS)中,但是也可以将其保存在本地文件系统中。 如果你想将MapReduce输出…
P11 (*) 游程编码改
问题描述
在P10的算法实现中,若一个元素不连续重复,我们最终也转化为(N E)的形式,即N为1的特殊形式。 该题的要求是特殊处理这一情况,直接将元素复制到结果列表中。如
sash> (encode-modified (a a a a b c c a a d e e e e)…
mongodb MapReduce
MapReduce应该算是MongoDB操作中比较复杂的了,自己开始理解的时候还是动了动脑子的,所以记录在此!命令语法:详细看
?
db.runCommand({ mapreduce : 字符串,集合名,map : 函数,见下文reduce : 函数,见下文[…
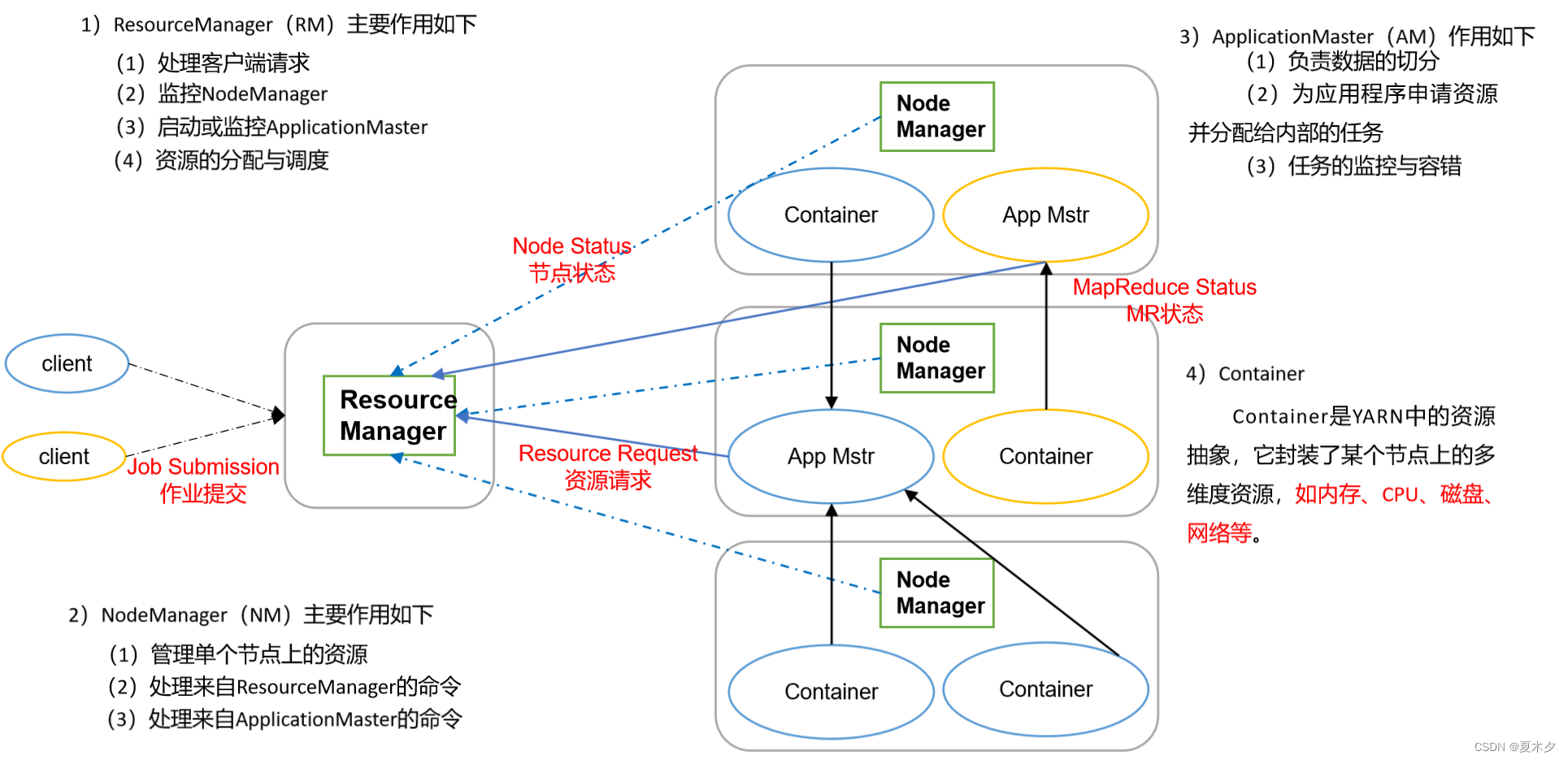
大数据技术学习笔记(一)——初识大数据
1 大数据的概念
大数据:指无法在一定的时间范围内用常规的软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决海量数据的存储和海量数据的分析计…

HiveSQL解析原理:包括SQL转化为MapReduce过程及MapReduce如何实现基本SQL操作
HiveSQL解析原理:包括SQL转化为MapReduce过程及MapReduce如何实现基本SQL操作一、MapReduce实现基本SQL操作的原理1、join的实现原理Map Join的实现原理CommonJoinResolver优化器Reduce Join的实现原理3、Group By的实现原理二、SQL转化为MapReduce的过程Hive是基于…
日均处理万亿条数据,爱奇艺实时计算平台设计
1.爱奇艺 Flink 服务现状
爱奇艺从 2012 年开始开展大数据业务,一开始只有二十几个节点,主要是 MapReduce、Hive 等离线计算任务。到 2014 年左右上线了 Storm、Spark 实时计算服务,并随后发布了基于 Spark 的实时计算平台 Europa。2017 年开…

MapReduce实现与自定义词典文件基于hanLP的中文分词详解
前言: 文本分类任务的第1步,就是对语料进行分词。在单机模式下,可以选择python jieba分词,使用起来较方便。但是如果希望在Hadoop集群上通过mapreduce程序来进行分词,则hanLP更加胜任。 一、使用介绍 hanLP是一个用jav…

这个女人不简单,解决了大数据重大问题
ClearStory Data是一家大数据创业公司,这家公司,不论技术,创始人还是风险投资发方,实力不可小觑。 ClearStory Data利用Google技术帮助公司利用好已经存于许多不同系统上的大量数据,让公司以一种新的眼光看待之前被忽略…
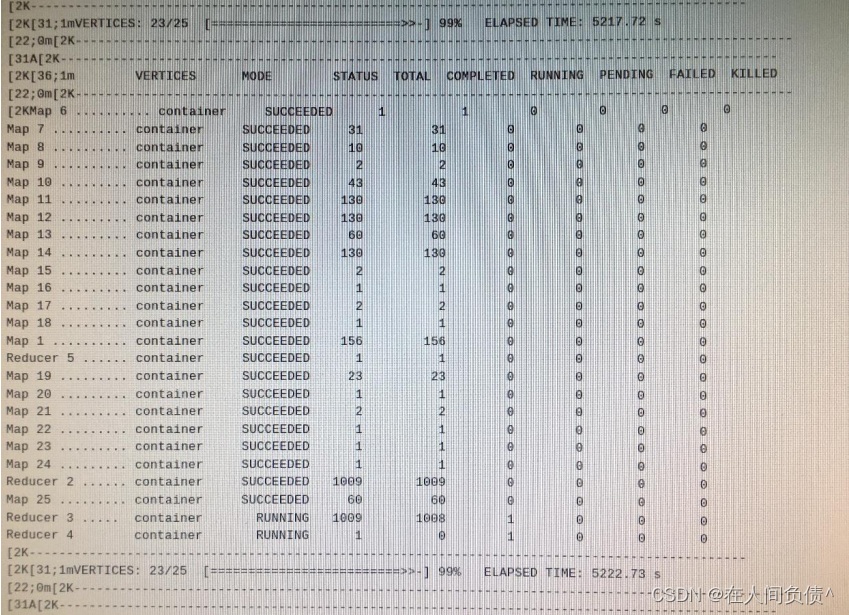
Hadoop 3.x(生产调优手册)----【MapReduce、Hadoop-Yarn生产经验】
Hadoop 3.x(生产调优手册)----【MapReduce、Hadoop-Yarn生产经验】1. MapReduce跑的慢的原因2. MapReduce常用调优参数3. MapReduce数据倾斜问题4. 常用的调优参数1. MapReduce跑的慢的原因
MapReduce 程序效率的瓶颈在于两点:
计算机性能 …


Hadoop 3.x(MapReduce)----【MapReduce 框架原理 六】
Hadoop 3.x(MapReduce)----【MapReduce 框架原理 六】1. 数据清洗(ETL)1. 要求2. 需求分析3. 实现代码2. MapReduce 开发总结1. 输入数据接口:InputFormat2. 逻辑处理接口:Mapper3. Partition分区4. Compar…
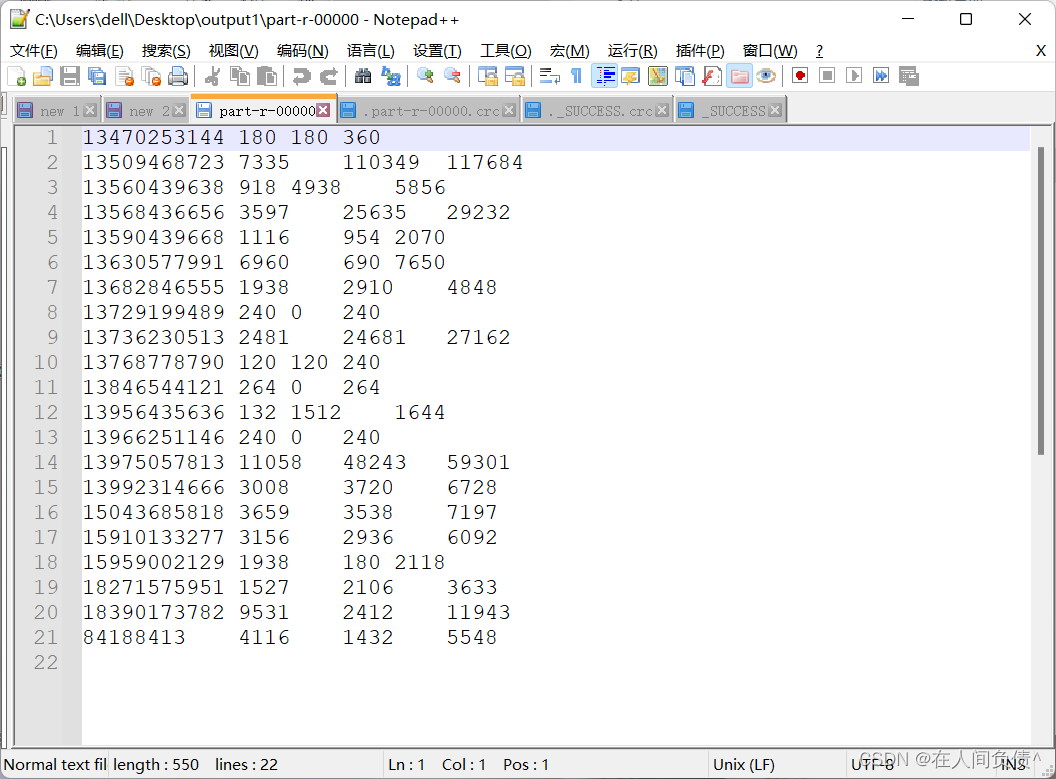
Hadoop 3.x(MapReduce)----【Hadoop 序列化】
Hadoop 3.x(MapReduce)----【Hadoop 序列化】1. 序列化概述1. 什么是序列化2. 为什么要序列化3. 为什么不用Java的序列化4. Hadoop序列化特点:2. 自定义bean对象实现序列化接口(Writable)3. 序列化案例实操1. 需求2. 需…

Maven的梗概介绍以及详细安装步骤
Maven的梗概介绍以及详细安装步骤
(1)Maven这个单词的本意是:专家,内行。读音是[meɪv(ə)n]或[mevn]。
(2)Maven是一款自动化构建工具,专注服务于Java平台的项目构建和依赖管理。在JavaEE开发…
2021-04-30
HBase介绍: 1、分布式开源数据库 2、面向列 3、Big Table开源实现 4、适合非结构化数据的存储 5、PB级别的数据 6、可以支撑在线业务 7、分布式系统特点 8、分布式系统特点:易于扩展,支持动态伸缩,并发数据处理。
面向列数据库 1…
大数据算法——布隆过滤器
今天的文章和大家一起来学习大数据领域一个经常用到的算法——布隆过滤器。如果看过《数学之美》的同学对它应该并不陌生,它经常用在集合的判断上,在海量数据的场景当中用来快速地判断某个元素在不在一个庞大的集合当中。它的原理不难,但是设…
谁能讲清楚Spark之与MapReduce的对比
我们已经知道Spark是如何设计和实现数据处理流程的,这里我们 再深入思考一下,为什么Spark能够替代MapReduce成为主流的大数据处理框架呢?对比MapReduce,Spark究竟有哪些优势?
一 优势
1 通用性: 基于函数式编程思想,MapReduce将数据类型抽象为,k,v格式,并将数据处理…
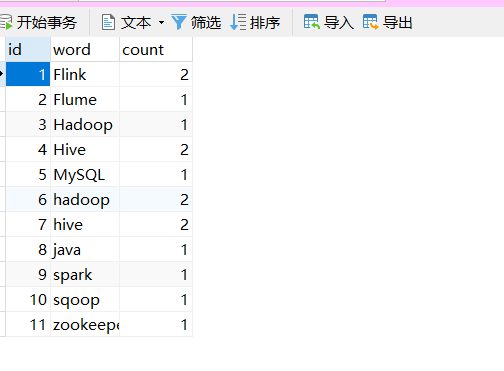
Hadoop的第二个核心组件:MapReduce框架第三节
Hadoop的第二个核心组件:MapReduce框架 九、MR程序运行的核心阶段的细节性知识1、MR程序在运行过程中,涉及到的阶段和作用2、MR程序运行的的第一个组件:InputFormat3、MR程序的Job提交流程的源码分析4、MR程序运行中Mapper组件的作用5、MR程序…
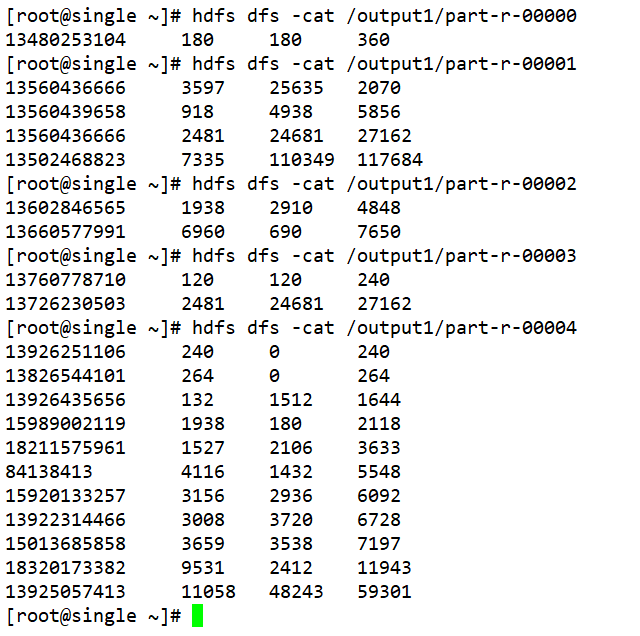
Hadoop的第二个核心组件:MapReduce框架第二节
Hadoop的第二个核心组件:MapReduce框架第二节 六、MapReduce的工作流程原理(简单版本)七、MapReduce中的序列化机制问题八、流量统计案例实现(序列化机制的实现) 六、MapReduce的工作流程原理(简单版本&…
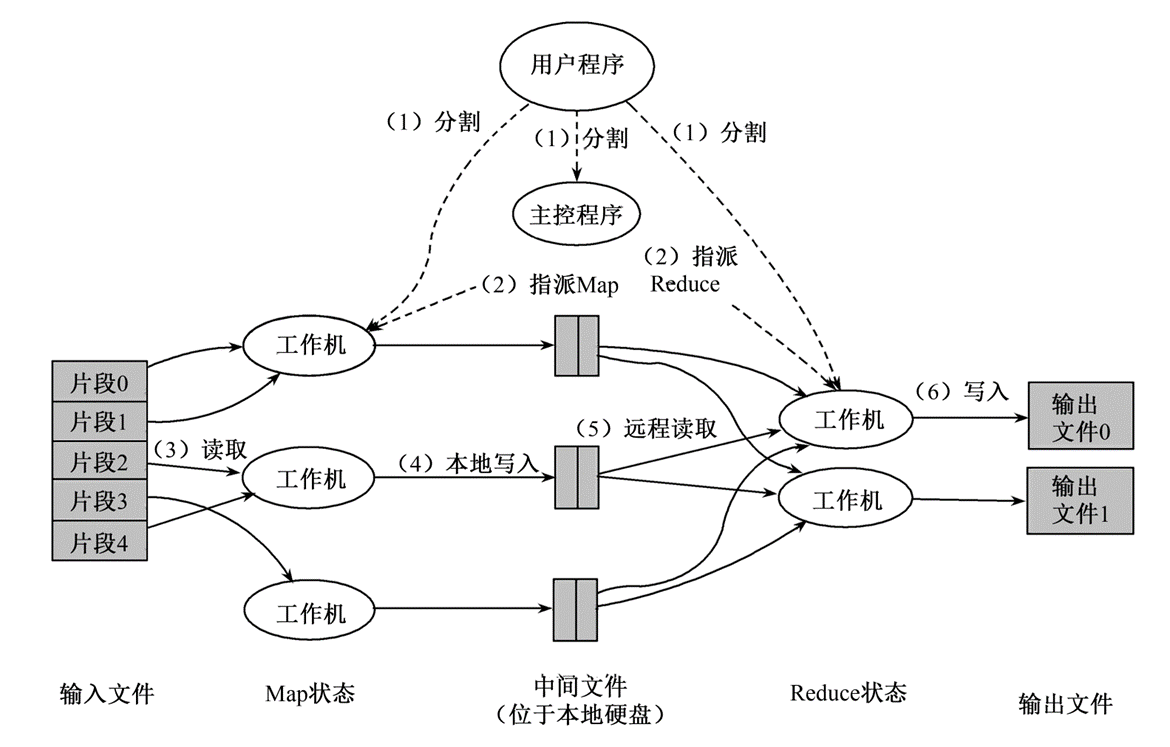
分布式数据处理MapReduce简单了解
文章目录 产生背景编程模型统计词频案例 实现机制容错机制Master的容错机制Worker的容错机制 产生背景 MapReduce是一种分布式数据处理模型和编程技术,由Google开发,旨在简化大规模数据集的处理。产生MapReduce的背景:
数据量的急剧增长&…
Hadoop学习总结(MapReduce的数据去重)
现在假设有两个数据文件
file1.txtfile2.txt2018-3-1 a 2018-3-2 b 2018-3-3 c 2018-3-4 d 2018-3-5 a 2018-3-6 b 2018-3-7 c 2018-3-3 c2018-3-1 b 2018-3-2 a 2018-3-3 b 2018-3-4 d 2018-3-5 a 2018-3-6 c 2018-3-7 d 2018-3-3 c 上述文件 file1.txt 本身包含重复数据&…

MIT 6.824 -- MapReduce Lab
MIT 6.824 -- MapReduce Lab 环境准备实验背景实验要求测试说明流程说明 实验实现GoLand 配置代码实现对象介绍协调器启动工作线程启动Map阶段分配任务执行任务 Reduce 阶段分配任务执行任务 终止阶段 崩溃恢复 注意事项并发安全文件转换golang 知识点 测试 环境准备
从官方gi…

十二、MapReduce概述
1、MapReduce
(1)采用框架
MapReduce是“分散——>汇总”模式的分布式计算框架,可供开发人员进行相应计算
(2)编程接口:
~Map
~Reduce
其中,Map功能接口提供了“分散”的功能ÿ…
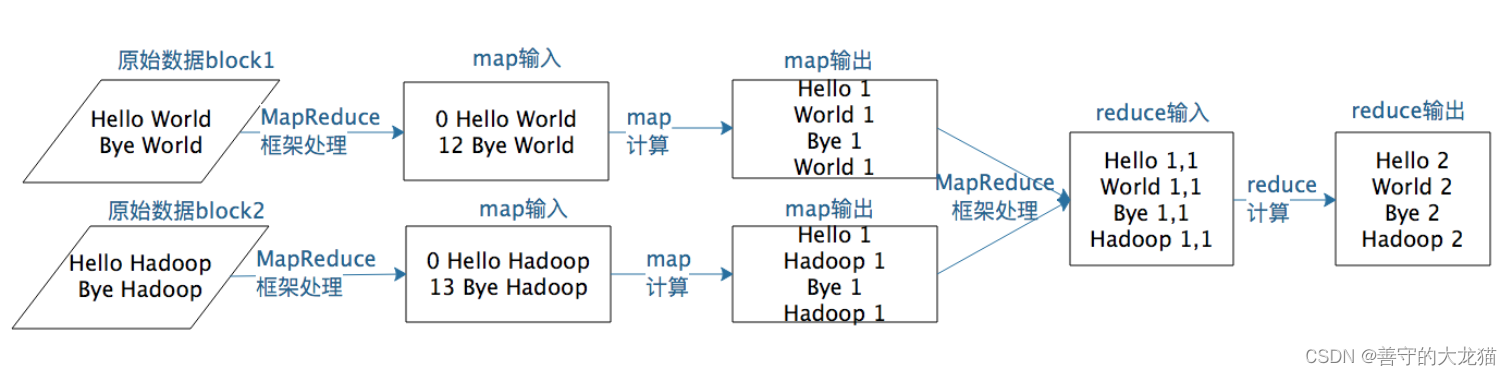
大数据 MapReduce是什么?
在Hadoop问世之前,其实已经有了分布式计算,只是那个时候的分布式计算都是专用的系统,只能专门处理某一类计算,比如进行大规模数据的排序。
很显然,这样的系统无法复用到其他的大数据计算场景,每一种应用都…
Hadoop之mapreduce参数大全-8
176.指定 JobHistoryServer 在缓存中存储的日期字符串的最大数量
mapreduce.jobhistory.datestring.cache.size 是 Apache Hadoop MapReduce 中的一个配置属性,用于指定 JobHistoryServer 在缓存中存储的日期字符串的最大数量。
以下是对该配置属性的解释…

大数据开发之Hadoop(MapReduce)
第 1 章:MapReduce概述
1.1 MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并…
Hadoop-MapReduce-源码跟读-客户端篇
一、源码下载
下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧
Index of /dist/hadoop/core
二、从WordCount进入源码
用idea将源码加载进来后,找到org.apache.hadoop.examples.WordCount类(快捷方法&…
6.0 MapReduce 服务使用教程
在学习了之前的 MapReduce 概念之后,我们应该已经知道什么是 Map 和 Reduce,并了解了他们的工作方式。
本章将学习如何使用 MapReduce。
Word Count
Word Count 就是"词语统计",这是 MapReduce 工作程序中最经典的一种。它的主要…
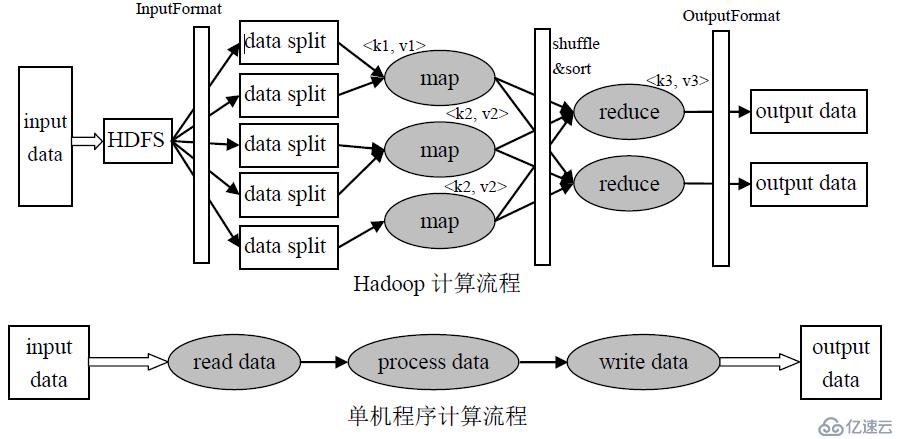
Hadoop:认识MapReduce
MapReduce是一个用于处理大数据集的编程模型和算法框架。其优势在于能够处理大量的数据,通过并行化来加速计算过程。它适用于那些可以分解为多个独立子任务的计算密集型作业,如文本处理、数据分析和大规模数据集的聚合等。然而,MapReduce也有…
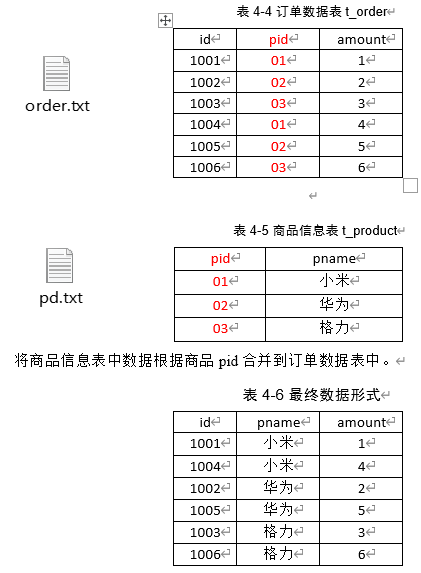
大数据技术学习笔记(五)—— MapReduce(2)
目录 1 MapReduce 的数据流1.1 数据流走向1.2 InputFormat 数据输入1.2.1 FileInputFormat 切片源码、机制1.2.2 TextInputFormat 读数据源码、机制1.2.3 CombineTextInputFormat 切片机制 1.3 OutputFormat 数据输出1.3.1 OutputFormat 实现类1.3.2 自定义 OutputFormat 2 Map…
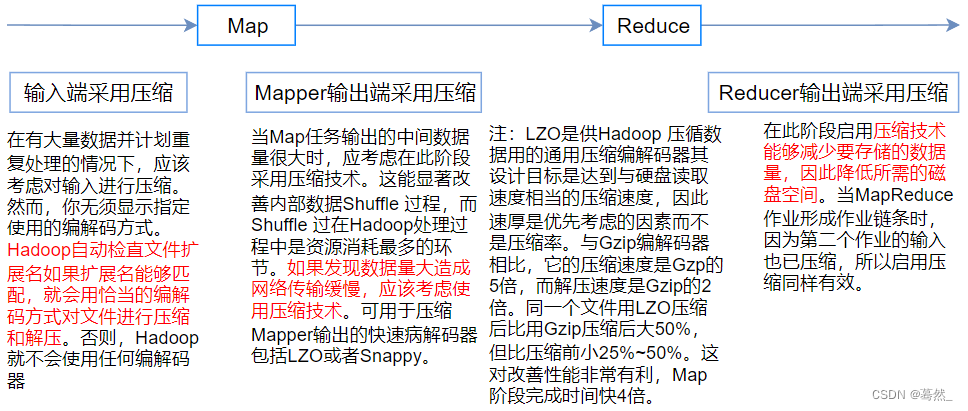
大数据面试题:MapReduce压缩方式
面试题来源:
《大数据面试题 V4.0》
大数据面试题V3.0,523道题,679页,46w字
可回答:1)Hadoop常见的压缩算法有哪些?
问过的一些公司:网易云音乐(2022.11),阿里(2020.…
MapReduce-Partition分区
Partition分区
1.默认Partitioner分区
(key.hashcode() & Interger.MAX_VALUE) % numReduceTasksnumReduceTasks默认为:1
//输出文件一个默认分区根据key的hashCode对ReduceTasks个数取模。
用户控制那个key存储到那个分区2.手动设置分区
//设置分区
job.set…
Hadoop的第二个核心组件:MapReduce框架第四节
Hadoop的第二个核心组件:MapReduce框架 十、MapReduce的特殊应用场景1、使用MapReduce进行join操作2、使用MapReduce的计数器3、MapReduce做数据清洗 十一、MapReduce的工作流程:详细的工作流程第一步:提交MR作业资源第二步:运行M…
map-reduce执行过程
Map阶段
Map 阶段是 MapReduce 框架中的一个重要阶段,它负责将输入数据转换为中间数据。Map 阶段由一个或多个 Map 任务组成,每个 Map 任务负责处理输入数据的一个子集。
执行步骤
Map 阶段的过程可以分为以下几个大步骤:
输入数据分配&a…

Middleware ❀ Hadoop功能与使用详解(HDFS+YARN)
文章目录 1、服务概述1.1 HDFS1.1.1 架构解析1.1.1.1 Block 数据块1.1.1.2 NameNode 名称节点1.1.1.3 Secondary NameNode 第二名称节点1.1.1.4 DataNode 数据节点1.1.1.5 Block Caching 块缓存1.1.1.6 HDFS Federation 联邦1.1.1.7 Rack Awareness 机架感知 1.1.2 读写操作与可…

hadoop HDFS分布式计算概述,MapReduce概述,YARN概述
1、分布式计算概述
1.1、什么是(数据)计算
我们一直在提及:分布式计算, 分布式暂且不论, “计算”到底是指什么呢?
大数据体系内的计算, 举例:
销售额统计、区域销售占比、季度…
Hadoop3教程(十七):MapReduce之ReduceJoin案例分析
文章目录 (113)ReduceJoin案例需求分析(114)ReduceJoin案例代码实操 - TableBean(115)ReduceJoin案例代码实操 - TableMapper(116)ReduceJoin案例代码实操 - Reducer及Driver参考文献…

![MapReduce [OSDI‘04] 论文阅读笔记](https://img-blog.csdnimg.cn/direct/5ce9c9cff2de4ad889f25585f1ac910c.png#pic_center)
MapReduce [OSDI‘04] 论文阅读笔记
原论文:MapReduce: Simplified Data Processing on Large Clusters (OSDI’04) 1. Map and Reduce
Map:处理键值对,生成一组中间键值对Reduce:合并与同一中间键相关的所有中间值process overview:分割输入数据&#x…
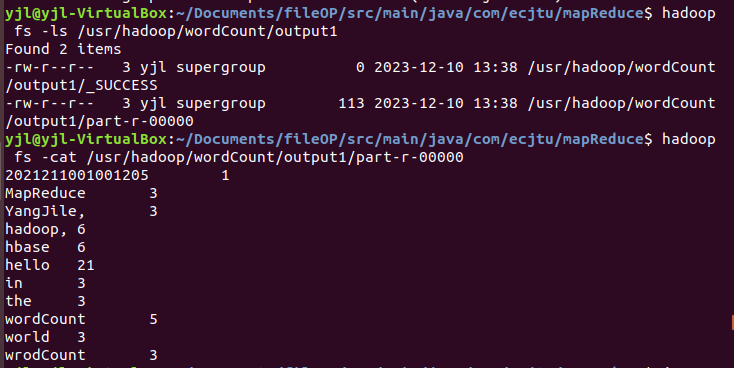
大数据实验四-MapReduce编程实践
一.实验内容
MapReduce编程实践:
使用MapReduce实现多个文本文件中WordCount词频统计功能,实验编写Map处理逻辑、编写Reduce处理逻辑、编写main方法。
二.实验目的
1、通过实验掌握基本的MapReduce编程方法。
2、实现统计HDF…
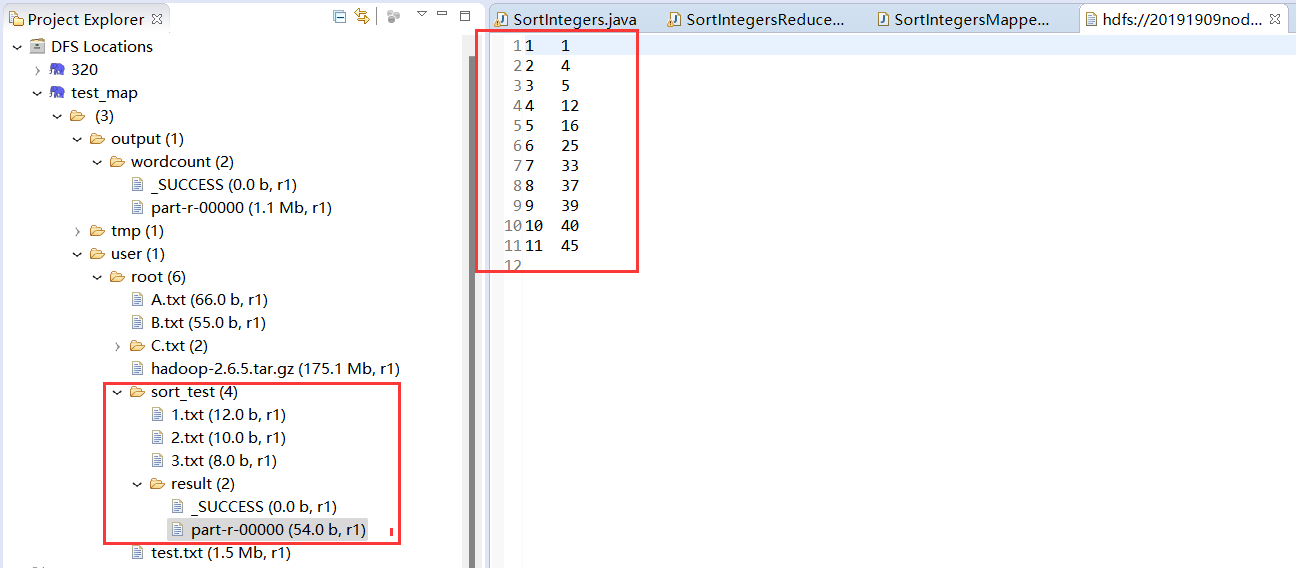
【分布式计算框架】 MapReduce编程初级实践
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux 😘欢迎 ❤️关注 👍点赞 🙌收藏 ✍️留言 文章目录 MapReduce编程初级实践一、实验目的二、实验环境三、实验内容mapreduce高可用环境配置编程WordCoun…
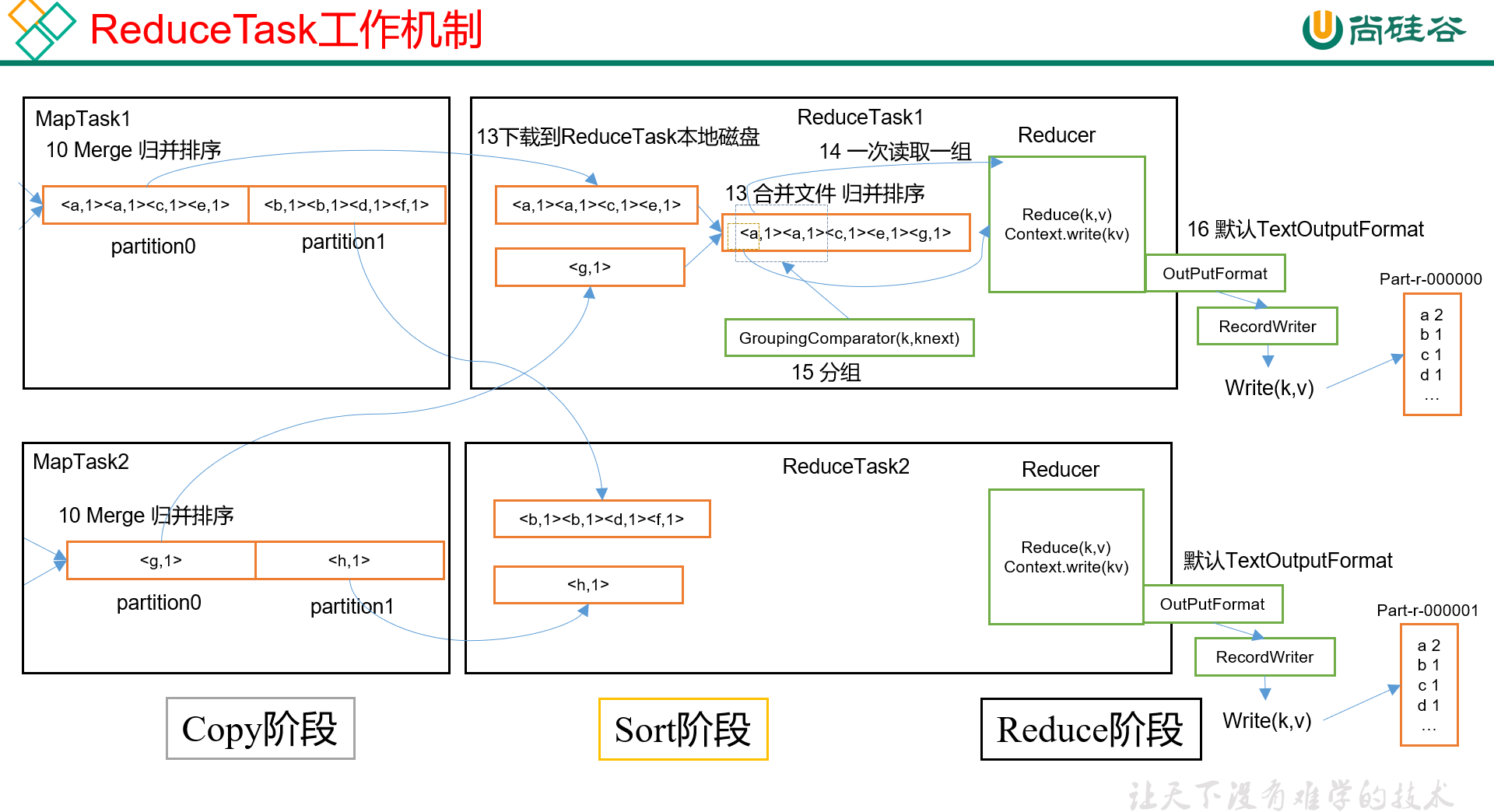
Hadoop3教程(二十):MapReduce的工作机制总结
文章目录 (109)MapTask工作机制(110)ReduceTask工作机制&并行度ReduceTask工作机制MapTask和ReduceTask的并行度决定机制 (122)MapReduce开发总结参考文献 (109)MapTask工作机制…
sqoop:错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster(已解决)
1 报错信息 错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster 说明: 操作将数据库中的数据导入到HDFS中 执行sqoop import --connect jdbc:mysql://aaa01:3306/mysql --username root --password root --table test 时报了以下错误 2 报…
MapReduce面试题+详解
MapReduce篇面试题 1.“MapReduce”程序的主要配置参数是什么?
“MapReduce”框架中用户需要指定的主要配置参数有:
分布式文件系统中作业的输入位置作业在分布式文件系统中的输出位置数据输入格式数据输出格式包含地图功能的类包含 reduce 函数的类包…
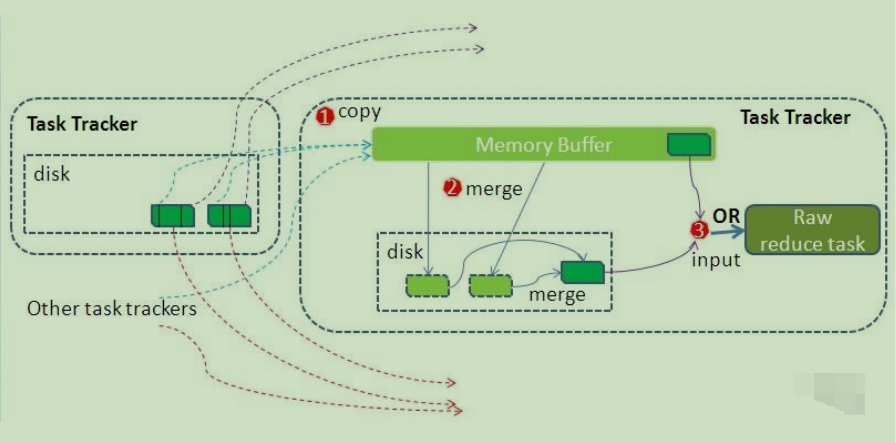
【底层服务/编程功底系列】「大数据算法体系」带你深入分析MapReduce算法 — Shuffle的执行过程
【底层服务/编程功底系列】「大数据算法体系」带你深入分析MapReduce算法 — Shuffle的执行过程 Shuffle是什么Shuffle的流程处理map任务的执行流程reduce任务的执行流程 Shuffle过程分析和优化map任务深入分析细化步骤分析1. 数据分片读取2. 分配计算Reduce服务Partitioner分区…
2023.12.3 分布式SQL查询引擎-Presto
目录 1.Prosto简介
Apache Hadoop-MapReduce
Apache Hive
2.Presto的优缺点
3.个人自用启动服务
个人自用启动服务
4.presto和hive的区别
5.presto优化 1.Prosto简介 Apache Hadoop-MapReduce 优点:统一、通用、简单的编程模型,分而治之思想处理…
创建你的深度学习服务器
在30分钟内创建你的深度学习服务器
从安装Anaconda开始,最后为Pytorch和Tensorflow创建不同的环境,这样它们就不会相互干扰。而在这中间,你不可避免地会搞砸,从头开始。这种情况经常发生多次。
这不仅是对时间的巨大浪费&#x…
mongodb聚合_删除_可视化工具
3.5 MongoDB中limit和skip
MongoDB Limit() 方法
如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。limit()方法基本语法如下所示:…
hadoop实例(java模板):数字逆序输出 (自定义mapper,reducer,自定义key2类型,重写compareTo函数,HDFS操作)
主要是整理了mapreduce常用的操作模板 主函数(请忽略主类的名字。。忘记改了): package hadoop.wordCount;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache…
Hadoop-MapReduce-YarnChild启动篇
一、源码下载
下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧
Index of /dist/hadoop/core
二、上下文
在上一篇<Hadoop-MapReduce-MRAppMaster启动篇>中已经将到:MRAppMaster的启动,那么运行M…
论文阅读-MapReduce
论文名称:MapReduce: Simplified Data Processing on Large Clusters
翻译的效果不是很好,有空再看一遍,参照一下别人翻译的。
MapReduce:Simplified Data Processing on Large Clusters 中文翻译版(转) - 阿洒 - 博客园 (cnblogs.com)
概…
Hadoop-MapReduce-源码跟读-MapTask阶段篇
一、源码下载
下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧
Index of /dist/hadoop/core
二、Mapper类
我们先看下我们写的map所继承的Mapper类
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {/*** 传递…
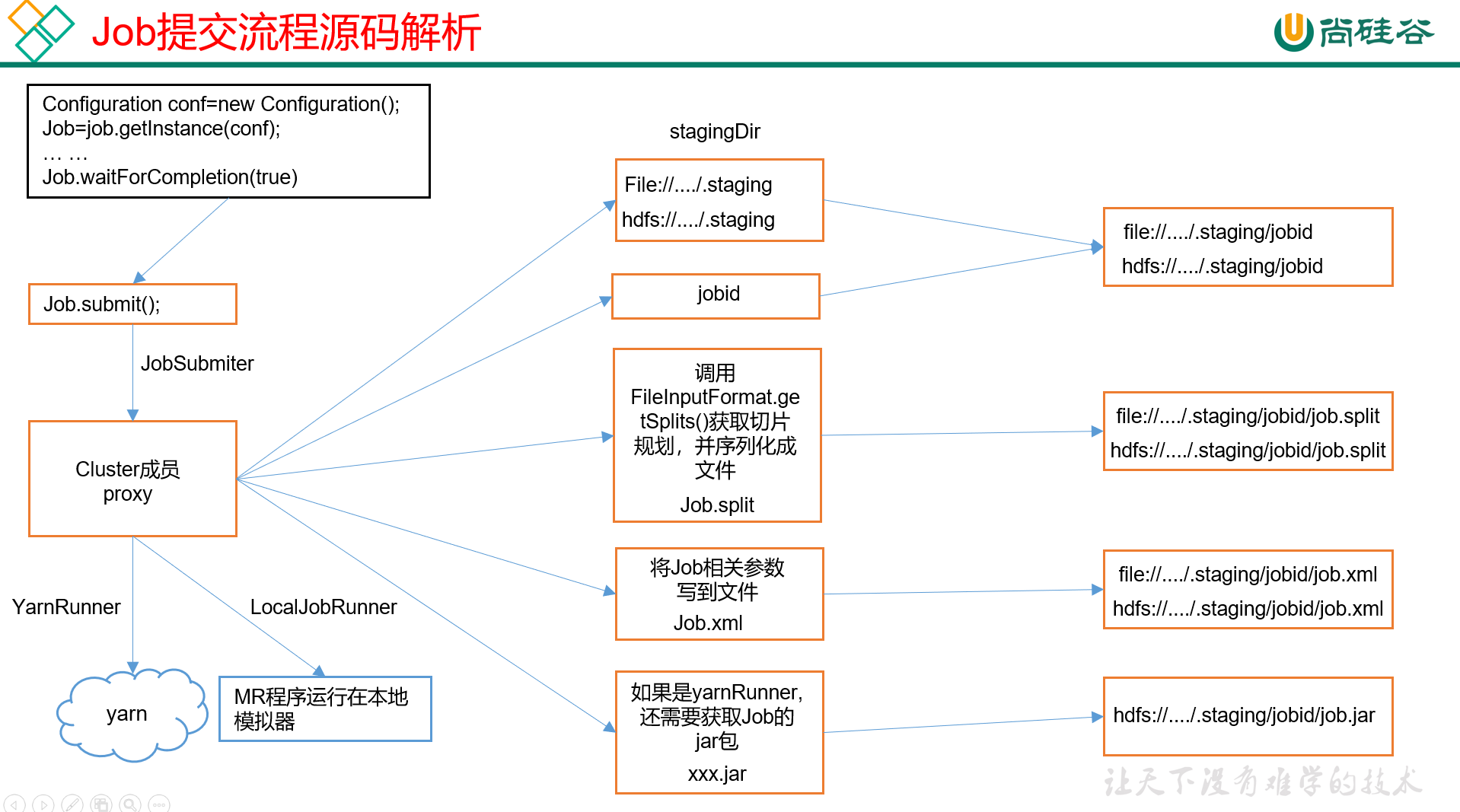
Hadoop3教程(十):MapReduce中的InputFormat
文章目录 (87)切片机制与MapTask并行度决定机制(90) 切片源码总结(91)FileInputFormat切片机制(92)TextInputFormat及其他实现类一览(93) CombineTextInputFo…
SequenceFile、元数据操作与MapReduce单词计数
文章目录 SequenceFile、元数据操作与MapReduce单词计数一、实验目标二、实验要求三、实验内容四、实验步骤附:系列文章 SequenceFile、元数据操作与MapReduce单词计数
一、实验目标
熟练掌握hadoop操作指令及HDFS命令行接口掌握HDFS SequenceFile读写操作掌握Map…
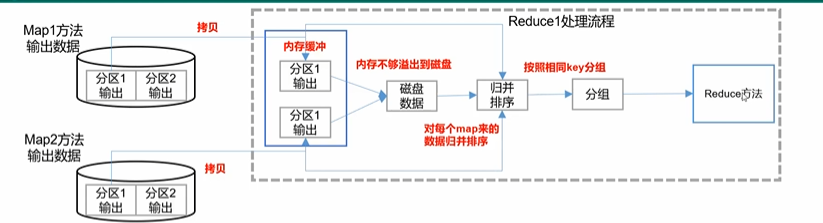
Hadoop3教程(三十四):(生产调优篇)MapReduce生产经验汇总
文章目录 (164)MR跑得慢的原因(165)MR常用调优参数Map阶段Reduce阶段 (166)MR数据倾斜问题参考文献 (164)MR跑得慢的原因
MR程序执行效率的瓶颈,或者说当你觉得你的MR程…
Hadoop自定义复杂类型流量统计wordcount详解
需求:统计每个手机上行流量和下行流量,总的流量和(上行流量下行流量) 1.数据文件:Access.log
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157995052 13826544101 5C-0…
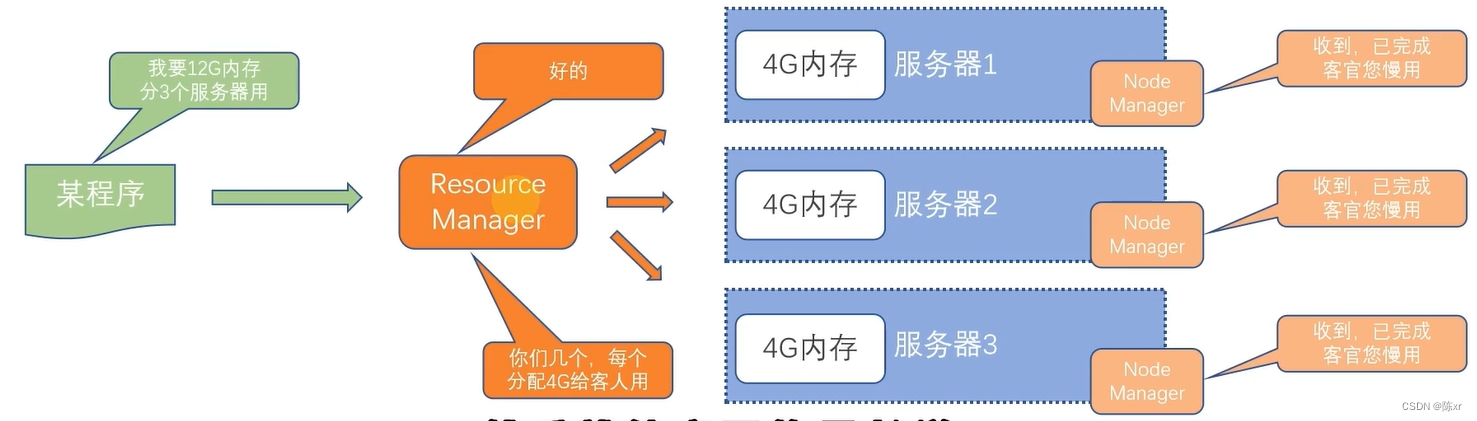
2024-01-31(MapReduce,YARN)
1.MapReduce --- 分布式计算框架
MapReduce是分散--->汇总模式的分布式框架,可以供开发人员开发相关程序进行分布式数据计算
MapReduce提供了2个编程接口:Map接口,Reduce接口
其中,Map接口提供了“分散”功能,由…
十七、如何将MapReduce程序提交到YARN运行
1、启动某个节点的某一个用户
hadoopnode1:~$ jps
13025 Jps
hadoopnode1:~$ yarn --daemon start resourcemanager
hadoopnode1:~$ jps
13170 ResourceManager
13253 Jps
hadoopnode1:~$ yarn --daemon start nodemanager
hadoopnode1:~$ jps
13170 ResourceManager
15062 Jp…
Hadoop-MapReduce-源码跟读-ReduceTask阶段篇
一、源码下载
下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧
Index of /dist/hadoop/core
二、Reducer类
我们先看下我们写的reduce所继承的Reducer类 public class Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {/*** 传…
初学Hadoop:mapreduce的一些理解
MapReduce是一种编程模型,编写很少的代码就可以实现很强大的计算功能。它主要体现了分治思想,就是把一个大问题分成相同的一些小问题,最后将小问题的结果汇总起来。
这里我是用一个数扑克牌的问题来帮助自己理解的。比如一副不完整的扑克牌&…
基于MapReduce的Hive数据倾斜场景以及解决方案
文章目录 1 Hive数据倾斜的现象1.1 Hive数据倾斜的场景1.2 解决数据倾斜问题的排查思路 2 解决Hive数据倾斜问题的方法2.1 开启负载均衡2.2 引入随机性2.3 使用MapJoin或Broadcast Join2.4 调整数据存储格式2.5 分桶表、分区表2.6 使用抽样数据进行优化2.7 过滤倾斜join单独进行…
spark 与 mapreduce 对比
Spark 为什么比 MapReduce 快总结
首先澄清几个误区: 1)两者都是基于内存计算的,任何计算框架都肯定是基于内存的,所以说网上所说的 Spark 是基于内存计算所以快,显然是错误的。 2)DAG 计算模型减少的是磁…
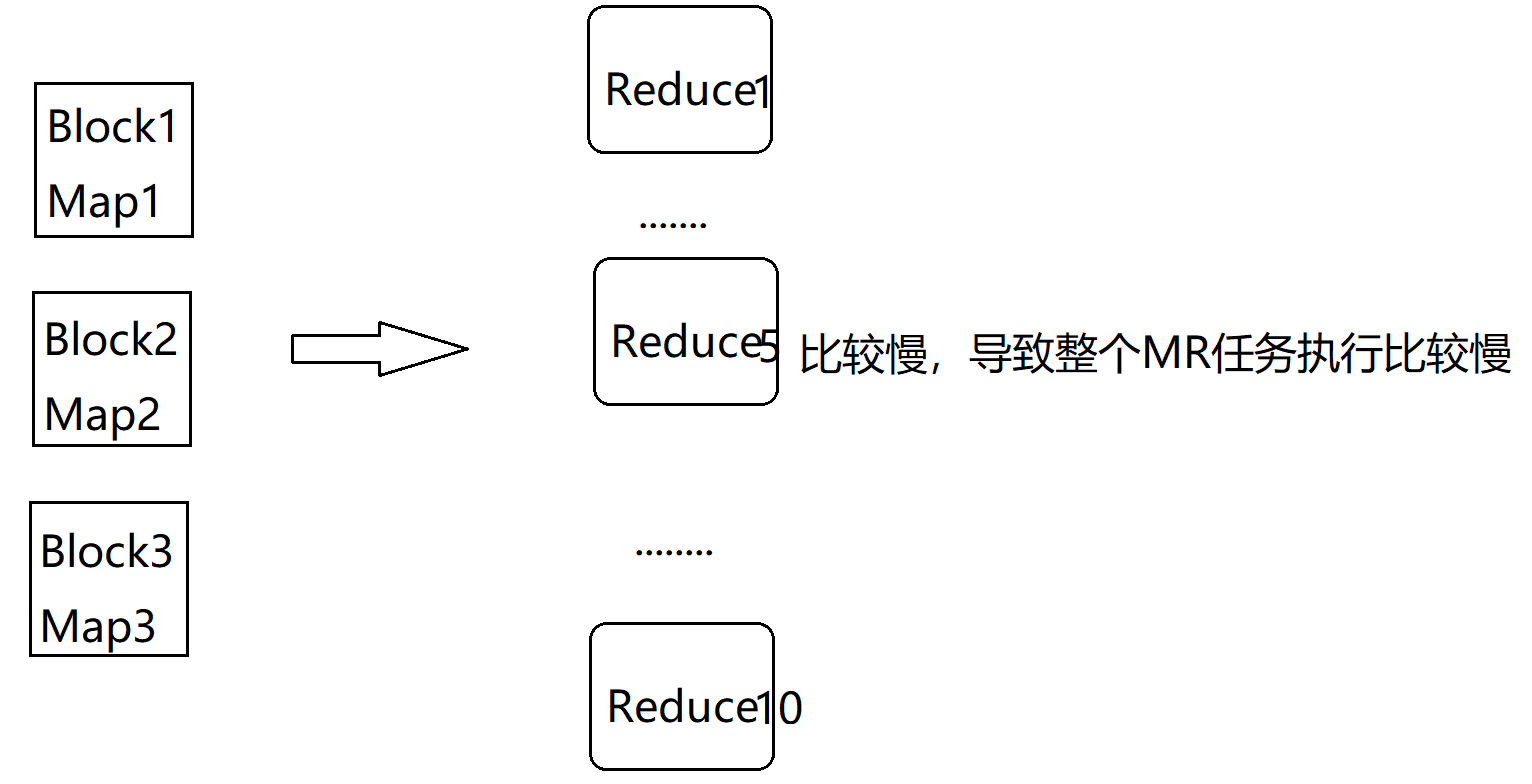
MapReduce性能优化之小文件问题和数据倾斜问题解决方案
文章目录 MapReduce性能优化小文件问题生成SequenceFileMapFile案例 :使用SequenceFile实现小文件的存储和计算 数据倾斜问题实际案例 MapReduce性能优化
针对MapReduce的案例我们并没有讲太多,主要是因为在实际工作中真正需要我们去写MapReduce代码的场…
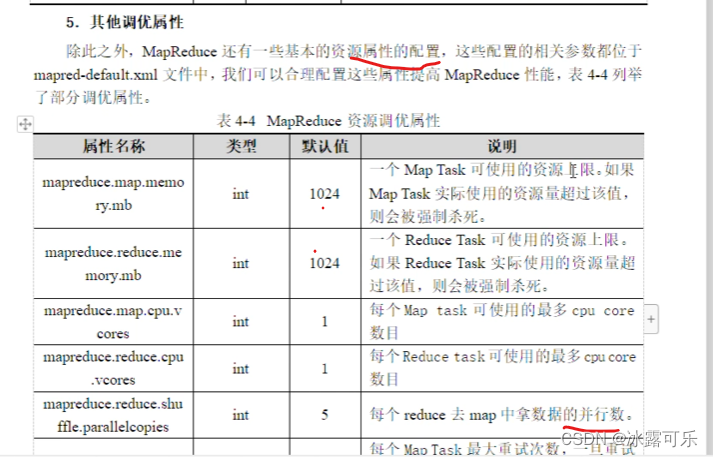
Hadoop原理,HDFS架构,MapReduce原理
Hadoop原理,HDFS架构,MapReduce原理
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,…
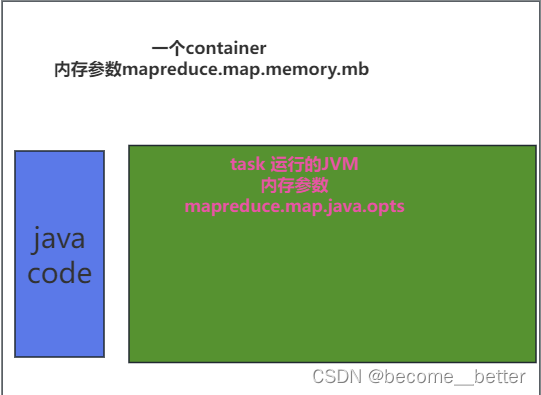
MapReduce内存参数自动推断
MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,涉及到两个参数:mapreduce.{map,reduce}.memory.mb和mapreduce.{map,reduce}.java.opts,一旦设置不合理,则会使得内存资源浪费严重&a…
【大数据技术】实验2:熟悉常用的HDFS操作和基于MapReduce的词频统计
文章目录一、实验环境二、实验内容利用Hadoop提供的Shell命令完成以下任务利用HDFS的Java API编程实现以下任务功能编写MapReduce程序实现以下任务功能出现的问题一、实验环境
操作系统:Linux(建议Ubuntu16.04或Ubuntu18.04);Had…
Hadoop的hdfs
1、Hadoop是什么 实际应用:
(1)FlumeLogstashKafkaSpark Streaming进行实时日志处理分析 1.1、小故事版本的解释
小明接到一个任务:计算一个100M的文本文件中的单词的个数,这个文本文件有若干行,每行有若…

Google云计算原理与应用(一)
目录 一、Google文件系统GFS(一)系统架构(二)容错机制(三)系统管理技术 二、分布式数据处理MapReduce(一)产生背景(二)编程模型(三)实…
MapReduce超详解
简介
概述
MapReduce是Hadoop提供的一套用于进行分布式计算的模型,本身是Doug Cutting根据Google的<MapReduce: Simplified Data Processing on Large Clusters>仿照实现的。
MapReduce由两个阶段组成:Map(映射)阶段和Reduce(规约)阶段,用户只需要实现map以及reduc…

Hive详解(一篇文章让你彻底学会Hive)
简介
概述
Hive是由Facebook(脸书)开发的后来贡献给了Apache的一套数据仓库管理工具,针对海量的结构化数据提供了读、写和管理的功能。 图-1 Hive图标
Hive本身是基于Hadoop,提供了类SQL(Hive Query Language,简称为HQL)语言来操作HDFS上的…
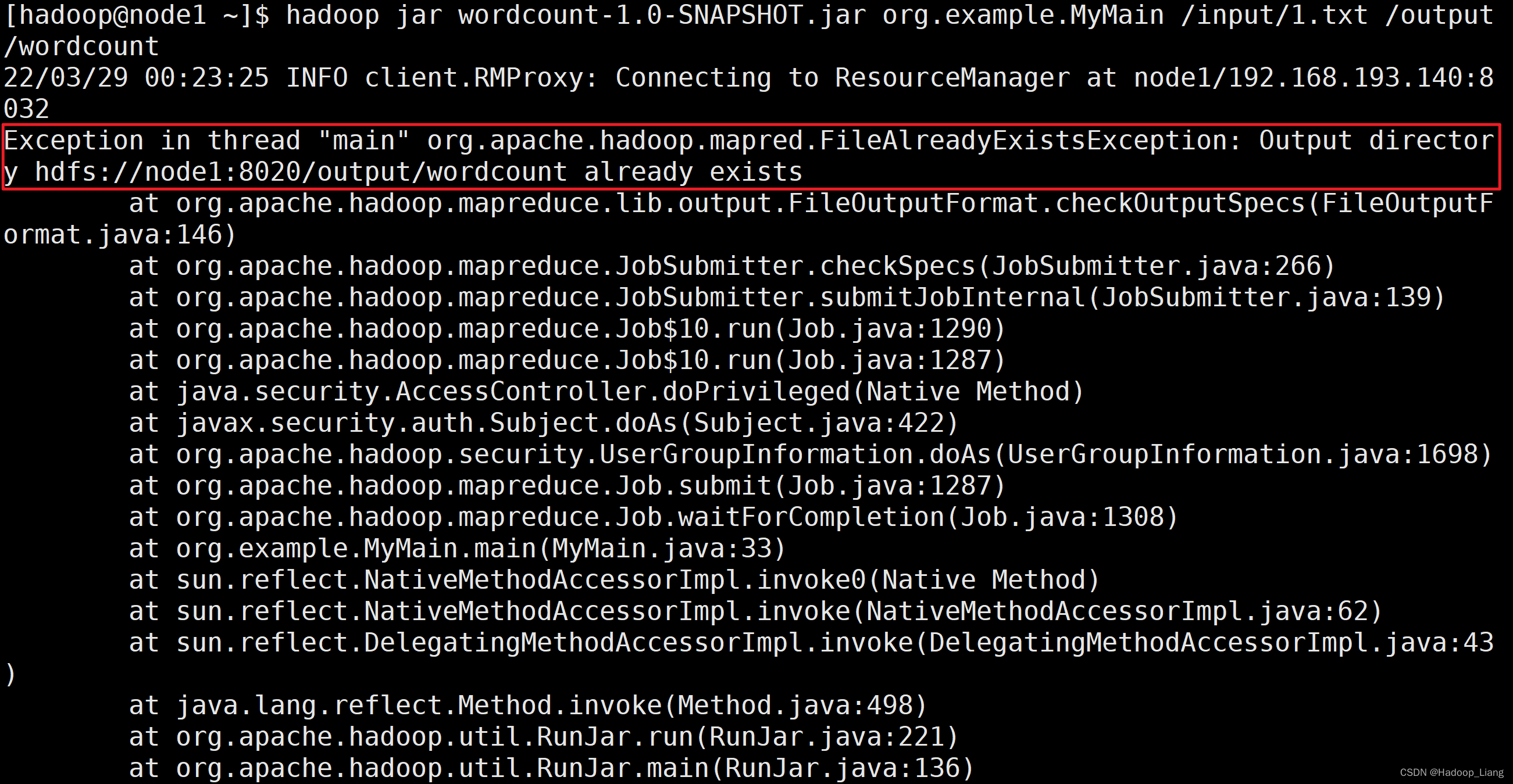
MapReduce WordCount程序实践(IDEA版)
环境
Linux:Hadoop2.x
Windows:jdk1.8、Maven3、IDEA2021
步骤
编程分析 编程分析包括: 1.数据过程分析:数据从输入到输出的过程分析。 2.数据类型分析:Map的输入输出类型,Reduce的输入输出类型&#x…
MapReduce:大数据处理的范式
一、介绍 在当今的数字时代,生成和收集的数据量正以前所未有的速度增长。这种数据的爆炸式增长催生了大数据领域,传统的数据处理方法往往不足。MapReduce是一个编程模型和相关框架,已成为应对大数据处理挑战的强大解决方案。本文探讨了MapRed…
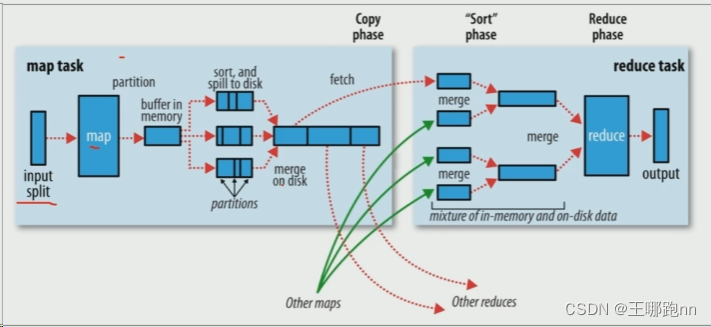
大数据 - Hadoop系列《四》- MapReduce(分布式计算引擎)的核心思想
上一篇:
大数据 - Hadoop系列《三》- MapReduce(分布式计算引擎)概述-CSDN博客 目录
13.1 MapReduce实例进程
13.2 阶段组成
13.4 概述
13.4.1 🥙Map阶段(映射)
13.4.2 🥙Reduce阶段执行过…
Hadoop之mapreduce参数大全-3
51.指定Shuffle传输过程中可以同时连接的节点数
mapreduce.shuffle.max.connections是Hadoop MapReduce中的一个配置参数,用于指定Shuffle传输过程中可以同时连接的节点数。该参数用于控制Shuffle传输的并发度,以保障任务的稳定性和性能。
可以通过以下…
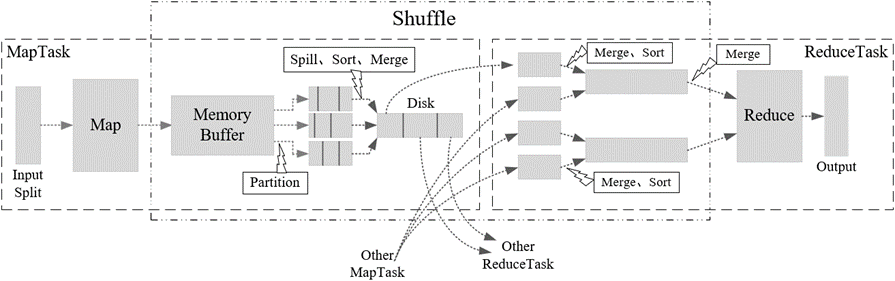
【Hadoop大数据技术】——MapReduce分布式计算框架(学习笔记)
📖 前言:MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算问题,是目前分布式计算模型中应用较为广泛的一种。 目录 🕒 1. MapReduce概述&am…

【Hadoop大数据技术】——MapReduce经典案例实战(倒排索引、数据去重、TopN)
📖 前言:MapReduce是一种分布式并行编程模型,是Hadoop核心子项目之一。实验前需确保搭建好Hadoop 3.3.5环境、安装好Eclipse IDE
🔎 【Hadoop大数据技术】——Hadoop概述与搭建环境(学习笔记) 目录 &#…
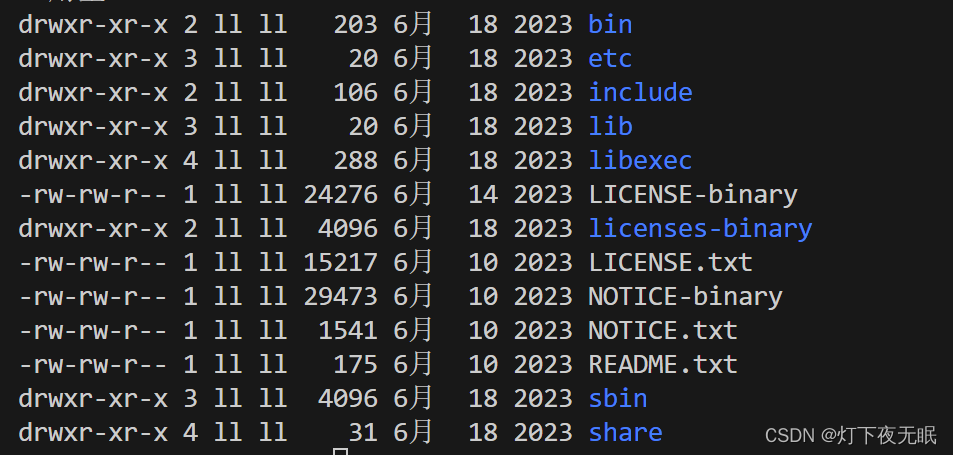
Linux(centos7)部署hadoop集群
部署环境要求:已完成JDK环境部署、配置完成固定IP、SSH免费登录、防火墙关闭等。
1、下载、上传主机 官网:https://hadoop.apache.org 2、解压缩、创建软连接 解压:
tar -zxvf hadoop-3.3.6.tar.gz软连接:
ln -s /usr/local/apps/hadoop-3.3.6 hadoop3、文件配置 hadoo…
大数据开发-Hadoop之MapReduce
文章目录 MapReduce原理剖析MapReduce之Map阶段MapReduce之Reduce阶段WordCount分析多文件WordCount分析 实战wordCount案例开发 MapReduce原理剖析
MapReduce是一种分布式计算模型,主要用于搜索领域,解决海量数据的计算问题MapReduce由两个阶段组成:Ma…
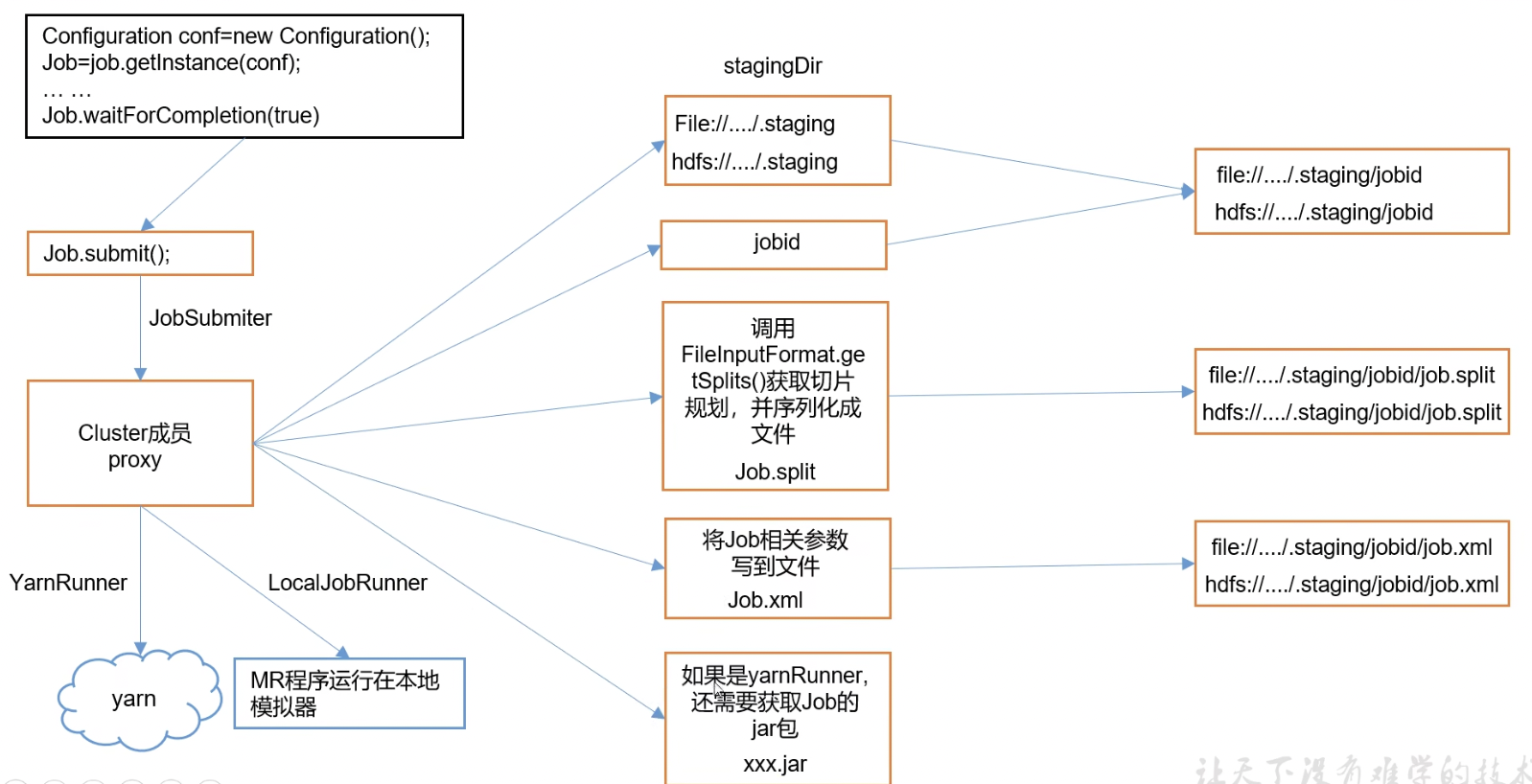
【MapReduce】03.MapReduce框架原理
1.InputFormat数据输入
1.1.切片与MapTask并行度决定机制 MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
MapTask并行度决定机制 数据块:Block是HDFS物理上的数据分割,数据块是HDFS存储数据单位 数据切片&…
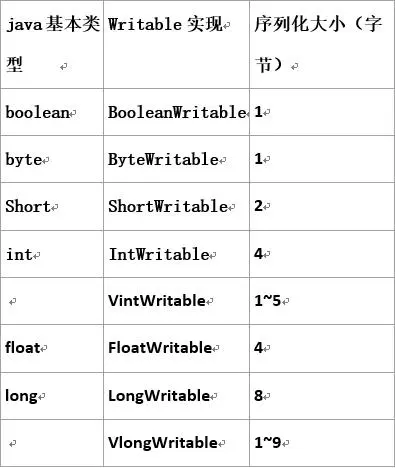
大数据开发-Hadoop之深入MapReduce
文章目录 MapReduce任务日志查看停止Hadoop集群中的任务MapReduce程序扩展Shuffle过程详解Hadoop中的序列化机制 MapReduce任务日志查看
需要开启YARN的日志聚合功能,把散落在NodeManager节点上的日志统一收集管理,方便日志查看
[roothadoop01 hadoop]…
基于MapReduce的汽车数据清洗与统计案例
数据简介
ecar168.csv(汽车销售数据表):
字段数据类型字段说明rankingString排名manufacturerString厂商vehicle_typeString车型monthly_sales_volumeString月销量accumulated_this_yearString本年累计last_monthString上月chain_ratioStri…

Python 3 使用Hadoop 3之MapReduce总结
MapReduce 运行原理
MapReduce简介
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
MapReduce分成两个部分:Map(映射)和Reduce(归纳)。…
【Python百宝箱】数据科学的黄金三角:数据挖掘和聚类
数据之舞:Python数据科学库横扫全场
前言
在当今数据驱动的时代,Python成为数据科学家和分析师的首选工具之一。本文将介绍一系列强大的Python库,涵盖了数据处理、可视化、机器学习和自然语言处理等领域。无论你是初学者还是经验丰富的数据…

大数据----基于sogou.500w.utf8数据的MapReduce编程
目录 一、前言二、准备数据三、编程实现3.1、统计出搜索过包含有“仙剑奇侠传”内容的UID及搜索关键字记录3.2、统计rank<3并且order>2的所有UID及数量3.3、上午7-9点之间,搜索过“赶集网”的用户UID3.4、通过Rank:点击排名 对数据进行排序 四、参…
MapReduce-Join多种应用
Join多种应用
Reduce Join
Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。Reduce端的主要工作:在Reduce端以连…
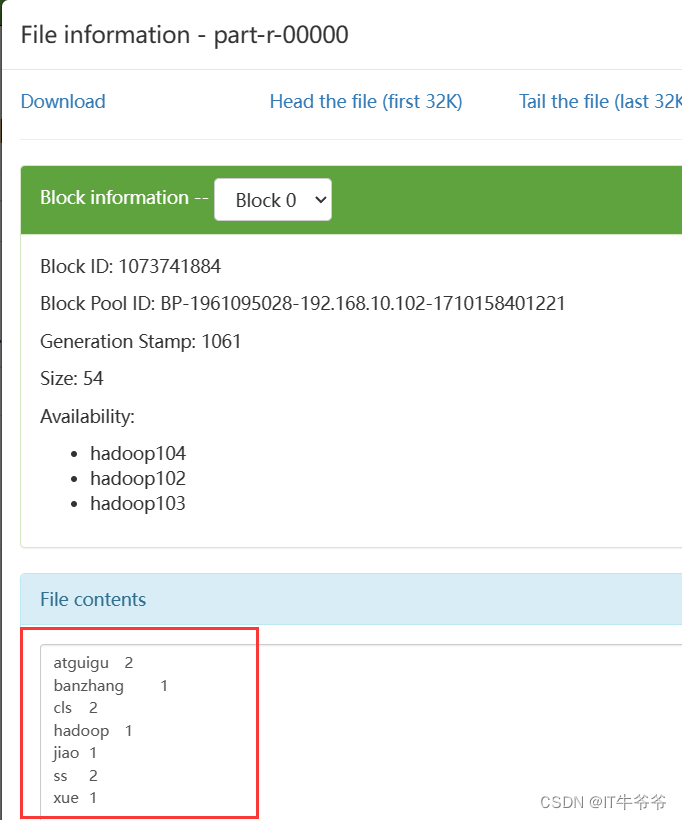
WordCount案例实操
文章目录 需求分析代码环境准备编写Mapper类编写Reducer类编写Driver驱动类本地运行注意事项运行结果 提交到集群测试 需求分析
在给定的文本文件中统计输出每一个单词出现的总次数 期望输出数据: atxiaoyu 2 banzhang 1 cls 2 hadoop 1 jiao 1 ss 2 xue 1
实现过…

通过mapreduce程序统计旅游订单(wordcount升级版)
通过mapreduce程序统计旅游订单(wordcount升级版)
本文将结合一个实际的MapReduce程序案例,探讨如何通过分析旅游产品的预订数据来揭示消费者的偏好。
程序概览
首先,让我们来看一下这个MapReduce程序的核心代码。这个程序的目…
深入理解MapReduce:从Map到Reduce的工作原理解析
当谈到分布式计算和大数据处理时,MapReduce是一个经典的范例。它是一种编程模型和处理框架,用于在大规模数据集上并行运行计算任务。MapReduce包含三个主要阶段:Map、Shuffle 和 Reduce。 **
Map 阶段
** Map 阶段是 MapReduce 的第一步&am…
【云开发笔记No.30】弹性MapReduce
弹性MapReduce的定义
弹性MapReduce(EMR)是一种基于云原生技术和泛Hadoop生态开源技术的安全、低成本、高可靠的开源大数据平台。它结合了云计算的弹性和MapReduce的分布式计算能力,使得大数据处理变得更加高效和灵活。通过EMR,用…
mapreduce--流量统计
FlowBean
package com.atguigu.mr.flow;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class FlowBean implements Writable {
// 流量private long upFlow;private long downFlow;priva…

2023.11.19 hadoop之MapReduce
目录
1.简介
2.分布式计算框架-Map Reduce
3.mapreduce的步骤
4.MapReduce底层原理
map阶段
shuffle阶段
reduce阶段 1.简介
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是…

【Windows下】Eclipse 尝试 Mapreduce 编程
文章目录 配置环境环境准备连接 Hadoop查看 hadoop 文件 导入 Hadoop 包创建 MapReduce 项目测试 Mapreduce 编程代码注意事项常见报错 配置环境
环境准备
本次实验使用的 Hadoop 为 2.7.7 版本,实验可能会用到的文件
百度网盘链接:https://pan.baidu…
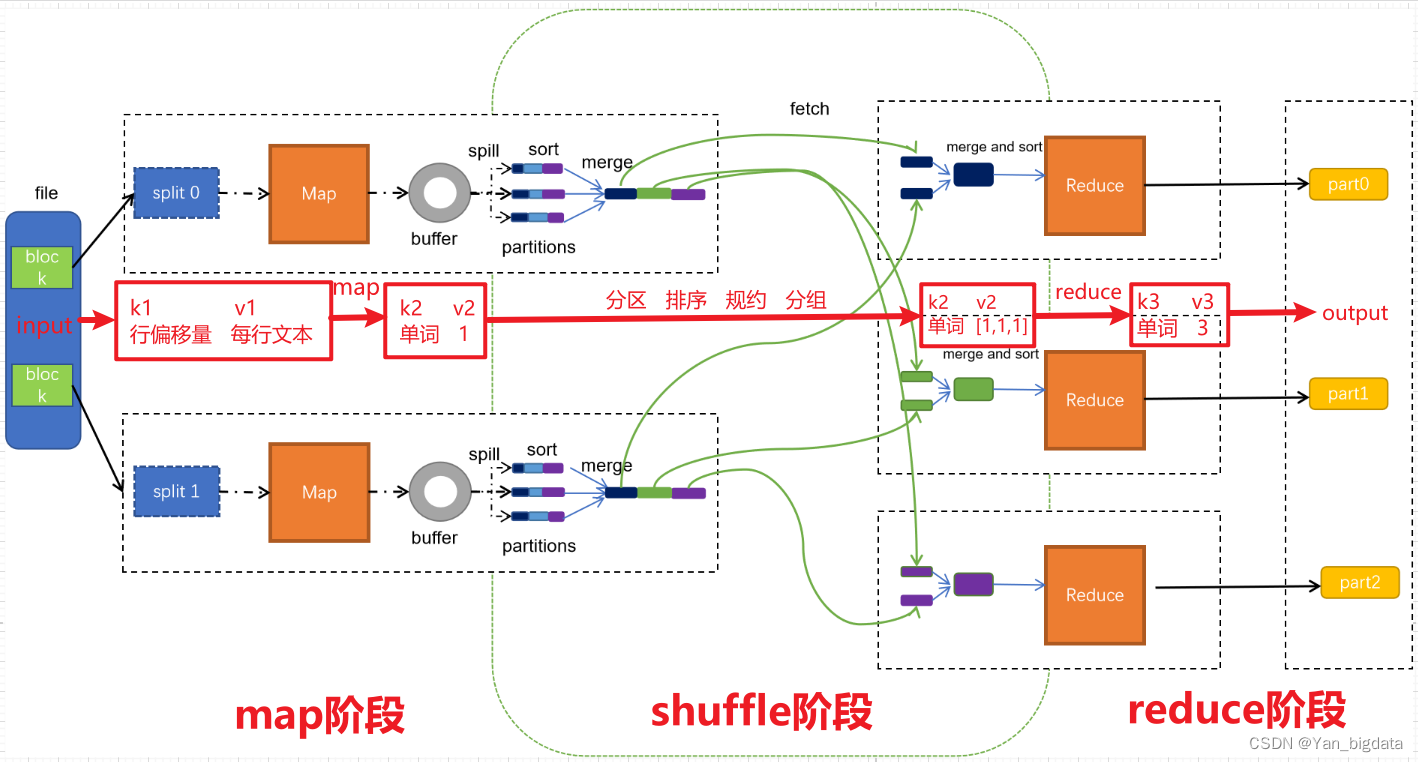
Hadoop进阶学习---MapReduce分布式计算架构
1.单词统计流程(文字简单描述) 已知文件内容: hadoop hive hadoop spark hive flink hive linux hive mysql 计算每个单词出现的次数 2.MR底层计算原理[重点] MAP阶段
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下Split s…
MapReduce模拟统计每日车流量-解决方案
MapReduce模拟统计每日车流量-解决方案 1.Map阶段:将原始数据分割成若干个小块,每个小块由一个Map任务处理。Map任务将小块中的每个数据项映射成为一个键值对,其中键为时间戳,值为车流量。2.Shuffle阶段:将Map任务输出…
Maven构建MapReduce程序上传至虚拟机运行找不到jdbc.Driver
问题前置: Maven构建MapReduce程序, pom中已经写入jdbc驱动, 上传至虚拟机运行扔找不到jdbc.Driver, 具体报错:java.lang.RuntimeException: java.lang.ClassNotFoundException: com.mysql.jdbc.Driver 第一步:确认pom…

【大数据存储与处理】实验六 MongoDB 聚合函数 MapReduce
实验六 MongoDB 聚合函数 MapReduce 【实验目的】: 1. 掌握 mongodb 的 mapreduce 聚合函数。 【实验内容与要求】: MongoDB 有两种聚合函数:aggregate 与 mapreduce mapreduce 函数提供的是 mapreduce(编程模型)…
![[yarn]yarn异常](https://img-blog.csdnimg.cn/85e5428f7eff4ff18014e31c02af55a6.png)
[yarn]yarn异常
一、运行一下算圆周率的测试代码,看下报错
cd /home/data_warehouse/module/hadoop-3.1.3/share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-3.1.3.jar pi 1000 1000
后面2个数字参数的含义: 第1个1000指的是要运行1000次map任务 …
6.824-Lab 1: MapReduce
lab1链接:6.824 Lab 1: MapReduce (mit.edu)
介绍
在这个实验中,你将构建一个MapReduce系统。你将实现一个工作进程(worker process),调用应用程序的Map和Reduce函数,并处理文件的读写,以及一…